Index suggestions question
-
Many index-suggestions I get from the database I'm working on, very often suggests quite alot of include-columns. Could this be a sign of poor database-design? As far as I understand, you don't want to include alot of columns in each index since the the storage will increase quite alot.
"My" tables has an Id-column (UNIQUEIDENTIFIER), but also a few other columns that are frequently used for queries.
How careful should I be including columns in my indexes?
-
Included columns are very helpful for avoiding lookups, but it is up to you to decide if you should avoid lookups. This depends on few factors. For example how much is a query being used? If I have a query that is used once a day for reports, I wouldn't create an index with included columns for it. On the other hand if I have a query that runs all the time and can run few hundreds times per second during pick hours, I would probably try to avoid the lookups and create an index with included columns. Other factors that we should consider are how selective the query is (for example - query that most times won't return any record vs query that returns few thousands rows) and if the time that the query runs is too slow or not.
Adi
-
If I've got a table with 20 million rows, and add an index with (alot) of included columns, wouldn't this take just as much storage as the original table.?
-
Each index has a price in storage and in the amount of time that insert will take (some of them can save us time for delete and updates but some of them will cause those operations also to take longer). This is true for any index on any table regardless of the amount of rows that the table has and regardless if it has or doesn't have included columns. I don't think that I (or anyone else) can tell you if you should use included columns or not. Like I wrote before it depends on factors that we don't know. I don't know if you are considering to add all the columns to the index (by the way in such case you might consider changing the clustered index) or just few columns. I don't know how much the query that you want to optimize is being used. I don't know how much lookup operations the index with included columns will save. You have to understand the advantages and disadvantages of this index and then decide.
Adi
- oRBIT wrote:
Many index-suggestions I get from the database I'm working on, very often suggests quite alot of include-columns. Could this be a sign of poor database-design? As far as I understand, you don't want to include alot of columns in each index since the the storage will increase quite alot. "My" tables has an Id-column (UNIQUEIDENTIFIER), but also a few other columns that are frequently used for queries.
How careful should I be including columns in my indexes?
Yes, it could be a sign of poor db design. But the index suggestion tool itself is not great and will often make poor suggestions.
INCLUDEd columns are extremely problematic if they are updated fairly often, since an included column must be updated in every index in which it appears.
You should be extremely careful about creating any index just based on a suggestion from any automated tool.
The first thing to do is to review all tables and the clustered indexes on them. Getting the best clustered index on every table is by far the single most important part of tuning indexes. After the clus index is properly set, then you can check the rest of the indexes.
You'll need at least this data to properly review and adjust indexes: current index usage stats, missing index stats and index operational stats. Often you will need other info, but that info is the minimum base you will need.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
It's difficult and exciting at the same time this stuff. 🙂
Staring at a table now, more than 6,000,000 rows, about 25 columns. Posts are not updated that much, but inserted and deleted. PK is a UniqueIdentifier, CreatedDate is Clustered Index. However many queries doesn't refer to CreatedDate but to another Id-column (UniqueIdentifier) that's one of those 25 columns.
According to QueryStore, the most executed query is a query that's like that, and obviously there's a KeyLookup because the Id-column is not the clustered index and we don't want KeyLookups.
Creating a new index for that column + include all required columns would create a pretty huge index.
Setting the requested Id-column as ClusteredIndex would perhaps be the best(?) idea here. But still, it's a GUID which isn't ideal either..
Confused... 😀
-
True, key lookups aren't ideal, but in that case you don't have any choice. A nonclustered index on the guid with a key lookup is your best option there.
Some other things to consider:
Are you using data compression?
Do you have LOB data types? If so, have you forced them out of row? Have you COMPRESSed them?
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
No, no datacompression here.
Datatypes used are guids, nvarchar(max/XXX), datetime's mostly.
-
What's the avg len of the (MAX)?
You should analyze whether forcing them to LOB overflow would be better for your setup.
COMPRESS is slow when inserting, but it can save a lot of space.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
A majority is below 3000 characters, most are alot smaller than that.
That LOB overflow stuff is nothing I've touched before (as far as I know anyway).
-
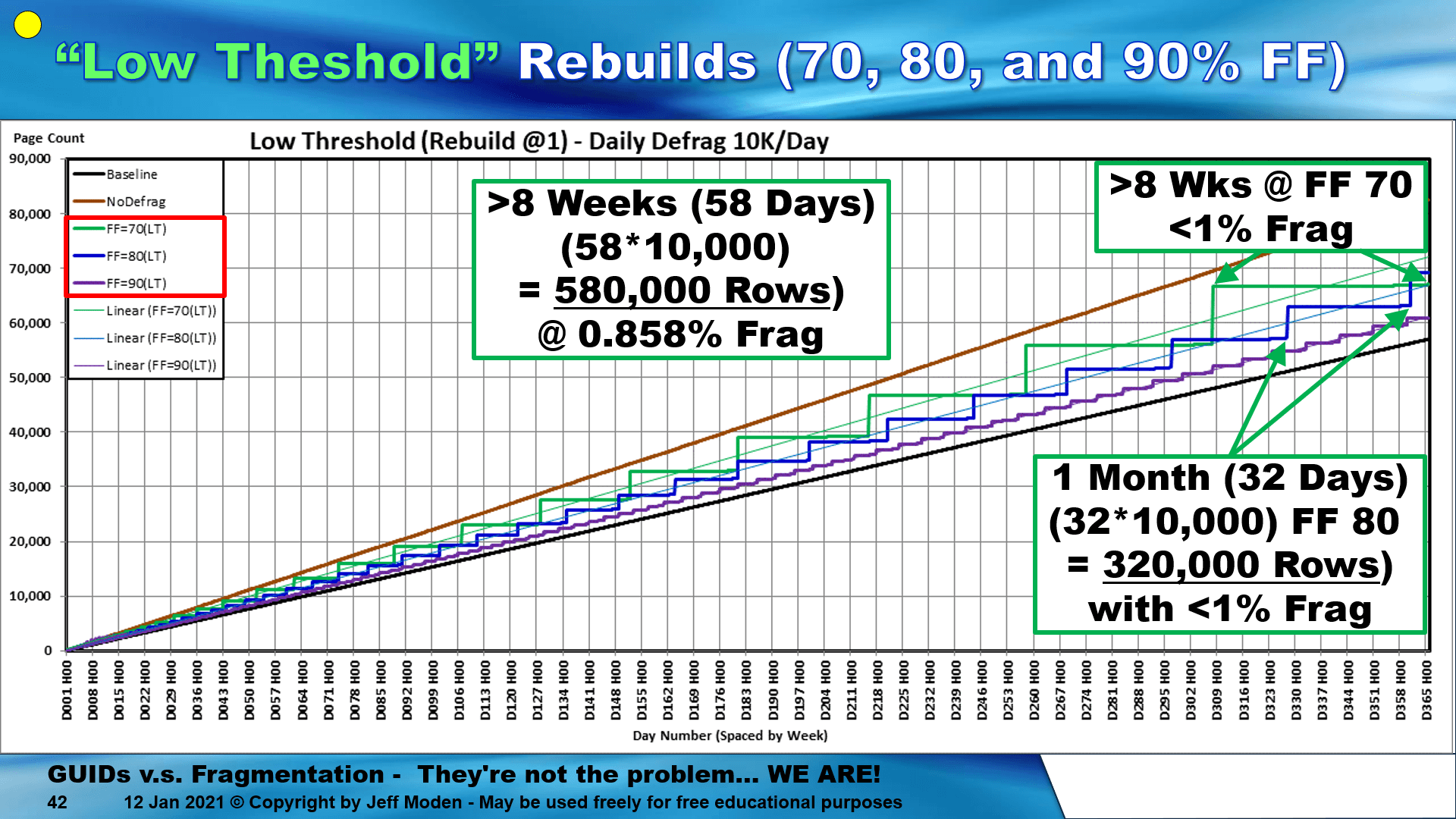
Fragmentation associated with Random GUIDs is a complete MYTH based on improper testing, misinformation, and the use of supposed "Best Practices" for index maintenance that are actually "Worst Practices" and I've proven it all time and again with literally hundreds of hours of testing and repeatable demonstrations. If your queries could seriously benefit from using the Random GUID column as a Clustered Index, I can help with all of this.
Seriously... people have got this Random GUID thing totally screwed up... Random GUIDs are actually the epitome of what people think and index should operate as and I can actually show you how to prevent fragmentation by using them. For example, I have one demonstration where I insert 100,000 rows per simulated day for 58 straight days with a total of less than 1 % fragmentation and no index maintenance for the entire 58 days. That's 5.8 MILLION rows inserted with < 1% fragmentation and almost zero page splits!
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
I've experienced the random GUID-"problem" upclose in other tables. Index is 98-99% fragmented just a few hours after a defragjob has completed. There's frequent INSERT and DELETE in that table.
-
For a stand-alone, nonclustered index with just that column in it, REBUILD that index setting the FREESPACE to 50[%]. That will delay any fragmentation for some amount of time, at least.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- oRBIT wrote:
I've experienced the random GUID-"problem" upclose in other tables. Index is 98-99% fragmented just a few hours after a defragjob has completed. There's frequent INSERT and DELETE in that table.
It's mostly because you're not maintaining the GUID Indexes correctly of they're incredibly small in size.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - ScottPletcher wrote:
For a stand-alone, nonclustered index with just that column in it, REBUILD that index setting the FREESPACE to 50[%]. That will delay any fragmentation for some amount of time, at least.
It doesn't need to be anywhere near as low as 50% if you maintain the index correctly. The same holds true for GUID Clustered Indexes (which the following graphic is on)...

--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 15 posts - 1 through 15 (of 20 total)
You must be logged in to reply to this topic. Login to reply