Index suggestions question
- Jeff Moden wrote:ScottPletcher wrote:
For a stand-alone, nonclustered index with just that column in it, REBUILD that index setting the FREESPACE to 50[%]. That will delay any fragmentation for some amount of time, at least.
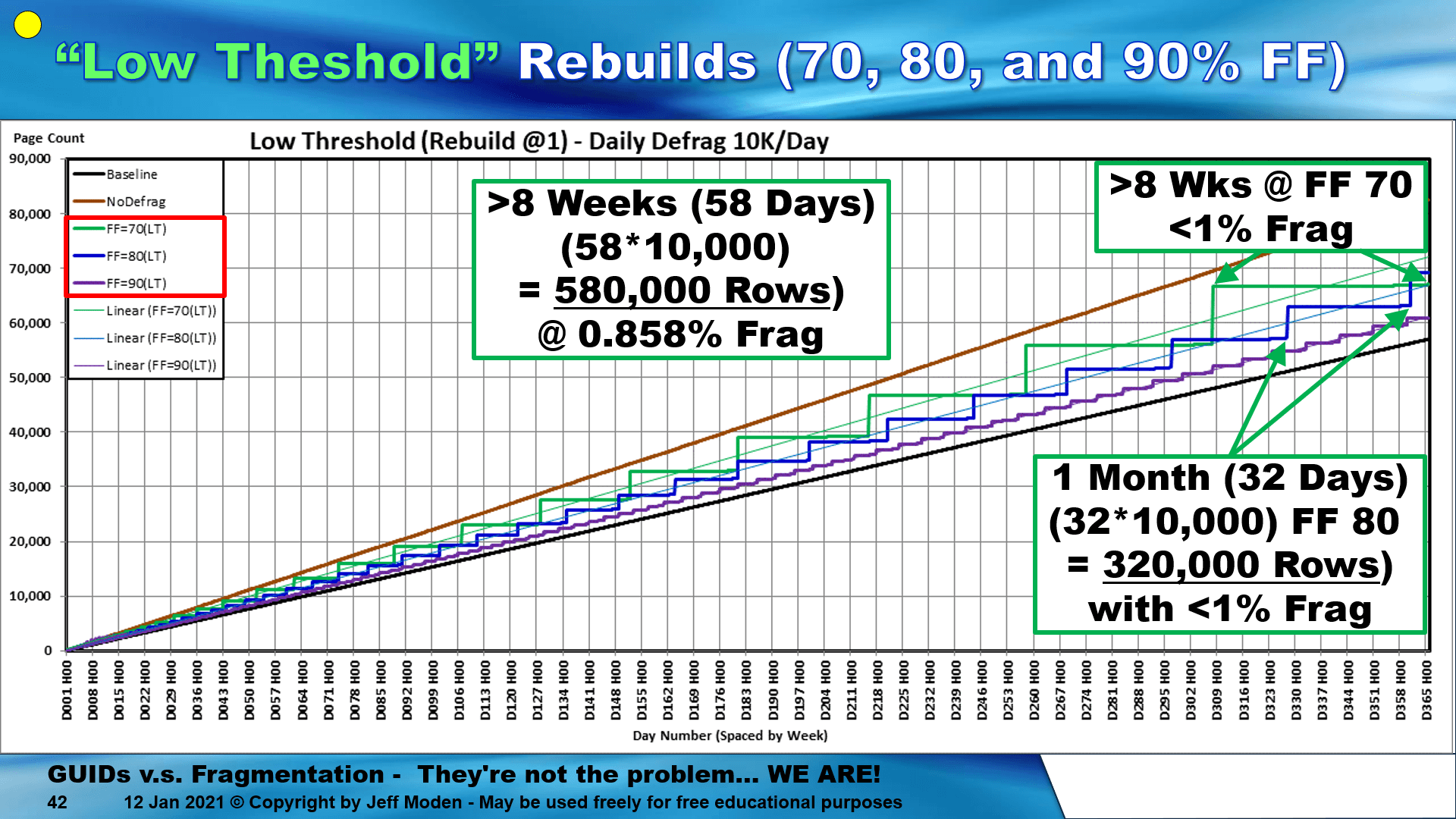
It doesn't need to be anywhere near as low as 50% if you maintain the index correctly. The same holds true for GUID Clustered Indexes (which the following graphic is on)...

I'd say it's still better to use 50% just to be safe. For a non-clus index that is used only to get the clus key to do a lookup, fragmentation does not matter anyway, only page splits matter. An index with only one guid is going to be very small anyway, so, again, more free space doesn't matter.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:
I'd say it's still better to use 50% just to be safe. For a non-clus index that is used only to get the clus key to do a lookup, fragmentation does not matter anyway, only page splits matter. An index with only one guid is going to be very small anyway, so, again, more free space doesn't matter.
Heh... so you want your quarter TB of indexes (includes CI and NCI) to actually take a half TB on your SSDs? I'm thinking that's not such a hot plan. It's bad enough that 80% actually requires an extra 25% and 70% requires an extra 42.9%
The important part with indexes that are evenly distributed when it comes to fragmentation is how many rows are being inserted per day relative to the size of the database.
Of course, some will argue that if a given table is created and you know how big the table is going to get, start the table off at that size with a 10% Fill Factor. Heh... I keep asking people to tell me how to do that during the first week. No one has been successful so far UNLESS they make totally bogus rows so they can have at least one row per page because totally empty pages aren't a thing and you still DO need the PK to be valued.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:ScottPletcher wrote:
I'd say it's still better to use 50% just to be safe. For a non-clus index that is used only to get the clus key to do a lookup, fragmentation does not matter anyway, only page splits matter. An index with only one guid is going to be very small anyway, so, again, more free space doesn't matter.
Heh... so you want your quarter TB of indexes (includes CI and NCI) to actually take a half TB on your SSDs? I'm thinking that's not such a hot plan. It's bad enough that 80% actually requires an extra 25% and 70% requires an extra 42.9%
The important part with indexes that are evenly distributed when it comes to fragmentation is how many rows are being inserted per day relative to the size of the database.
Of course, some will argue that if a given table is created and you know how big the table is going to get, start the table off at that size with a 10% Fill Factor. Heh... I keep asking people to tell me how to do that during the first week. No one has been successful so far UNLESS they make totally bogus rows so they can have at least one row per page because totally empty pages aren't a thing and you still DO need the PK to be valued.
No. I wish you would respond to what I actually wrote instead of making other things up. I made it very clear that I'm talking about 50% fillfactor only on the non-clus index containing the guid and the guid alone, which will not be that much space. As I noted, I would not use a guid for the clustering key.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Apologies, Scott. You're correct. You were talking only about the non-clustered indexes... but so what? Same differences. You're using twice as much disk space for those and for why? It's actually less necessary to go super low on the NCI's because they're much more narrow than the CIs and handle a whole lot more rows at 70 or 80% to begin with.
As for using a GUID for a clustering key or not, there are two things to consider... one is that you may have no choice in the matter and two and quite contrary to normal belief and except for them being pretty wide, they can really help you eliminate page splits and the resulting fragmentation of your CIs. Remember that while you use the CI for your most precious queries, there are serious advantages to using the CI go prevent fragmentation of the CI and let the NCIs handle the queries.
You also can't say that fragmentation doesn't matter. While I definitely agree that logical fragmentation usually doesn't matter, it sometimes does and big time and so "It Depends". There's always "physical fragmentation" (page density) and it frequently does seriously matter, especially when it comes to whether or no page splits are a problem or become one. As you well know, without it, page splits can and will dance a jig on your system. In one way or another, physical fragmentation almost always matters (and, yep... you know that... writing that for others).
"It Depends".
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
Apologies, Scott. You're correct. You were talking only about the non-clustered indexes... but so what? Same differences. You're using twice as much disk space for those and for why? It's actually less necessary to go super low on the NCI's because they're much more narrow than the CIs and handle a whole lot more rows at 70 or 80% to begin with.
As for using a GUID for a clustering key or not, there are two things to consider... one is that you may have no choice in the matter and two and quite contrary to normal belief and except for them being pretty wide, they can really help you eliminate page splits and the resulting fragmentation of your CIs. Remember that while you use the CI for your most precious queries, there are serious advantages to using the CI go prevent fragmentation of the CI and let the NCIs handle the queries.
You also can't say that fragmentation doesn't matter. While I definitely agree that logical fragmentation usually doesn't matter, it sometimes does and big time and so "It Depends". There's always "physical fragmentation" (page density) and it frequently does seriously matter, especially when it comes to whether or no page splits are a problem or become one. As you well know, without it, page splits can and will dance a jig on your system. In one way or another, physical fragmentation almost always matters (and, yep... you know that... writing that for others).
"It Depends".
Thank you for that.
Indeed the index I proposed is extremely narrow, 1 guid column. Given that, the disk space difference between 50% and 70% isn't likely that great, but I have no problem with 70% if that is sufficient to prevent fragmentation for as long a period of time as needed between rebuilds.
We do have some differences on automatically rebuilding such indexes all the time. We have hundreds of clients, and thus, many, many thousands of indexes. I don't have enough free I/O to be constantly rebuilding every non-clus index.
As to NCIs, I don't follow the popular belief that you should (almost) automatically use an identity as the clus "key" and then "tune" by creating gazillions of covering indexes. You use far more disk space AND, almost always, more buffer space as well. You create a covering index for almost each major query, but all those indexes have to be read and loaded separately. So, yeah, index 2 is only 4 columns, and index 3 is only 2 column, and index 3 is only 6 columns, etc., but add them all up, typically you have 3x-10x the table size. You'd often be better off just using the clus index with a more useful key, esp. since those clus reads can be shared by every task, whereas the covering indexes cannot.
Another reason is that there's no "tipping point" with a clus index like there is with non-clus indexes. The query "tips" and you end up with a full table scan despite your "covering" index. Those indexes are covering until they aren't. And it's very difficult to determine that tipping point and when/how any given query will hit it.
As to, "You also can't say that fragmentation doesn't matter." Again, what I actually said was that, for an index used only for single keyed lookups, fragmentation does not matter to performance. And that is true. Only some type of scan would suffer from fragmentation, and you don't scan for guid ranges, you do individual value lookup(s).
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
Viewing 5 posts - 16 through 20 (of 20 total)
You must be logged in to reply to this topic. Login to reply