indexes cleanup
-
Hi All,
Recently we are having issues with disk space requirements.
After monitoring db file growth for a week,we found the index file is growing rapidly (100gb-500gb). Other data files and log file space usage is stable. So, we wanted to clean up some of the unused indexes. So, what is the criteria.
Based on my knowledge, we can disable those indexes which have low reads vs high writes. I need more suggestions on how to go about cleaning up some of those unused indexes. I use below glenn berry DMV little modified to find out unused indexes.
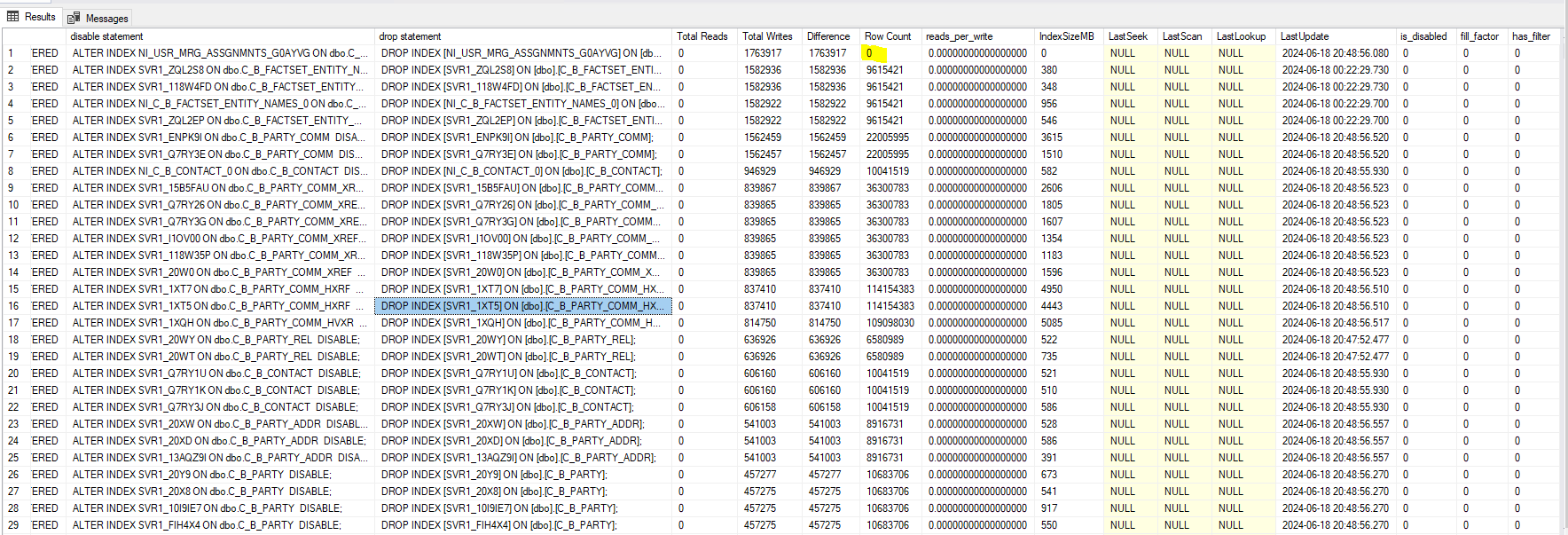
Attaching the excel sheet which contains index usage stats data. please suggest some solutions.
Note: Application team has ddl_admin permissions to create objects. As per vendor database specifications, they need those permissions.
Questions :
1. Can we straight away disable those indexes whose reads = 0 but writes are high ?
2. When to disable when to drop those unused indexes?
3. Our index maintenance jobs runs over the weekend. When to disable or drop to have clean stats? by Friday?
4. Do we need to collect more data before disabling or dropping?
5. Some of the indexes have 0 Rowcount but i can see writes in that indexes , reads = 0 , so what does it mean?
PFA screenshot.

Regards,
Sam
-
whats changed recently, has someone created new indexes by any chance?
-----------------------------------------------------------------------------------------------------------
"Ya can't make an omelette without breaking just a few eggs" 😉
-
This is a tough process. First up, testing is your buddy. Plan to test your queries, a lot, before you just disable indexes willy nilly. Next, small changes. Only take one, or only a very few, indexes offline at a time. You want to know when something goes south what you did so you can undo it. Next, make darned sure you've got good query metrics. Minimum, Query Store, but probably getting more detailed behaviors using Extended Events is the way to go. Finally, unique indexes are special. They may be "used" without involving reads and scans. The optimizer can take advantage of the fact that certain values are limited when it makes the choices it makes. So be double cautious around unique indexes.
What you can't do is blindly accept the index usage data. It's subject to all sorts of interference, made even worse in Azure (you can fail between the three underlying instances without any external notice, which resets those values). So yes, use that information to drive your choices, but please, couple it with a careful process that involves good monitoring and cautious testing. Otherwise, you may shoot your system right in the face. I'd avoid that if I could.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
This is a tough process. First up, testing is your buddy. Plan to test your queries, a lot, before you just disable indexes willy nilly. Next, small changes. Only take one, or only a very few, indexes offline at a time. You want to know when something goes south what you did so you can undo it. Next, make darned sure you've got good query metrics. Minimum, Query Store, but probably getting more detailed behaviors using Extended Events is the way to go. Finally, unique indexes are special. They may be "used" without involving reads and scans. The optimizer can take advantage of the fact that certain values are limited when it makes the choices it makes. So be double cautious around unique indexes.
What you can't do is blindly accept the index usage data. It's subject to all sorts of interference, made even worse in Azure (you can fail between the three underlying instances without any external notice, which resets those values). So yes, use that information to drive your choices, but please, couple it with a careful process that involves good monitoring and cautious testing. Otherwise, you may shoot your system right in the face. I'd avoid that if I could.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
Thank you Grant sir. All I can sense is, this has to be carefully dealt with a proper index performance tuner or consultant.
Just want to ask, is there any easy pickings from the index usage stats which can straight away disabled ( low hanging fruits ) without causing any side-effects to database performance [or] do we need to do home work such as tables which are taking most disk space and then check what indexes laid down on those specific tables and what application queries are using against tables and then try disabling 1-2 indexes based on zero selects but heavy writes and then monitor performance and disk space?
-
Another 3 followup questions
1 . When do we see index size is greater than actual data size of the table? is that because of creation of too many non-clustered duplicate indexes ?
2. when u see data as below what can I infer?
reads = 0
writes = 10000
rowcount = 0
3. is there a query through I can sure shot disable non-clustered unused indexes excluding the unique primary key indexes and just get some free space out straight away?
-
as mentioned on this, and other of your threads, the index usage gets reset with every restart/failover of the server (and likely also as part of a specific db restore/offline operation) - so unless you are persisting this information on your own tables at a point in time, running every day for example, and then using the different point in times values to come up with the ACTUAL usage since you started logging into that table, your analysis is most likely incorrect and should not be used for any decision making.
as a very short example
21-01-2024 - indexa - rows updated:200
server restart
22-01-2024 - indexa - rows updated:10
23-01-2024 - indexa - rows updated:2000
server restart
24-01-2024 - indexa - rows updated:0
running index usaged on 24/01 gives you a 0 rows updated - so you may consider index not used - but the true value to consider is 200 + 2000 of the prior saved reports.
to be more correct the history table should store the instance starttime + report time + other details, and your analysis should be adding up the values related to the max report time within a instance start time and add those up for a true(ish) picture of usage
-
If you need extra disk space extend the disks
-----------------------------------------------------------------------------------------------------------
"Ya can't make an omelette without breaking just a few eggs" 😉
- vsamantha35 wrote:
Thank you Grant sir. All I can sense is, this has to be carefully dealt with a proper index performance tuner or consultant.
Just want to ask, is there any easy pickings from the index usage stats which can straight away disabled ( low hanging fruits ) without causing any side-effects to database performance [or] do we need to do home work such as tables which are taking most disk space and then check what indexes laid down on those specific tables and what application queries are using against tables and then try disabling 1-2 indexes based on zero selects but heavy writes and then monitor performance and disk space?
No. Not really. Everything is a test. And, you need to account for business cycles. For example, a given index may not be used for a year, but then, annual renewal time, and that index is the most important one in the database for about two weeks. There is no 100% certainty. There's just metrics and testing. Gather the metrics, make a change, do the tests, validate the metrics. Over & over.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning - vsamantha35 wrote:
Another 3 followup questions
1 . When do we see index size is greater than actual data size of the table? is that because of creation of too many non-clustered duplicate indexes ?
Based on what measure? Pages or actual data? Pages, it's down to fragmentation in one and not the other. Actual data... I suppose I could envision a scenario where you index all the data in a clustered index and in a nonclustered index... maybe the nonclustered would be bigger... but I don't think so. Where are you seeing this?
2. when u see data as below what can I infer?
reads = 0
writes = 10000
rowcount = 0
Not sure. Truncation?
3. is there a query through I can sure shot disable non-clustered unused indexes excluding the unique primary key indexes and just get some free space out straight away?
No.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
I know, we always want a short cut. I sure do. Let me solve the problem with zero to minimum effort so it's done right now. Easy peasy. I get it. I fully understand.
There isn't that kind of solution here. Sorry. It just doesn't exist. This is the moment you start to earn your paycheck. Capture good query metrics, make a change on the indexes, gather metrics again. Deal with the results, positive or negative. Do it again. Keep going. There is 100% not a magic switch that we're hiding from you. This is a hard situation that requires work. Period. Again, apologies, but there it is.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
Hey there, Sam...
I took a look at your index spreadsheet. That's a good thing but it's missing some critical information...
- Add an IsUnique column to identify if the index is unique or not. Constraints won't do it here. You have to get the info from the index itself.
- Add a "CompressionType" column to identity "None", "Row", or "Page" compression. Get that from sys.partitions.
- Add the following columns having to do with fragmentation of the indexes (from sys.dm_db_index_physical_stats() with the "sampled" mode)...
- index_type_desc
- alloc_unit_type_desc
- index_level
- avg_fragmentation_in_percent
- avg_page_space_used_in_percent
- List the datatype of the first key column in every index..
The spreadsheet you included says that a restart occurred only 4 days earlier... that's not good enough to tell if an index is read from or not. You haven't even given it enough time for weekly reports to run.
My recommendation is to temporary stop doing any index maintenance and wait until after the 2nd Monday of next month. In the mean time, you can rebuild statistics instead of doing the index maintenance. You might want to also measure performance during this time to find out that your index maintenance isn't actually helping anything. 😉
Once you've added the columns of data I've suggested to your spreadsheet and have waited for the amount of time I outline above to pass, we can take another look and make some fairly sweeping recommendations for which indexes to initially disable. We also be able to make some more intelligent educated guesses about which indexes to do any maintenance on.
Ping back with a new/upgraded spreadsheet when the recommended amount of time has passed.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Stats are more important that index maint, indexes in sql server are fairly robust as long as the stats are good
-----------------------------------------------------------------------------------------------------------
"Ya can't make an omelette without breaking just a few eggs" 😉
- Jeff Moden wrote:
Hey there, Sam...
The spreadsheet you included says that a restart occurred only 4 days earlier... that's not good enough to tell if an index is read from or not. You haven't even given it enough time for weekly reports to run.
Jeff Moden wrote:Hi Sir, I used Glenn berry and Brent ozar's script to pull this data. I did some changes to get the restart date servername etc...
Yeah, its just 4 days data. the server was recently rebooted as part of production patching window.
In the past, I have collected similar information for 60 days. But yes, every weekend index rebuild jobs run. Not sure how accurate the data can help. I am attaching the index data collection file. See if you infer any useful information.
Problem is, I am able to collect that information but I am scared of taking the next steps.
IF OBJECT_ID(N'tempdb..#tmp') IS NOT NULL
BEGIN
DROP TABLE #tmp
END
declare @a varchar(30); --machine restart date
declare @b varchar(30); --sql server restart date
declare @c varchar(30); --no of days since restart
SELECT @a=convert(varchar(30),Dateadd(s, ( ( -1 ) * ( osd.[ms_ticks] / 1000 ) ) , Getdate()),109),
@b=convert(varchar(30),osd.sqlserver_start_time,109)
FROM sys.[dm_os_sys_info] osd;
select @c =RTRIM(CONVERT(CHAR(3),DATEDIFF(second,login_time,getdate())/86400)) + ':' +
RIGHT('00'+RTRIM(CONVERT(CHAR(2),DATEDIFF(second,login_time,getdate())%86400/3600)),2) + ':' +
RIGHT('00'+RTRIM(CONVERT(CHAR(2),DATEDIFF(second,login_time,getdate())%86400%3600/60)),2) + ':' +
RIGHT('00'+RTRIM(CONVERT(CHAR(2),DATEDIFF(second,login_time,getdate())%86400%3600%60)),2)
from sys.sysprocesses --sysprocesses for SQL versions <2000
where spid = 1
-- glenn berry
-- Possible Bad NC Indexes (writes > reads) (Query 67) (Bad NC Indexes)
-- Look for indexes with high numbers of writes and zero or very low numbers of reads
-- Consider your complete workload, and how long your instance has been running
-- Investigate further before dropping an index!
-- consider rowcount > 10000
SELECT
@a AS Machinerestartdatetime,
@b as sqlserver_start_time,
@c AS [Days:Hours:Minutes:Seconds],
getdate() as CaptureDt,
@@servername as ServerName,
DB_NAME() AS DatabaseName,
SCHEMA_NAME(o.schema_id) +'.'+OBJECT_NAME(s.OBJECT_ID) AS TableName,
--SCHEMA_NAME(o.[schema_id]) AS [Schema Name],
--OBJECT_NAME(s.[object_id]) AS [Table Name],
i.index_id,
i.name AS [Index Name],
i.[type_desc],
s.user_seeks + s.user_scans + s.user_lookups AS [Total Reads],
s.user_updates AS [Total Writes],
s.user_updates - (s.user_seeks + s.user_scans + s.user_lookups) AS [Difference],
[Row Count] = (SELECT SUM(p.rows) FROM sys.partitions p WHERE p.index_id = s.index_id AND s.object_id = p.object_id)
, CASE
WHEN s.user_updates < 1 THEN 100
ELSE 1.00 * (s.user_seeks + s.user_scans + s.user_lookups) / s.user_updates
END AS reads_per_write -- The Reads_per_write should be atleast > 50%
,CASE WHEN ps.usedpages > ps.pages THEN (ps.usedpages - ps.pages) ELSE 0
END * 8 / 1024 AS IndexSizeMB
,s.last_user_seek AS LastSeek
,s.last_user_scan AS LastScan
,s.last_user_lookup AS LastLookup
,s.last_user_update AS LastUpdate
,i.is_disabled,
--i.is_hypothetical,
i.fill_factor,
i.has_filter,
'ALTER INDEX '+i.name+' ON '+SCHEMA_NAME(o.schema_id)+'.'+OBJECT_NAME(s.OBJECT_ID)+' DISABLE;' as 'disable statement',
'DROP INDEX ' + QUOTENAME(i.name)+' ON '+QUOTENAME(SCHEMA_NAME(o.schema_id))+'.'+QUOTENAME(OBJECT_NAME(s.object_id))+';' as 'drop statement'
into #tmp
FROM sys.dm_db_index_usage_stats AS s WITH (NOLOCK)
INNER JOIN sys.indexes AS i WITH (NOLOCK)
ON s.[object_id] = i.[object_id]
AND i.index_id = s.index_id
INNER JOIN sys.objects AS o WITH (NOLOCK)
ON i.[object_id] = o.[object_id]
LEFT JOIN (SELECT OBJECT_ID, index_id, SUM(used_page_count) AS usedpages,
SUM(CASE WHEN (index_id < 2)
THEN (in_row_data_page_count + lob_used_page_count + row_overflow_used_page_count)
ELSE lob_used_page_count + row_overflow_used_page_count
END) AS pages
FROM sys.dm_db_partition_stats
GROUP BY object_id, index_id) AS ps ON i.object_id = ps.object_id AND i.index_id = ps.index_id
WHERE OBJECTPROPERTY(s.[object_id],'IsUserTable') = 1
AND s.database_id = DB_ID()
AND s.user_updates > (s.user_seeks + s.user_scans + s.user_lookups)
AND i.index_id > 1 AND i.[type_desc] = N'NONCLUSTERED'
AND i.is_primary_key = 0 --do not check primary keys
AND i.is_unique_constraint = 0 --do not check unique constraints
AND i.is_unique = 0 --do not check unique indexes
--AND (ius.user_seeks+ius.user_scans+ius.user_lookups) < 1 --only return unused indexes
--AND OBJECT_NAME(i.OBJECT_ID) = 'tableName'--only check indexes on specified table
--AND i.name = 'IX_Your_Index_Name' --only check a specified index
--ORDER BY [Total Reads] ASC, [Total Writes] DESC OPTION (RECOMPILE);
select
[Machinerestartdatetime],
[sqlserver_start_time],
[Days:Hours:Minutes:Seconds] as [dd hh:mi:ss],--since how many days sql restarted
[CaptureDt],
[ServerName],
[DatabaseName],
[TableName],
[index_id],
[Index Name],
[type_desc],
[Total Reads],
[Total Writes],
[Difference],
[Row Count],
--[reads_per_write],
cast(round([reads_per_write],0,2) as numeric(36))
[IndexSizeMB],
[LastSeek],
[LastScan],
[LastLookup],
[LastUpdate],
[is_disabled],
[fill_factor],
[has_filter],
[disable statement],
[drop statement] --into sqldba_utils..cmx_ors_index_usage_stats_Aug112023
from #tmp
ORDER BY [Total Reads] ASC, [Total Writes] DESC OPTION (RECOMPILE); - Perry Whittle wrote:
If you need extra disk space extend the disks
We have maxed out 32 Azure VM limit. if we have to resize the vm, we need to go from 32 cpus to 120 cpus and thats licensing cost.
so, they are evaluating options to move some db's to a new sql server vm.

Viewing 15 posts - 1 through 15 (of 19 total)
You must be logged in to reply to this topic. Login to reply