Index rebuild
- ScottPletcher wrote:
Presumably that 147GB CI had (nearly) every page out of logical order or (nearly) every page was below the fillfactor. Hmm, veryh odd, interesting.
Again, I can't imagine needing an unpartitioned table that large. Was there actually 147GB of active data? We deal with very large volumes of data, but not that much in one table that is active at the same time. That would be a real challenge to manage.
I don't have time to set up and do full tests on any of this stuff now. When I get a chance, I will do that.
No, most pages weren't out of order. Like I said, it only had 12% logical fragmentation. It would do inserts in the Ever-Increasing CI and then deletes of a fair bit of that recent data in just a day or two. IMHO, it wasn't big enough to worry about partitioning regardless of the amount of "active" data especially after I stopped using REORGANIZE on it. 😀
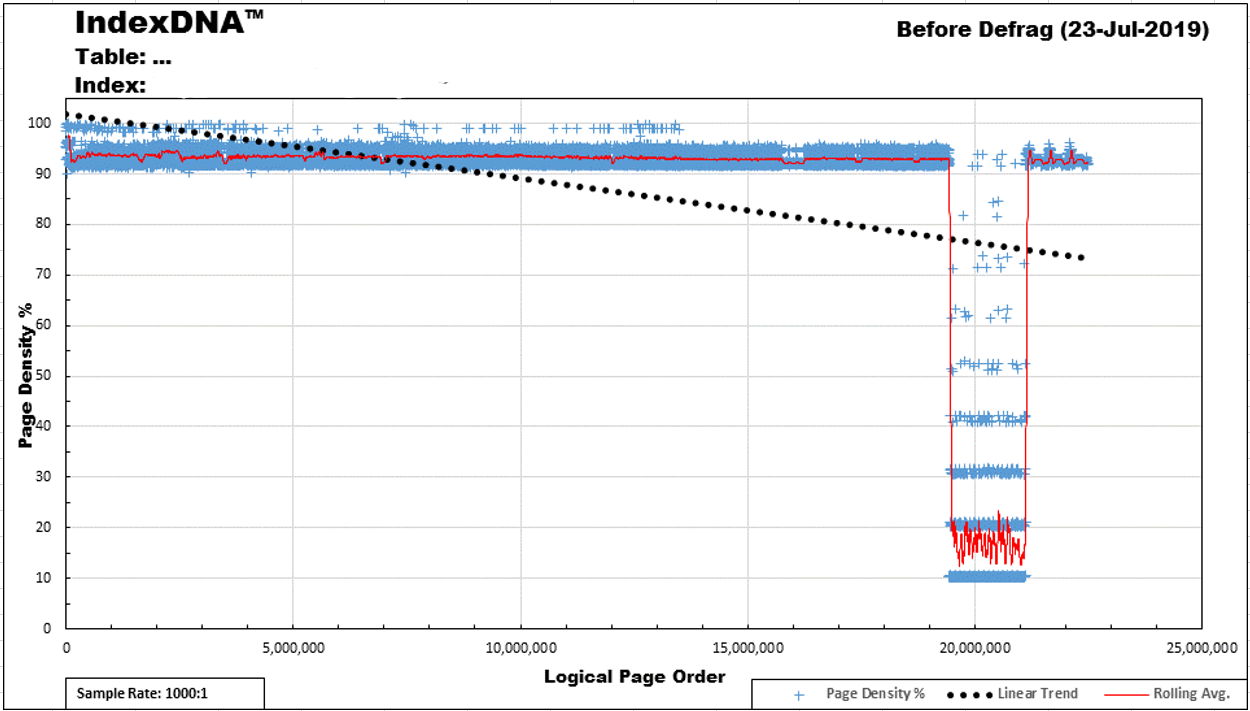
Here's the chart of the table pages. Everything to the left of the huge dip in the line is as it always is (it's only got 9 rows per page) and that's what the whole index looks like after a rebuild. This one is about two weeks after the latest rebuild.

I've since compressed the CI. Compression also has a suck factor... what used to take 12 minutes to rebuild now takes 45. I AM considering partitioning it but I didn't back then because 147GB just isn't that big.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:ScottPletcher wrote:
Presumably that 147GB CI had (nearly) every page out of logical order or (nearly) every page was below the fillfactor. Hmm, veryh odd, interesting.
Again, I can't imagine needing an unpartitioned table that large. Was there actually 147GB of active data? We deal with very large volumes of data, but not that much in one table that is active at the same time. That would be a real challenge to manage.
I don't have time to set up and do full tests on any of this stuff now. When I get a chance, I will do that.
No, most pages weren't out of order. Like I said, it only had 12% logical fragmentation. It would do inserts in the Ever-Increasing CI and then deletes of a fair bit of that recent data in just a day or two. IMHO, it wasn't big enough to worry about partitioning regardless of the amount of "active" data especially after I stopped using REORGANIZE on it. 😀
Here's the chart of the table pages. Everything to the left of the huge dip in the line is as it always is (it's only got 9 rows per page) and that's what the whole index looks like after a rebuild. This one is about two weeks after the latest rebuild.
Fairly frequent random deletes lower the space used below the fill factor and thus can cause an issue with reorg.
When I get time -- i.e. when I'm not dealing with my mother's estate and I'm able to get a decent night's sleep (my brothers are already upset that I'm taking so long -- I will set up some scenarios and test this out. Again, I have used this in real life in the past and didn't have any big issues with much of the time; yes, sometimes I did. With the corollary, again, that we do NOT delete data so that it just goes away. Business-wise, our data can't just disappear. Even something entered in error is archived out, not just deleted randomly.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- Sergiy wrote:
How massive are your DELETEs?
Probably it would be easier to copy the remaining part of data to a new table (exact copy of the old one) and then drop old one and rename the new one to the old name.
All indexes will be freshly built, and almost no logging involved.
Yup. I know that trick. I've both used it and have recommended it many times.
The DELETEs aren't that massive per run. What I'd really like to do is get the bloody "programmers" on this table to stop adding stuff that's just going to be deleted. The REBUILD (back then) only used to take 12 minutes and it cost almost nothing in log file size because this database is in the BULK LOGGED recovery model.
Time has marched on and it's gotten bigger. I can only imagine how big it would be if they didn't do the deletes. And, yeah... I may have to break down and partition it.
But... none of that is the point that I'm trying to make. The point is that using REORGANIZE on this bad boy sucks, just like it does on a whole bunch of other tables despite the fact that there's a supposed limited amount of work that needs to be done on this CI. The picture in my previous post was taken at only 12% logical fragmentation and nothing to the left of the big "dip" was out of order. Reorganize just doesn't work the way most people think it does and that's my point and my recommendation with that is to simply stop using it for anything except LOB compression and then to follow that with a REBUILD to undo the mess REORGANIZE is going to leave behind.
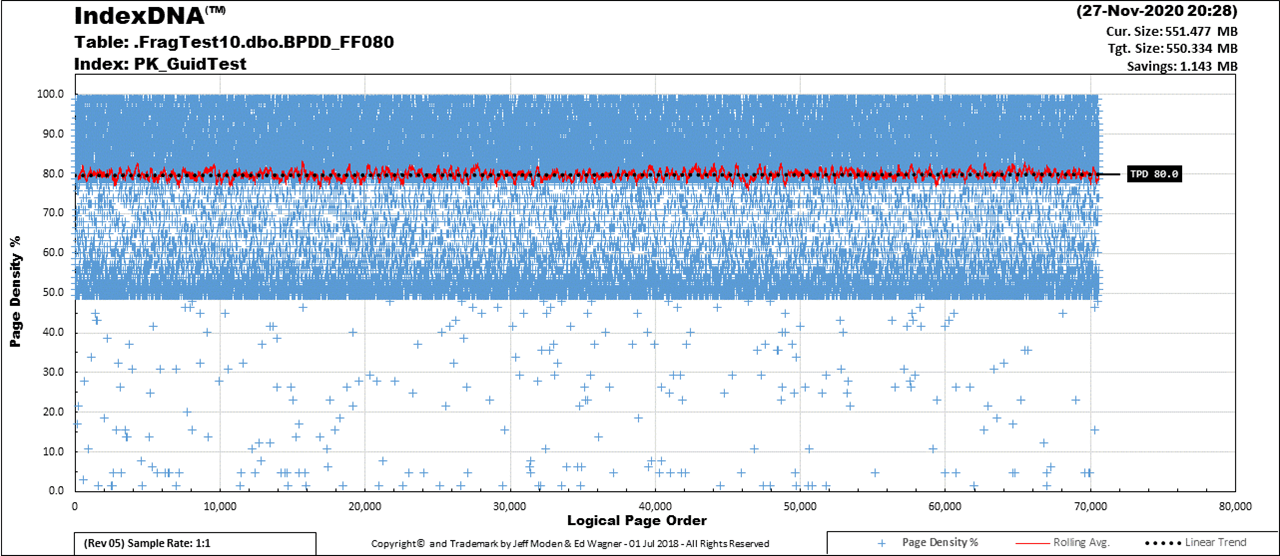
Here's another example... Here's what REORGANIZE does to a GUID CI with an 80% Fill Factor over time. This is right after a reorg and it will exceed 5% logical fragmentation in 4 days.
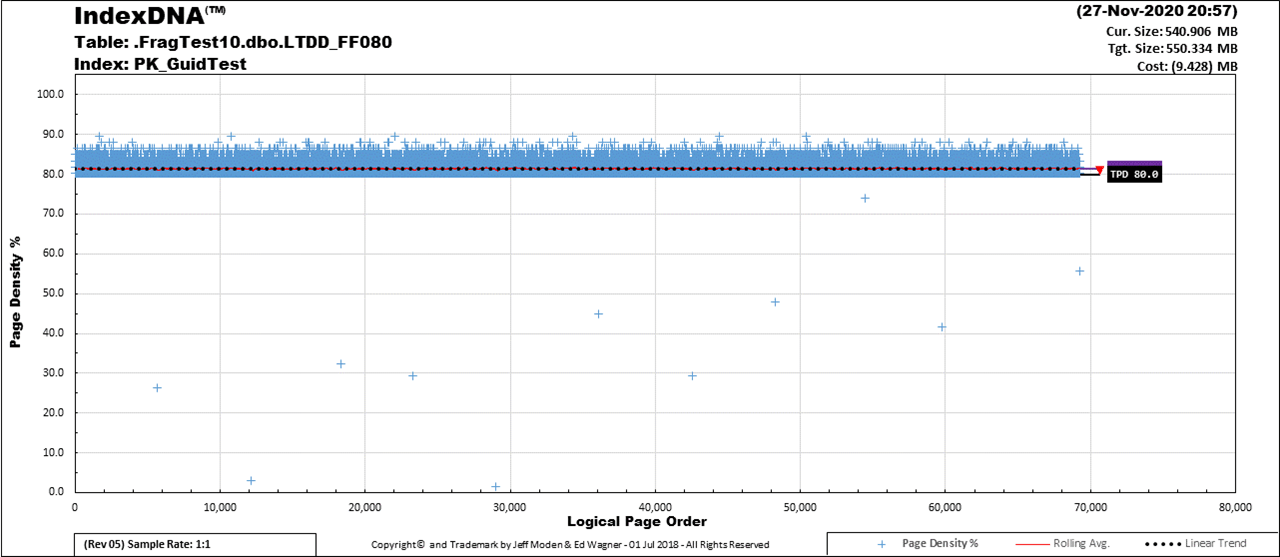
Here's what the same index looks like 4 days after a REBUILD... it has another 28 days to go before it reaches 1% logical fragmentation.
Plenty of room above the Fill Factor.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - ScottPletcher wrote:
Fairly frequent random deletes lower the space used below the fill factor and thus can cause an issue with reorg.
First of all, those are NOT random deletes. They're very focused.
Second of all, you're just playing back what I already said. You said REORGANIZE would be good to use on DELETES and I'm telling you that's absolutely not true. 😉
While I certainly appreciate your offer to test sometime in the future, you don't need to expend any time on testing... I've got more than 600 hours testing of this and much more under my belt. It all leads to the same proof... REORGANIZE is not the general tool to use and the current "Best Practices" that everyone uses for index maintenance are not only NOT a "Best Practice", they were never meant to be treated as a "Best Practice". Read Paul Randal's article on that subject... especially the last sentence in the article.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:ScottPletcher wrote:
Fairly frequent random deletes lower the space used below the fill factor and thus can cause an issue with reorg.
First of all, those are NOT random deletes. They're very focused.
Second of all, you're just playing back what I already said. You said REORGANIZE would be good to use on DELETES and I'm telling you that's absolutely not true. 😉
While I certainly appreciate your offer to test sometime in the future, you don't need to expend any time on testing... I've got more than 600 hours testing of this and much more under my belt. It all leads to the same proof... REORGANIZE is not the general tool to use and the current "Best Practices" that everyone uses for index maintenance are not only NOT a "Best Practice", they were never meant to be treated as a "Best Practice". Read Paul Randal's article on that subject... especially the last sentence in the article.
I said it's good for massive DELETEs in clus key order, so that pages are fully emptied (the last page maybe only partially). Not on random deletes, i.e., deletes on many current pages. Such massive deletes are for moving the data to history/archive, or, for log tables, removing completely because it's outside the date of when we need that internal log data.
I don't endorse those general rules as "best practices" and never have and was not speaking to that here. I explicitly was talking about it for specific situations.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:Jeff Moden wrote:ScottPletcher wrote:
Fairly frequent random deletes lower the space used below the fill factor and thus can cause an issue with reorg.
First of all, those are NOT random deletes. They're very focused.
Second of all, you're just playing back what I already said. You said REORGANIZE would be good to use on DELETES and I'm telling you that's absolutely not true. 😉
While I certainly appreciate your offer to test sometime in the future, you don't need to expend any time on testing... I've got more than 600 hours testing of this and much more under my belt. It all leads to the same proof... REORGANIZE is not the general tool to use and the current "Best Practices" that everyone uses for index maintenance are not only NOT a "Best Practice", they were never meant to be treated as a "Best Practice". Read Paul Randal's article on that subject... especially the last sentence in the article.
I said it's good for massive DELETEs in clus key order, so that pages are fully emptied (the last page maybe only partially). Not on random deletes, i.e., deletes on many current pages. Such massive deletes are for moving the data to history/archive, or, for log tables, removing completely because it's outside the date of when we need that internal log data.
I don't endorse those general rules as "best practices" and never have and was not speaking to that here. I explicitly was talking about it for specific situations.
I presume you're talking about this post of yours, Scott.
ScottPletcher wrote:I've found one other use for REORG. When I've done massive deletes on a table, I've found that a REORG first is sometimes better than a REBUILD first. Follow the REORG with a REBUILD. Not sure why that is, but I've seen it.
You only talk about massive deletes... nothing about doing it in clustered key order. You don't even mention anything about completely emptying pages. If you did for both of those missing items, then you wouldn't actually need to do any index maintenance because ever increasing complete page DELETEs from the logical beginning of an index is just like INSERTs at the logical end of the index... virtually NO fragmentation will be created (other than skipped pages and you can go for years before that causes enough logical fragmentation to warrant a defrag).
In other words, you wouldn't actually need to do any index maintenance on a index that you just described above. 😉
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
When you plan to rebuild/reorganise an index you need to answer the main question:
What happens next?
Massive DELETEs on the table imply that there are as massive INSERTs.
What happens to the index(es) after the 1st insert since the latest reorganising?
Is its fragmentation any better than it was before that?
How about the statistics of the reporting queries - what kind of performance gain you get from reindexing the table? If you'd run reports INSTEAD of reindexing - would they all be done long before the reindexing is complete? What's the point then?
If massive deletes leave big chunks of sequential pages empty then new inserts will just fill them up with new data in perfectly organised manner, and, I agree with Jeff on it, reindexing would not be needed at all.
And even if the records would be badly scattered across the random pages in random extents only certain type of queries with specific types of execution plans would suffer from significant performance degradation due to such unfortunate index state. If you have a lot of Clustered Index Scans or Bookmark Lookups you queries performance would not suffer from any kind of index fragmentation.
_____________
Code for TallyGenerator - Sergiy wrote:
When you plan to rebuild/reorganise an index you need to answer the main question:
What happens next?
Massive DELETEs on the table imply that there are as massive INSERTs.
What happens to the index(es) after the 1st insert since the latest reorganising?
Is its fragmentation any better than it was before that?
How about the statistics of the reporting queries - what kind of performance gain you get from reindexing the table? If you'd run reports INSTEAD of reindexing - would they all be done long before the reindexing is complete? What's the point then?
If massive deletes leave big chunks of sequential pages empty then new inserts will just fill them up with new data in perfectly organised manner, and, I agree with Jeff on it, reindexing would not be needed at all.
And even if the records would be badly scattered across the random pages in random extents only certain type of queries with specific types of execution plans would suffer from significant performance degradation due to such unfortunate index state. If you have a lot of Clustered Index Scans or Bookmark Lookups you queries performance would not suffer from any kind of index fragmentation.
All good qustions but I've been through all of that with this index.
First of all, I don't use REORGANIZE. I haven't used it since the 17th of January, 2016 except to demonstrate what a mess it makes.
Second, I know this table does inserts at the logical end of the ever-increasing index, which causes no fragmentation. There are no "ExpAnsive" updates ever used against this table (I wrote special code that finds such things). Shortly after the inserts is when the deletes occur. That's what the dip is in the index page density on the chart. Nothing on the planet nor in the universe will prevent either the physical fragmentation (page density) nor the logical fragmentation (next logical page isn't the next physical page) caused by the deletes.
What you're looking at in the dip in the chart is typically 20-30GB of wasted disk and memory space and, unfortunately, that's also the most actively queried region of this index. I rebuild this index with a 97% Fill Factor. The "7" in that is like a footless "2" which reminds me that I have something "2 do" to fix this thing... like getting a hold of the code to see why people are inserting things that are just going to get deleted and the fix it. After that, this index will never fragment.
Like I said... I don't actually need help with this index... (I just need some time to get to it) I posted this as an example of where REORGANZE after deletes is still a horrible idea after Scott mentioned that he thought is was a good place to use REORGANIZE.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:ScottPletcher wrote:Jeff Moden wrote:ScottPletcher wrote:
Fairly frequent random deletes lower the space used below the fill factor and thus can cause an issue with reorg.
First of all, those are NOT random deletes. They're very focused.
Second of all, you're just playing back what I already said. You said REORGANIZE would be good to use on DELETES and I'm telling you that's absolutely not true. 😉
While I certainly appreciate your offer to test sometime in the future, you don't need to expend any time on testing... I've got more than 600 hours testing of this and much more under my belt. It all leads to the same proof... REORGANIZE is not the general tool to use and the current "Best Practices" that everyone uses for index maintenance are not only NOT a "Best Practice", they were never meant to be treated as a "Best Practice". Read Paul Randal's article on that subject... especially the last sentence in the article.
I said it's good for massive DELETEs in clus key order, so that pages are fully emptied (the last page maybe only partially). Not on random deletes, i.e., deletes on many current pages. Such massive deletes are for moving the data to history/archive, or, for log tables, removing completely because it's outside the date of when we need that internal log data.
I don't endorse those general rules as "best practices" and never have and was not speaking to that here. I explicitly was talking about it for specific situations.
I presume you're talking about this post of yours, Scott.
ScottPletcher wrote:I've found one other use for REORG. When I've done massive deletes on a table, I've found that a REORG first is sometimes better than a REBUILD first. Follow the REORG with a REBUILD. Not sure why that is, but I've seen it.
You only talk about massive deletes... nothing about doing it in clustered key order. You don't even mention anything about completely emptying pages. If you did for both of those missing items, then you wouldn't actually need to do any index maintenance because ever increasing complete page DELETEs from the logical beginning of an index is just like INSERTs at the logical end of the index... virtually NO fragmentation will be created (other than skipped pages and you can go for years before that causes enough logical fragmentation to warrant a defrag).
In other words, you wouldn't actually need to do any index maintenance on a index that you just described above. 😉
I know you think I'm an idiot, but I think there was a reason for me to do it. Then again, I'm particularly tired now, so maybe I'm remembering incorrectly.
I was deleting data because we were (very) short of disk space rather suddenly. So getting disk space actually freed up for other purposes was vital.
Now, as I understand it, deletes, esp. voluminous deletes of only the earliest pages in a table, don't really delete rows right away, rather SQL ghosts them. I don't think those pages get finally removed until you read them. Since I wanted the space back pronto, I felt I needed to rebuild or reorg, which would naturally access those pages. And I found that reorg was often a lot faster for getting rid of all those ghosted pages. Not always, but very often. Since these were large tables, reorg worked much faster, at least for me, in those cases. If it matters, I had put the db in simple mode, again just to save disk space, because it was acceptable for this particular process on those particular dbs. Especially in the situation we were in. (TWIMC: we're quite good again on disk space now.)
Edit: And, I can't have the tables unavailable. They were virtually all business logging tables, so they were written to constantly. Thus, reorg had an obvious advantage that it didn't make the table unavailable and didn't require huge amounts of extra data space nor log space.
As you know, I think, I'm very diligent about choosing a clus index. For time-dependent tables, I (almost) always clus on columns that allow rows to be deleted efficiently later in time order. Typically not with just identity, of course, I wouldn't allow that egregious error, but very often a datetime followed by $IDENTITY for uniqueness.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Yeah, I didn't go into deep details in the initial postings. Didn't seem necessary. I guess it was. I have trouble even imagining the business or technical case where I'd ever design a table to have massive deletes all over the table at the same time.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
No... I don't think you're an idiot, Scott. Far from it. I just couldn't figure out what the heck you were talking about. Your post above finally explains it. You also posted about a personal issue that's been keeping you hopping and then changed it. I totally understand those types of issues. Now that I know what you meant, it's pretty easy for me to give it a try. I can see reorg probably chasing the ghost rows but I need to check what the log file cost is. I've found it to be way more expensive that rebuilds in most cases. That's one case I've not checked. I really appreciate the feedback there.
To answer one of the questions you asked that I missed previously, the reason why the log file grew to 247GB was because the testing was done on a test box where I had intentionally disabled any and all backups because I wanted an easy way to measure how much log file activity reorg caused in total. Like most folks, I do backups of T-Logs that have been written to every 15 minutes on prod boxes. This wasn't a prod box.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - ScottPletcher wrote:
I have trouble even imagining the business or technical case where I'd ever design a table to have massive deletes all over the table at the same time.
You're definitely preaching to the choir there. I didn't design that table nor the processes that drive it. It just seems insane to me to have such massive deletes instead of just avoiding the writes to begin with. Heh... of course, they did a lot of strange things where I work both before I got there and now. We've made a lot of progress fixing some of the older things but tight schedules on new things still prevail and I'm not the one doing the code reviews for half the folks. I have a grand appreciation for being tired. Between ailing family and work, there's not much time for sleep. 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Ah... sorry Sergiy. I just realized that I answered one of your posts and didn't read though the whole post. The post wasn't actually directed to me and I answered it as if it was.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:ScottPletcher wrote:
I have trouble even imagining the business or technical case where I'd ever design a table to have massive deletes all over the table at the same time.
You're definitely preaching to the choir there. I didn't design that table nor the processes that drive it. It just seems insane to me to have such massive deletes instead of just avoiding the writes to begin with. Heh... of course, they did a lot of strange things where I work both before I got there and now. We've made a lot of progress fixing some of the older things but tight schedules on new things still prevail and I'm not the one doing the code reviews for half the folks. I have a grand appreciation for being tired. Between ailing family and work, there's not much time for sleep. 😀
We can't avoid the writes. We must log everything clients do on our system, so that we can use it to troubleshoot later if needed.
When we ran into disk issues, we decided we didn't need more than 1.5 years of logged data online. And, since we keep all db backups for min 10 years now, we decided to just delete it, no other backup needed. Maybe it wasn't ideal, but it was the only relatively easy way I saw to get back a big chunk of space in a short time. Lucky, in a way, that we had so many log tables of such overall size.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- Sergiy wrote:
When you plan to rebuild/reorganise an index you need to answer the main question:
What happens next?
Massive DELETEs on the table imply that there are as massive INSERTs.
What happens to the index(es) after the 1st insert since the latest reorganising?
Is its fragmentation any better than it was before that?
How about the statistics of the reporting queries - what kind of performance gain you get from reindexing the table? If you'd run reports INSTEAD of reindexing - would they all be done long before the reindexing is complete? What's the point then?
If massive deletes leave big chunks of sequential pages empty then new inserts will just fill them up with new data in perfectly organised manner, and, I agree with Jeff on it, reindexing would not be needed at all.
And even if the records would be badly scattered across the random pages in random extents only certain type of queries with specific types of execution plans would suffer from significant performance degradation due to such unfortunate index state. If you have a lot of Clustered Index Scans or Bookmark Lookups you queries performance would not suffer from any kind of index fragmentation.
Clustered index scans should definitely be adversely affected by masses of empty space in pages from deleted rows, since the scan will have to read lots more pages than it otherwise would.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
Viewing 15 posts - 16 through 30 (of 34 total)
You must be logged in to reply to this topic. Login to reply