Inline Table
-
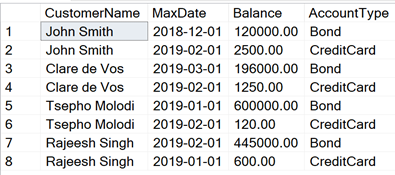
Please assist creating an inline Table Valued Function. Output should look like this: https://drive.google.com/file/d/1NlImnhE35Zattw4KKH7gVrQcGcMsSlRJ/view?usp=drivesdk
Data
https://drive.google.com/file/d/1mkBA8Uc8tZjhWdzqGaxLAPnNoqpBSfMZ/view?usp=drivesdk
-
Rather than posting links, which some people (including me) might choose not to open, can you post using text (for DDL and data) and images (showing desired results).
-

CREATE TABLE [dbo].[CreditCardBalance](
[ID] [int] NOT NULL,
[CustomerID] [int] NULL,
[BalanceDate] [date] NULL,
[Balance] [decimal](18, 2) NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[BondBalance](
[ID] [int] NOT NULL,
[CustomerID] [int] NULL,
[BalanceDate] [date] NULL,
[Balance] [decimal](18, 2) NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Customer](
[ID] [int] NOT NULL,
[CustomerName] [varchar](50) NULL
) ON [PRIMARY]
GO
INSERT INTO Customer VALUES (1, 'John Smith')
INSERT INTO Customer VALUES (2,'Clare de Vos')
INSERT INTO Customer VALUES (3,'Tsepho Molodi')
INSERT INTO Customer VALUES (4,'Rajeesh Singh')
GO
INSERT INTO CreditCardBalance VALUES (1,1,'1/jan/2019',2000)
INSERT INTO CreditCardBalance VALUES (2,1,'1/feb/2019',2500)
INSERT INTO CreditCardBalance VALUES (3,2,'1/feb/2019',1250)
INSERT INTO CreditCardBalance VALUES (4,3,'1/jan/2019',800)
INSERT INTO CreditCardBalance VALUES (5,3,'1/feb/2019',120)
INSERT INTO CreditCardBalance VALUES (6,4,'1/jan/2019',600)
GO
INSERT INTO BondBalance VALUES (1,1,'1/dec/2018',120000)
INSERT INTO BondBalance VALUES (2,2,'1/jan/2019',200000)
INSERT INTO BondBalance VALUES (3,2,'1/feb/2019',198000)
INSERT INTO BondBalance VALUES (4,2,'1/mar/2019',196000)
INSERT INTO BondBalance VALUES (5,3,'1/jan/2019',600000)
INSERT INTO BondBalance VALUES (6,4,'1/jan/2019',450000)
INSERT INTO BondBalance VALUES (7,4,'1/feb/2019',445000)
GO
-
Will your function have any parameters?
-
Please provide a code with a sample parameter and one without?
- yrstruly wrote:
Please provide a code with a sample parameter and one without?
And what should that parameter do? What is the actual logic here? You've just given data and told us to write you the solution without a description; so are we free to just guess what the logic is?
You say you need assistance, what is it you need assistance on with creating the function? Where did you get stuck? If you show us what you have already written, we can show you where you where you went wrong.
Thom~
Excuse my typos and sometimes awful grammar. My fingers work faster than my brain does.
Larnu.uk -
;WITH CTE AS
(
SELECT c.Id CustomerId, c.CustomerName, b.BalanceDate MaxDate, b.Balance, 'Bond' AccountType
FROM [dbo].[Customer] c
CROSS APPLY(SELECT TOP(1) *
FROM [dbo].[BondBalance] b
WHERE b.CustomerID = c.ID
ORDER BY b.BalanceDate DESC) b
UNION ALL
SELECT c.Id CustomerId, c.CustomerName, b.BalanceDate MaxDate, b.Balance, 'CreditBalance' AccountType
FROM [dbo].[Customer] c
CROSS APPLY(SELECT TOP(1) *
FROM [dbo].[CreditCardBalance] b
WHERE b.CustomerID = c.ID
ORDER BY b.BalanceDate DESC) b
)
SELECT x.CustomerName,
x.MaxDate,
x.Balance,
x.AccountType
FROM CTE x
ORDER BY x.CustomerId, x.AccountTypeYou don't need a table valued function. A view will do the job:
GO
CREATE VIEW LatestBalance AS
SELECT c.Id CustomerId, c.CustomerName, b.BalanceDate MaxDate, b.Balance, 'Bond' AccountType
FROM [dbo].[Customer] c
CROSS APPLY(SELECT TOP(1) *
FROM [dbo].[BondBalance] b
WHERE b.CustomerID = c.ID
ORDER BY b.BalanceDate DESC) b
UNION ALL
SELECT c.Id CustomerId, c.CustomerName, b.BalanceDate MaxDate, b.Balance, 'CreditBalance' AccountType
FROM [dbo].[Customer] c
CROSS APPLY(SELECT TOP(1) *
FROM [dbo].[CreditCardBalance] b
WHERE b.CustomerID = c.ID
ORDER BY b.BalanceDate DESC) b
GO -
Thank You
- Jonathan AC Roberts wrote:
You don't need a table valued function. A view will do the job:
"It Depends". I've found that a whole lot of folks end up writing code that causes all of the rows in a view to first materialize and then later be filtered by the code using it. That usually be prevented if you use an iTVF instead of a view.
It doesn't mean that you should avoid views (although that's my normal recommendation because people screw up their usage so badly). The use of an iTVF is an alternative if you need a bit more control.
Of course, you also have to be careful with those for other reasons. Like I said, "It Depends". 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:Jonathan AC Roberts wrote:
You don't need a table valued function. A view will do the job:
"It Depends". I've found that a whole lot of folks end up writing code that causes all of the rows in a view to first materialize and then later be filtered by the code using it. That usually be prevented if you use an iTVF instead of a view.
It doesn't mean that you should avoid views (although that's my normal recommendation because people screw up their usage so badly). The use of an iTVF is an alternative if you need a bit more control.
Of course, you also have to be careful with those for other reasons. Like I said, "It Depends". 😀
Yes, I can see your point, with an iTVF you could put the filter columns that you wouldn't be able to do with a view. For example, you could filter on CustomerId in each of the UNIONED statements. But it's also possible/probable the optimiser will be able to do this without it needing to build the entire query results from the table. It's something that would need to be tested.
- Jonathan AC Roberts wrote:Jeff Moden wrote:Jonathan AC Roberts wrote:
You don't need a table valued function. A view will do the job:
"It Depends". I've found that a whole lot of folks end up writing code that causes all of the rows in a view to first materialize and then later be filtered by the code using it. That usually be prevented if you use an iTVF instead of a view.
It doesn't mean that you should avoid views (although that's my normal recommendation because people screw up their usage so badly). The use of an iTVF is an alternative if you need a bit more control.
Of course, you also have to be careful with those for other reasons. Like I said, "It Depends". 😀
Yes, I can see your point, with an iTVF you could put the filter columns that you wouldn't be able to do with a view. For example, you could filter on CustomerId in each of the UNIONED statements. But it's also possible/probable the optimiser will be able to do this without it needing to build the entire query results from the table. It's something that would need to be tested.
Yes. In fact, I sometimes refer to iTVFs as "Parameterized Views" As you say, the optimizer does this same sort of things on views if people refer to the view correctly in joins. Of course, the same issue can happen iTVFs. Totally agreed that it's something that needs to be tested. If a view doesn't work out, try an iTVF. Vice versa holds true as well. The 3rd option is sometimes to actually inline the code itself.
Heh... as a bit of a sidebar, a part of why I'm so keenly aware of issues in this area is because a lot of the people I work with think that "set base" always means "everything in one query". Sometimes the CTE chains are totally ridiculous in length not to mention that one or more "heavy" CTEs are called in the later part of the chain many times. The concept of "Divide'n'Conquer" (also known as "eating the elephant one bite at a time" 😀 ) doesn't enter their heads even though they've been told that every time you reference a CTE, it is totally re-executed again just as if you were calling a View multiple times. It's a real problem in a lot of shops... people treat CTEs, Views, etc, as if they were a table.
Of course, YOU already know that... I'm just writing that out for anyone that might be reading this that doesn't know.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:Jonathan AC Roberts wrote:Jeff Moden wrote:Jonathan AC Roberts wrote:
You don't need a table valued function. A view will do the job:
"It Depends". I've found that a whole lot of folks end up writing code that causes all of the rows in a view to first materialize and then later be filtered by the code using it. That usually be prevented if you use an iTVF instead of a view.
It doesn't mean that you should avoid views (although that's my normal recommendation because people screw up their usage so badly). The use of an iTVF is an alternative if you need a bit more control.
Of course, you also have to be careful with those for other reasons. Like I said, "It Depends". 😀
Yes, I can see your point, with an iTVF you could put the filter columns that you wouldn't be able to do with a view. For example, you could filter on CustomerId in each of the UNIONED statements. But it's also possible/probable the optimiser will be able to do this without it needing to build the entire query results from the table. It's something that would need to be tested.
Yes. In fact, I sometimes refer to iTVFs as "Parameterized Views" As you say, the optimizer does this same sort of things on views if people refer to the view correctly in joins. Of course, the same issue can happen iTVFs. Totally agreed that it's something that needs to be tested. If a view doesn't work out, try an iTVF. Vice versa holds true as well. The 3rd option is sometimes to actually inline the code itself.
Heh... as a bit of a sidebar, a part of why I'm so keenly aware of issues in this area is because a lot of the people I work with think that "set base" always means "everything in one query". Sometimes the CTE chains are totally ridiculous in length not to mention that one or more "heavy" CTEs are called in the later part of the chain many times. The concept of "Divide'n'Conquer" (also known as "eating the elephant one bite at a time" 😀 ) doesn't enter their heads even though they've been told that every time you reference a CTE, it is totally re-executed again just as if you were calling a View multiple times. It's a real problem in a lot of shops... people treat CTEs, Views, etc, as if they were a table.
Of course, YOU already know that... I'm just writing that out for anyone that might be reading this that doesn't know.
Yes, I know about the re-executing of the inside of a CTE. You'd think the optimiser team at Microsoft would be working on making this execute just once when possible.
It's also the case when you refer to the result of a cross apply multiple times the calculations inside of the cross apply are expanded multiple times.
- Jonathan AC Roberts wrote:
It's also the case when you refer to the result of a cross apply multiple times the calculations inside of the cross apply are expanded multiple times.
I agree that the whole purpose of a CROSS APPLY is to be executed for each row of the "joined" table. Is that what you mean?
The reason I ask is if you Cross Apply something like fnTally to a single row table, the function is not called for every "t.N" reference that you have in the Select List.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:Jonathan AC Roberts wrote:
It's also the case when you refer to the result of a cross apply multiple times the calculations inside of the cross apply are expanded multiple times.
I agree that the whole purpose of a CROSS APPLY is to be executed for each row of the "joined" table. Is that what you mean?
The reason I ask is if you Cross Apply something like fnTally to a single row table, the function is not called for every "t.N" reference that you have in the Select List.
I meant the expanding of the expressions inside the cross apply. I found this out from trying to answer one a question in SQLServerCentral see: https://www.sqlservercentral.com/forums/topic/split-comma-delimited-field#post-2011014
If you execute the query below with the execution plan and look at the [Defined Values] in the "Compute Scalar" icon, you will see it has expanded out all the function calls in the cross applies above t12 into a very very long expression.
;WITH CTE AS (
SELECT *
FROM (VALUES ('qwe,ert,dfg,xcvb,fghj,tyu,gjk,tyu,dfg,ey,dfg,fgh,'),
('qwe,ert,dfkjhgkg,xcvb,fghj,tyu,gjk,tyu,dfg,ey,dfgfgh,213,dfg,yuk,dfg,sdf,'),
('qwe,er khjgt,dfg,xcvb,')) T(C)
)
select --T.C,Col1,Col2 ,Col3,Col4,Col5,Col6,Col7,Col8,Col9,Col10,Col11,
Col12
--,Col13
from CTE T
cross apply (values (CHARINDEX(',',T.C))) AS c1(CommaPos)
cross apply (values (LEFT(T.C,ABS(c1.CommaPos-1)),SUBSTRING(T.C,c1.CommaPos+1,8000))) t1(Col1,RHS)
cross apply (values (CHARINDEX(',',t1.RHS))) c2(CommaPos)
cross apply (values (LEFT(t1.RHS,ABS(c2.CommaPos-1)),SUBSTRING(t1.RHS,c2.CommaPos+1,8000))) t2(Col2,RHS)
cross apply (values (CHARINDEX(',',t2.RHS))) c3(CommaPos)
cross apply (values (LEFT(t2.RHS,ABS(c3.CommaPos-1)),SUBSTRING(t2.RHS,c3.CommaPos+1,8000))) t3(Col3,RHS)
cross apply (values (CHARINDEX(',',t3.RHS))) c4(CommaPos)
cross apply (values (LEFT(t3.RHS,ABS(c4.CommaPos-1)),SUBSTRING(t3.RHS,c4.CommaPos+1,8000))) t4(Col4,RHS)
cross apply (values (CHARINDEX(',',t4.RHS))) c5(CommaPos)
cross apply (values (LEFT(t4.RHS,ABS(c5.CommaPos-1)),SUBSTRING(t4.RHS,c5.CommaPos+1,8000))) t5(Col5,RHS)
cross apply (values (CHARINDEX(',',t5.RHS))) c6(CommaPos)
cross apply (values (LEFT(t5.RHS,ABS(c6.CommaPos-1)),SUBSTRING(t5.RHS,c6.CommaPos+1,8000))) t6(Col6,RHS)
cross apply (values (CHARINDEX(',',t6.RHS))) c7(CommaPos)
cross apply (values (LEFT(t6.RHS,ABS(c7.CommaPos-1)),SUBSTRING(t6.RHS,c7.CommaPos+1,8000))) t7(Col7,RHS)
cross apply (values (CHARINDEX(',',t7.RHS))) c8(CommaPos)
cross apply (values (LEFT(t7.RHS,ABS(c8.CommaPos-1)),SUBSTRING(t7.RHS,c8.CommaPos+1,8000))) t8(Col8,RHS)
cross apply (values (CHARINDEX(',',t8.RHS))) c9(CommaPos)
cross apply (values (LEFT(t8.RHS,ABS(c9.CommaPos-1)),SUBSTRING(t8.RHS,c9.CommaPos+1,8000))) t9(Col9,RHS)
cross apply (values (CHARINDEX(',',t9.RHS))) c10(CommaPos)
cross apply (values (LEFT(t9.RHS,ABS(c10.CommaPos-1)),SUBSTRING(t9.RHS,c10.CommaPos+1,8000))) t10(Col10,RHS)
cross apply (values (CHARINDEX(',',t10.RHS))) c11(CommaPos)
cross apply (values (LEFT(t10.RHS,ABS(c11.CommaPos-1)),SUBSTRING(t10.RHS,c11.CommaPos+1,8000))) t11(Col11,RHS)
cross apply (values (CHARINDEX(',',t11.RHS))) c12(CommaPos)
cross apply (values (LEFT(t11.RHS,ABS(c12.CommaPos-1)),SUBSTRING(t11.RHS,c12.CommaPos+1,8000))) t12(Col12,RHS)
--cross apply (values (CHARINDEX(',',t12.RHS))) c13(CommaPos)
--cross apply (values (LEFT(t12.RHS,ABS(c13.CommaPos-1)),SUBSTRING(t12.RHS,c13.CommaPos+1,8000))) t13(Col13,RHS)If you try to execute it with all the column including t13 uncommented and also try to access all columns (query below) then you get error:
Msg 8632, Level 17, State 2, Line 1
Internal error: An expression services limit has been reached. Please look for potentially complex expressions in your query, and try to simplify them.;WITH CTE AS (
SELECT *
FROM (VALUES ('qwe,ert,dfg,xcvb,fghj,tyu,gjk,tyu,dfg,ey,dfg,fgh,'),
('qwe,ert,dfkjhgkg,xcvb,fghj,tyu,gjk,tyu,dfg,ey,dfgfgh,213,dfg,yuk,dfg,sdf,'),
('qwe,er khjgt,dfg,xcvb,')) T(C)
)
select T.C,Col1,Col2 ,Col3,Col4,Col5,Col6,Col7,Col8,Col9,Col10,Col11,
Col12
,Col13
from CTE T
cross apply (values (CHARINDEX(',',T.C))) AS c1(CommaPos)
cross apply (values (LEFT(T.C,ABS(c1.CommaPos-1)),SUBSTRING(T.C,c1.CommaPos+1,8000))) t1(Col1,RHS)
cross apply (values (CHARINDEX(',',t1.RHS))) c2(CommaPos)
cross apply (values (LEFT(t1.RHS,ABS(c2.CommaPos-1)),SUBSTRING(t1.RHS,c2.CommaPos+1,8000))) t2(Col2,RHS)
cross apply (values (CHARINDEX(',',t2.RHS))) c3(CommaPos)
cross apply (values (LEFT(t2.RHS,ABS(c3.CommaPos-1)),SUBSTRING(t2.RHS,c3.CommaPos+1,8000))) t3(Col3,RHS)
cross apply (values (CHARINDEX(',',t3.RHS))) c4(CommaPos)
cross apply (values (LEFT(t3.RHS,ABS(c4.CommaPos-1)),SUBSTRING(t3.RHS,c4.CommaPos+1,8000))) t4(Col4,RHS)
cross apply (values (CHARINDEX(',',t4.RHS))) c5(CommaPos)
cross apply (values (LEFT(t4.RHS,ABS(c5.CommaPos-1)),SUBSTRING(t4.RHS,c5.CommaPos+1,8000))) t5(Col5,RHS)
cross apply (values (CHARINDEX(',',t5.RHS))) c6(CommaPos)
cross apply (values (LEFT(t5.RHS,ABS(c6.CommaPos-1)),SUBSTRING(t5.RHS,c6.CommaPos+1,8000))) t6(Col6,RHS)
cross apply (values (CHARINDEX(',',t6.RHS))) c7(CommaPos)
cross apply (values (LEFT(t6.RHS,ABS(c7.CommaPos-1)),SUBSTRING(t6.RHS,c7.CommaPos+1,8000))) t7(Col7,RHS)
cross apply (values (CHARINDEX(',',t7.RHS))) c8(CommaPos)
cross apply (values (LEFT(t7.RHS,ABS(c8.CommaPos-1)),SUBSTRING(t7.RHS,c8.CommaPos+1,8000))) t8(Col8,RHS)
cross apply (values (CHARINDEX(',',t8.RHS))) c9(CommaPos)
cross apply (values (LEFT(t8.RHS,ABS(c9.CommaPos-1)),SUBSTRING(t8.RHS,c9.CommaPos+1,8000))) t9(Col9,RHS)
cross apply (values (CHARINDEX(',',t9.RHS))) c10(CommaPos)
cross apply (values (LEFT(t9.RHS,ABS(c10.CommaPos-1)),SUBSTRING(t9.RHS,c10.CommaPos+1,8000))) t10(Col10,RHS)
cross apply (values (CHARINDEX(',',t10.RHS))) c11(CommaPos)
cross apply (values (LEFT(t10.RHS,ABS(c11.CommaPos-1)),SUBSTRING(t10.RHS,c11.CommaPos+1,8000))) t11(Col11,RHS)
cross apply (values (CHARINDEX(',',t11.RHS))) c12(CommaPos)
cross apply (values (LEFT(t11.RHS,ABS(c12.CommaPos-1)),SUBSTRING(t11.RHS,c12.CommaPos+1,8000))) t12(Col12,RHS)
cross apply (values (CHARINDEX(',',t12.RHS))) c13(CommaPos)
cross apply (values (LEFT(t12.RHS,ABS(c13.CommaPos-1)),SUBSTRING(t12.RHS,c13.CommaPos+1,8000))) t13(Col13,RHS) -
Well - you can avoid this issue using a slightly different approach. I would create an iTVF to split the elements and then cross apply to that function.
CREATE Function [dbo].[fnSplitString_12Columns] (
@pString varchar(8000)
, @pDelimiter char(1)
)
Returns Table
With schemabinding
As
Return
Select InputString = @pString -- v.inputString
, p01_pos = p01.pos
, p02_pos = p02.pos
, p03_pos = p03.pos
, p04_pos = p04.pos
, p05_pos = p05.pos
, p06_pos = p06.pos
, p07_pos = p07.pos
, p08_pos = p08.pos
, p09_pos = p09.pos
, p10_pos = p10.pos
, p11_pos = p11.pos
, p12_pos = p12.pos
, col_01 = ltrim(substring(v.inputString, 1, p01.pos - 2))
, col_02 = ltrim(substring(v.inputString, p01.pos, p02.pos - p01.pos - 1))
, col_03 = ltrim(substring(v.inputString, p02.pos, p03.pos - p02.pos - 1))
, col_04 = ltrim(substring(v.inputString, p03.pos, p04.pos - p03.pos - 1))
, col_05 = ltrim(substring(v.inputString, p04.pos, p05.pos - p04.pos - 1))
, col_06 = ltrim(substring(v.inputString, p05.pos, p06.pos - p05.pos - 1))
, col_07 = ltrim(substring(v.inputString, p06.pos, p07.pos - p06.pos - 1))
, col_08 = ltrim(substring(v.inputString, p07.pos, p08.pos - p07.pos - 1))
, col_09 = ltrim(substring(v.inputString, p08.pos, p09.pos - p08.pos - 1))
, col_10 = ltrim(substring(v.inputString, p09.pos, p10.pos - p09.pos - 1))
, col_11 = ltrim(substring(v.inputString, p10.pos, p11.pos - p10.pos - 1))
, col_12 = ltrim(substring(v.inputString, p11.pos, p12.pos - p11.pos - 1))
From (Values (concat(@pString, replicate(@pDelimiter, 12)))) As v(inputString)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, 1) + 1)) As p01(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p01.pos) + 1)) As p02(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p02.pos) + 1)) As p03(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p03.pos) + 1)) As p04(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p04.pos) + 1)) As p05(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p05.pos) + 1)) As p06(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p06.pos) + 1)) As p07(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p07.pos) + 1)) As p08(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p08.pos) + 1)) As p09(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p09.pos) + 1)) As p10(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p10.pos) + 1)) As p11(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p11.pos) + 1)) As p12(pos);
GOThis only goes to 12 - but can be extended well past your 13 columns. I tested with 20 columns with no issues.
With that said, yes - SQL expands each of the cross applies that are used into the final scalar on output. But - written as above it only expands to the level it needs, so if you reference col_01 it will only incorporate the first cross apply in the function.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs
Viewing 15 posts - 1 through 15 (of 19 total)
You must be logged in to reply to this topic. Login to reply