index scan where seek expected
- ScottPletcher - Monday, October 22, 2018 11:25 AM
I hope you're not saying that ColA and ColB would make the best CI in this case.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Monday, October 22, 2018 3:56 PM
If he (almost) always searches by ColA and/or ( ColA, ColB ), then it most likely would. Would need more details to be sure that's OK, but it typically is.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher - Monday, October 22, 2018 4:05 PM
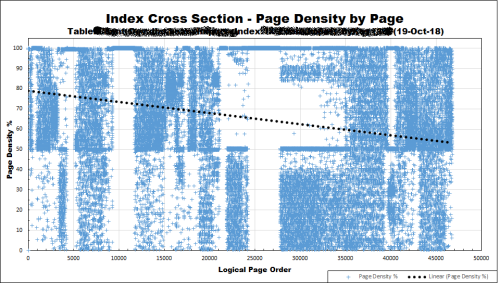
The trouble is that few people consider the number of page splits, physical fragmentation, logical fragmentation, and the massive effect that the crazy number of page splits will have on the log file that such keys for a CI will cause. Here's an example of such a keyed CI. It's a train wreck that needs to be rebuilt quite often. Of course, that causes even more log file action. Good luck if you doing log shipping or any other type of replication that uses the log file.

--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thanks again for the responses. I can't re-cluster the table as it's part of a third-party package and already has a surrogate (clustered) primary key. Also the index in question is very far from the most used. I'm wondering why it's so shocking to suggest that the optimiser might be getting it wrong on this occasion. It is after all only a program, and programs have bugs.
- jontris - Tuesday, October 23, 2018 2:49 AM
Typically you can still re-cluster it. Retain the original PK, but just make it non-clus. If the new clus works, then you can drop any non-clus indexes that have the same leading key(s). Of course you'd have to check with vendor on this: some will work with you, some won't.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher - Tuesday, October 23, 2018 10:13 AM
Heh.... but first, see my response with the graph for why you shouldn't even consider clustering on the two columns we're talking about. 😉
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Tuesday, October 23, 2018 10:25 AM
That graph has nothing specific to do with this table. I'd have to see the specific stats on this table to decide. But if (almost) all queries had WHERE conditions on ColA or ( ColA, ColB ), I would certainly cluster on those columns if at all reasonable. Things can be done to mitigate alleged "atrocities" from INSERTs. And there's only one INSERT of a row, and generally 100Ks or Ms or SELECTs.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher - Tuesday, October 23, 2018 10:52 AM
It has everything to do with this type of table and index because CI's that are built in such a fashion will, in fact, follow the same silo pattern.
However, one good test is worth a thousand expert opinions. Design a table and tell me how you'd like me to populate it over a simulated year and we'll see what happens.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 8 posts - 31 through 38 (of 38 total)
You must be logged in to reply to this topic. Login to reply