Index rebuild automation on specified tables
-
Hi,
i need to automate the index rebuild on specified tables.
1)identify the table which is having more than 30 % ( i need top tables)
2)those tables needs to index rebulid dalily.
any one help me on this.
-
look at Ola scripts https://ola.hallengren.com/ - will do what you asked (and a lot more if you need)
- Diyas wrote:
Hi,
i need to automate the index rebuild on specified tables.
1)identify the table which is having more than 30 % ( i need top tables)
2)those tables needs to index rebulid dalily.
any one help me on this.
I agree with the recommendation to use Ola Hallengren's fine scripts but they won't actually help you with doing things right. Waiting for 30% fragmentation means you're waiting until most of the damage in the form of page splits have occurred. Page splits can cause a huge tax on the log file and they can cause massive blocking that a lot of people have on the morning after their index maintenance has occurred and the either don't realize the blocking is happening or they don't know what to do about it especially because the blocking only lasts for several hours until the splits have cause enough free space in the pages to no longer need to split.
I'll also tell you that if your system is looking up one row at a time, then logical fragmentation (the thing most people are talking about when they refer to "fragmentation") absolutely has NO bearing on performance. Only batch jobs that read lots and lots of rows will actually benefit from low "fragmentation".
One of the other things that matter, frequently more than logical fragmentation is the Page Density or average percent of page space used but almost no one measures that.
Getting back on the subject, of you have indexes that are fragging to 30% in just a day or two, defragging them is as about as smart (it's not) as shrinking your log files every day. Until you can identify the cause of the fragmentation and fix it (and, yeah... there are ways to fix a lot of it), your index maintenance is mostly a mostly futile endeavor. Lowering a FILLFACTOR to try to prevent fragmentation is usually a futile effort, as well (Random GUIDs, strangely enough and highly contrary to popular but terribly wrong myths, are the "best" candidates to prevent fragmentation and can be made to go for months with absolutely no page splits either good or bad.).
Also contrary to popular belief is the myth that INSERTs are the biggest cause of page splits and the ensuing fragmentation. While they can certainly cause a lot of fragmentation, in real life, "ExpAnsive" updates are the biggest culprit. You need to find those and fix those or your index maintenance will not do much but continue to waste time and log file backup space.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
You would be so much better served listening to Jeff and skipping the rebuilding of indexes. Maintaining statistics on indexes is vital, but defragmenting indexes is an idea that has reached a point where it's just not that good any more. This is especially true if you're not looking at many scans on these indexes. If you're mostly seeing point lookups, chances are the fragmentation isn't hurting a bit.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning - Grant Fritchey wrote:
You would be so much better served listening to Jeff and skipping the rebuilding of indexes. Maintaining statistics on indexes is vital, but defragmenting indexes is an idea that has reached a point where it's just not that good any more. This is especially true if you're not looking at many scans on these indexes. If you're mostly seeing point lookups, chances are the fragmentation isn't hurting a bit.
Just to make couple of suggestions here.
Defragging indexes can be very important to large multi-row batches. If you don't think so, understand why you have to rebuild indexes that need it after a DBCC SHRINKFILE, which has the nasty habit of creating "Index Inversion" or the worst fragmentation possible.
But, for the sake of argument, let's say that a database only ever suffers single row lookups where logical fragmentation won't matter even a bit and then remember...
...There are two types of fragmentation. There's logical fragmentation, which really affect only "batch processing" ordered scans of indexes and then there's "Physical Fragmentation", also simply referred to as "Page Density". Most people don't even look at "Page Density" as an indicator of the need to defrag.
While it's true that a full page must be in memory to read even a single row, consider this... if you have 400 new rows and they all reside on just two pages, you only need to read into memory those two pages to access all 400 new rows (and new rows are usually the most commonly accessed rows). If your "page density" drops to 10% for those new rows due to "Expansive Updates", then you're having to read 10 times the number of pages into memory and that's just for that one index, whatever it is.
The trouble here is that the "avg_page_space_used_in_percent" (AKA, "Page Density") column in sys.dm_db_index_physical_stats is an AVERAGE and it doesn't show the extremely low page density of the most recent data if the likes of "Expansive Updates" occur.
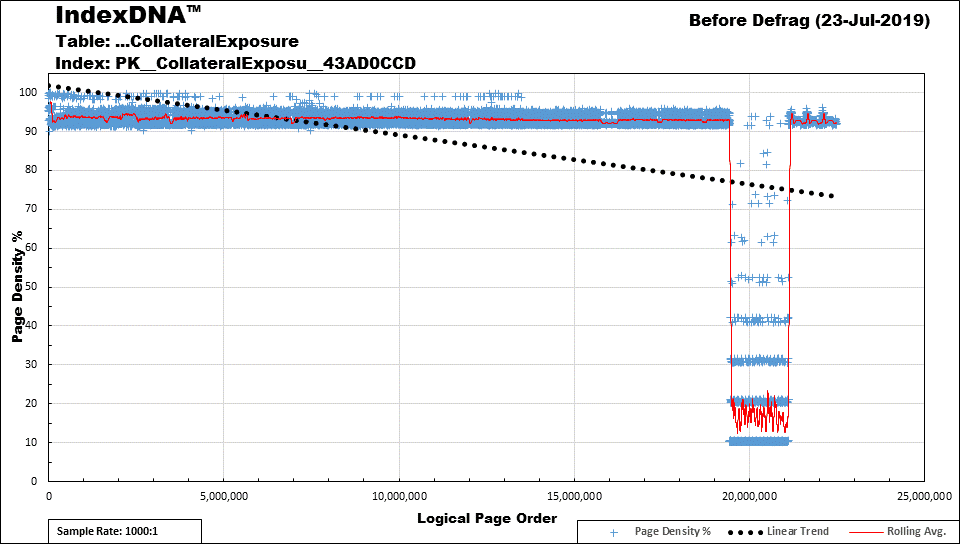
For example, here's an IndexDNA™ chart for one of my 146GB clustered indexes. The large dip in the right shows that the most recent data is only filled to a "silo average" of about 15%. The "avg_page_space_used_in_percent" returned by sys.dm_db_index_physical_stats indicated that this index had a page density of 84% and a logical fragmentation of "only" 10%.

If this index were only, say, 10GB or less and since the average of 9 rows per page only allows this index to fill to a maximum "Page Density" of about 93%, I'd REBUILD (not reorganize) it any time it got below 90% page density.
Why do I say "not reorganize) For this large 146GB index, it takes 1 hour and 21 minutes to REORGANIZE and it causes my 37GB log file to explode to about 247GB! For a special rebuild to another file group (to keep from having a totally unnecessary) in the BULK LOGGED mode (I have nothing that relies on the log file... we use SAN replication, instead), it only takes a little over 7 minutes and causes no additional growth in the log file above the original 37GB.
And THAT's a part of what I'm talking about. The standard 10/30 rule doesn't work and REORGANIZE sucks (you should only use it to compact LOBs and there's a way around that, as well). Unless you actually know how an index is being used and what the insert and update patterns are, you're better served by rebuilding anything between 72% and 82% page density to 82% and then anything >82% but less than 92% to 92%
Why do those fill factors end in "2"? I use the value of the fill factor to tell me that 1) I've analyzed the index or not and 2) if it ends with a "2", it means that I've still got something "TO do" to fix the index but needed to recover the disc space. For the big index above, I set the fill factor to 97%, which means I've analyzed the index and it's based on an ever-increasing key (which should not fragment) but suffers "Expansive Updates" on the most recently added data. So the "7" looks kind of like a "2" and we still have something "TO do" on this index. We rebuild it with such a high fill factor because it would be a complete waste of memory and disk space to not build it close to 100% because, once the new rows are updated, they NEVER get updated again and will always remain at a very high "Page Density.
So, yes... you still need to defrag because all of our systems have some limit on memory (which is reflected on disk and so we need to keep things smaller for backups and restores, as well) and, as fast as it is, Memory I/O can still slow things down a lot.
The other point that Grant pointed out is spot on. Keep your stats up to date, especially if you have "ever-Increasing" indexes!.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 5 posts - 1 through 5 (of 5 total)
You must be logged in to reply to this topic. Login to reply