Index and Statistics Maintenance
-
What are some best practices for maintaining indexes and statistics in SQL Server 2019? I want to ensure that my indexes and statistics are optimized on a regular basis. Are there any specific techniques or tools that are recommended? Any tips or resources would be greatly appreciated!
- Jonathan AC Roberts wrote:
I want to ensure that my indexes and statistics are optimized on a regular basis.
Obviously, two totally different subjects.
I rebuild stats on a nightly database on two of my most active databases just about every night mostly out of paranoia because of all the bloody ever-increasing keyed clustered indexes. I use FULL SCAN because I saw an article (sorry, don't have the link at hand) years ago that demonstrated that if you went more than 25%, it took about the same time as a FULL SCAN and going less than 25 % was mostly futile.
I rebuild stats for the other databases once per week. I don't have any specs to prove that it's worth it. It's one of the few things that I do by rote rather than by reason. I haven't had the time to prove its worth... or lack of worth... yet.
You've seen my posts on index maintenance. I went almost 4 years with no index maintenance and performance got better in the first 3 months and stayed better. The only time I do any index maintenance is for space recovery or when some crank 3rd party insists that they won't look at their crap code for performance issues (or any issue, actually) unless I do the supposed "Best Practice" index maintenance. Actually, I'm usually happy to do so for them because it causes additional and severe blocking due to the rampant page splits that occur after such ill practices are made to happen.
To that point and unlike my rote use of statistics rebuilds, I have proven that logical fragmentation makes no difference even at 99% fragmentation in many of the examples I've built and that page density doesn't make a performance difference. The only difference I've found is in memory usage, which hasn't been serious for us, and disk space, which is also not serious. This is because most of the hits on the clustered indexes are on the last month of data on those and, when it's not, the tables aren't what I'd call "huge". They're substantial but not "huge".
Of course, the NCI are a whole 'nuther story. Most of them fragment like mad and I still don't rebuild them unless they end up with a bothersome enough space savings to be concerned about.
My primary business database is only 1.7 TB (I also have a 3TB "heavy lifter" with some even larger tables for batch imports and the like) and, like most such databases, the largest clustered indexes are of the log/history/audit nature and so the CI's never experience out of order inserts nor any expansive updates... not even in the proverbial hot-spot. The largest CI in that database is 270 GB page compressed. It has the nasty problem of suffering expansive updates in the hot-spot with a shedload of post hot-spot deletes. Back when it was only 147GB non-compressed, I did a backup so I could restore on a test box to do some testing with backups running to simulate the production environment.
I tried doing a REORGANIZE on it because most of the index wasn't fragmented or deleted from. It caused the log file backups during the reorganize to go from trivial to a total of something always around 40MB (in prod) to a whopping 227 GB total during the reorg. It took a incredible 01:20:45 for the reorg (CPU was being used the whole time). The offline REBUILD I did in the BULK LOGGED recovery model afterwards only took a bit less than 13 minutes and 1 log file backup of 23.5GB.
After being plagued with page splits and serious major blocking every Monday morning (I was doing supposed "Best Practice" Index Maintenance on Sunday nights), I simply stopped doing index maintenance (like I said) for nearly 4 years and performance got better in during the first 3 months and stayed there.
As a bit of a side bar, that CI is now 227 GB page compressed (it would be over 600GB non-compressed) and, when I do rebuild it and the 63.3GB of NCI's associated with it, I use the "Swap'n'Drop" method of recreating the indexes to a new file/filegroup (WITH (DROP_EXISTING = ON) and then drop the now empty file group so that I don't have more than 290GB of dead free space in my database from just that one table. That technique also stops an insidious form of fragmentation that I refer to as "interleaving" with other indexes. It's a form of extent fragmentation that will make even a 0% logically fragmented index crawl during scans of even parts of the index. Yeah... I've been working on a demo of that, as well, and the demo proves it.
I do the "Swap'n'Drop" method on a fair number of my larger tables and continue to move a couple a month to use the same method. I'm also considering dropping all static tables into their own file group just to alleviate any "interleaving" on those.
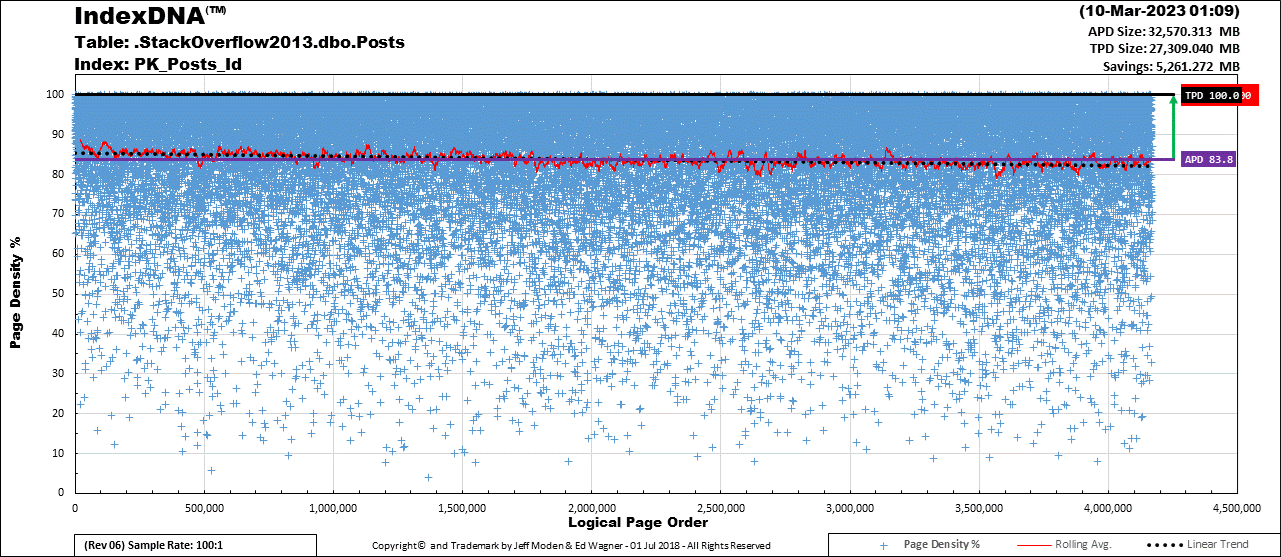
I'm also prone to forcing LOBs out of row with a default of an empty string to keep the "LOB pointer" from causing expansive updates. I also move the bloody "Modified_By" column out of row if it's defaulted to NULL. It "goes for free" because it sits in the parts of pages that the LOBs don't use and I default them to an empty string, as well, because they're frequently the only "ExpAnsive" update (other than the LOBs, which also form "Trapped Short Pages" if allowed to stay in-row). The "Posts" table on the StackOverflow 2013 database that Brent Ozar uses a lot suffers massively from the "Trapped Short Pages" issue. Here's what IndexDNA™ show for that... This is after both a REORGANIZE to compress the LOBs and a REBUILD to fix the damage that REORGANIZE causes. As you can see, it has some serious page density issues due to "Trapped Short Rows". Left as it is, it will NEVER have an APD (Average Page Density) greater than 83.8%. As you can tell by the slight negative slope of the linear trend line (the Black dotted line), things are actually getting worse over time.

There's a whole lot more but, let me summarize by saying, if you're using some form of "generic" index maintenance to supposedly "optimize" your indexes, even if they carry the claim of being "adaptive", then you're doing it wrong, especially if they follow some rule like blindly using REORGANIZE just because the logical fragmentation is between two percentages.
Another thing to consider is whether logical fragmentation actually matters. If you look at all the blogs, articles, and 'tubes on the subject of index maintenance, they all explain fragmentation very well and they all explain (very well) how it COULD cause performance issued BUT NONE OF THEM ACTUALLY PROVE THAT LOGICAL NOR PHYSICAL (PAGE DENSITY) FRAGMENTATION ACTUALLY AFFECTS PERFORMANCE.
I take that back.. Jonathan Kehayias wrote an article back in 2017 that proves that fragmentation DOES affect the execution plan. The funny part was is that the fragmented index performed much better than the defragmented index because the fragmented index had more pages and SQL Server "went parallel" on it but not on the defragmented index. 😀
So... with all of that being said, here's what I recommend as a Best Practice. Keep your statistics up to date and stop doing general index maintenance. ONLY do index maintenance on indexes where you have proven that it makes a substantial difference in performance (that will be approximately zero of your indexes) or you need to do serious space recovery and then be damned careful of how you rebuild those so you don't cause massive page-splits the next day. The other thing to do index maintenance for is to prevent page splits (not cause more, like most people do by mistake) and I touch on that in the "p.s." below.
On April the 20th of 2021, MS finally saw the light and changed their recommendation from that bloody ineffective/damaging 5/30% to something more reasonable, although they still make the serious mistake of not explaining how damaging the use of REORGANIZE actually is. It is NOT capable of clearing the space above the Fill Factor because it cannot and will not create new pages. In fact, it removes free space when you need it the most and so the index fragments even worse after using it.
And, just to drive the point home, Paul Randal, the guy that came up with the 5/30% numbers, wrote an article back in 2008 about where those numbers came from and why. Make sure that you carefully read and understand the very last sentence in that article.
Of course, I'm only speaking about RowStore indexes. ColumnsStore indexes are a whole 'nuther ball o' wax.
p.s. For those of you that have Random GUID clustered indexes, I have the "secret sauce" for you there. 1st, NEVER USE REORGANIZE on them. Second, only REBUILD them and do so when they hit 1% logical fragmentation because that's when they're ready to "avalanche" with massive numbers of page splits. If you want the proof there, please see the following 'tube, where I also destroy what people are calling "Best Practice" Index Maintenance.
https://www.youtube.com/watch?v=rvZwMNJxqVo
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
When it comes to index maintenance, I defer to Jeff.
The only I want to add here is that, as he stated, columnstore is a different ball of wax. Here's a great article by Ed Pollack to cover this part of the problem. It not only gives you good advice, it explains why.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning - Jeff Moden wrote:
I rebuild stats on a nightly database on two of my most active databases just about every night mostly out of paranoia because of all the bloody ever-increasing keyed clustered indexes. I use FULL SCAN because I saw an article (sorry, don't have the link at hand) years ago that demonstrated that if you went more than 25%, it took about the same time as a FULL SCAN and going less than 25 % was mostly futile.
I rebuild stats for the other databases once per week. I don't have any specs to prove that it's worth it. It's one of the few things that I do by rote rather than by reason. I haven't had the time to prove its worth... or lack of worth... yet.
You've seen my posts on index maintenance. I went almost 4 years with no index maintenance and performance got better in the first 3 months and stayed better. The only time I do any index maintenance is for space recovery or when some crank 3rd party insists that they won't look at their crap code for performance issues (or any issue, actually) unless I do the supposed "Best Practice" index maintenance. Actually, I'm usually happy to do so for them because it causes additional and severe blocking due to the rampant page splits that occur after such ill practices are made to happen.
To that point and unlike my rote use of statistics rebuilds, I have proven that logical fragmentation makes no difference even at 99% fragmentation in many of the examples I've built and that page density doesn't make a performance difference. The only difference I've found is in memory usage, which hasn't been serious for us, and disk space, which is also not serious. This is because most of the hits on the clustered indexes are on the last month of data on those and, when it's not, the tables aren't what I'd call "huge". They're substantial but not "huge".
Thanks Jeff, that has reduced my urgency in getting an index maintenance job implemented! We recently moved one of our systems to Amazon AWS and it now runs on RDS SQL Server 2019. It has no index or statistics maintenance jobs and I have the task of implementing them.
Grant, there are only RowStore indexes (no ColumnStore) on the database
What script do you use to update the statistics?
Do you use third-party scripts or just create the jobs yourself from scratch?
- Jonathan AC Roberts wrote:
What script do you use to update the statistics?
I wrote my own little dity. Basically, it skips anything that has been rebuilt in the last 22 hours and it's also a bit of "overkill"... if it "moves" (RowModCtr derivative), I shoot it whether it's the nightly stuff on a couple of the more active databases or the weekly stuff. Again, mostly done out of paranoia than anything else. Doing something like that on AWS may cost you a small fortune in reads. I do have the obvious parameters where I can change that. I don't do a proportional calculation mostly because of ever-increasing indexes keys being so prevalent in our databases. I also do both index and column stats. I should probably change that to just index stats on a nightly basis for the nightly stuff. As some will also warn you, rebuilding stats means that anything that uses them will recompile. That's also a part of my "plan" because of the nature of the indexes and the data that's plowed into them every day. YMMV and most will take rote exception to that.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:Jonathan AC Roberts wrote:
What script do you use to update the statistics?
I wrote my own little dity. Basically, it skips anything that has been rebuilt in the last 22 hours and it's also a bit of "overkill"... if it "moves" (RowModCtr derivative), I shoot it whether it's the nightly stuff on a couple of the more active databases or the weekly stuff. Again, mostly done out of paranoia than anything else. Doing something like that on AWS may cost you a small fortune in reads. I do have the obvious parameters where I can change that. I don't do a proportional calculation mostly because of ever-increasing indexes keys being so prevalent in our databases. I also do both index and column stats. I should probably change that to just index stats on a nightly basis for the nightly stuff. As some will also warn you, rebuilding stats means that anything that uses them will recompile. That's also a part of my "plan" because of the nature of the indexes and the data that's plowed into them every day. YMMV and most will take rote exception to that.
We just pay Amazon a (very large) monthly fee for the database, we pay nothing for disk activity.
Can you share your script?
Causing recompiles might actually help as I think some of the queries had bad execution plans.
-
I had a personally rolled one for statistics I used to use. Then I used, oh gosh, what's her name, used to work for GoDaddy... well anyway, she stopped maintaining it, so, along with most of the rest of the planet, for stats only, I've used Ola's scripts.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning - Grant Fritchey wrote:
I had a personally rolled one for statistics I used to use. Then I used, oh gosh, what's her name, used to work for GoDaddy... well anyway, she stopped maintaining it, so, along with most of the rest of the planet, for stats only, I've used Ola's scripts.
If you're talking about statistics, I agree.
Just don't be tempted to use the Index Maintenance scripts there. It's not that Ola's code is substandard in any way, shape, or form. They do EVERYTHING that everyone that wants to follow something like the old 5/30% methods (formally and, unfortunately, still considered by most to be a "Best Practice"). It's just that doing such things is the wrong way to maintain indexes (especially if they routinely/generically use REORGANIZE).
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jonathan AC Roberts wrote:
Can you share your script?
Attached. Again, I'm very aggressive in the code. If the RowModCtr > 0, then I rebuild the stats. You can certain modify that based on the size of the table. It's my paranoia about all the bloody ever-increasing indexes that we have.
Also note that if you need to stop the run for some reason, it will ignore all of the recently rebuilt stats even if the RowModCtr is > 0 for up to 23 hours. The Min and Max rowcount parameters were mostly so that I could avoid some of the super large tables if I needed to do a quick run.
Do read all the comments before use and, yes... I turn this into a system proc in the master database and include the code to do that, if you wish, in the flower box.
It also has a bunch of conditionals built in to ignore certain schemas a parts of names of tables that I simply ignore because of the type of usage. For example, I don't rebuild stats on tables that contain the word "Audit". They not used often and I let SQL Server handle those during inserts if they are needed at all. That's not as dangerous as it sounds... I stage the data that goes into audit tables so that if someone "accidentally" locks up the table, it doesn't bring the audit trigger to a screeching halt.
Edit... how stupid of me to think that the allowed files types, which include "sql", would actually allow me to attach a .SQL file on an SQL forum. 🙁 Reattaching as a .txt file.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:Jonathan AC Roberts wrote:
Can you share your script?
Attached. Again, I'm very aggressive in the code. If the RowModCtr > 0, then I rebuild the stats. You can certain modify that based on the size of the table. It's my paranoia about all the bloody ever-increasing indexes that we have.
Also note that if you need to stop the run for some reason, it will ignore all of the recently rebuilt stats even if the RowModCtr is > 0 for up to 23 hours. The Min and Max rowcount parameters were mostly so that I could avoid some of the super large tables if I needed to do a quick run.
Do read all the comments before use and, yes... I turn this into a system proc in the master database and include the code to do that, if you wish, in the flower box.
It also has a bunch of conditionals built in to ignore certain schemas a parts of names of tables that I simply ignore because of the type of usage. For example, I don't rebuild stats on tables that contain the word "Audit". They not used often and I let SQL Server handle those during inserts if they are needed at all. That's not as dangerous as it sounds... I stage the data that goes into audit tables so that if someone "accidentally" locks up the table, it doesn't bring the audit trigger to a screeching halt.
Edit... how stupid of me to think that the allowed files types, which include "sql", would actually allow me to attach a .SQL file on an SQL forum. 🙁 Reattaching as a .txt file.
Thanks Jeff, I don't have any proper access to the master database so can't create any stored procedures on it. It is locked down on AWS RDS databases. So I installed the SP on a user database to try it. It is trying to update statistics for system tables and erroring that it can't find the table. Here are the first few rows of the #StatsCmd table:
RAISERROR('Working on 1 of 173: [Test].[sys].[sysxmlplacement] ([cl])',0,0) WITH NOWAIT;
UPDATE STATISTICS [sys].[sysxmlplacement] ([cl]) WITH FULLSCAN;
RAISERROR('Working on 2 of 173: [Test].[sys].[sysxmlplacement] ([nc1])',0,0) WITH NOWAIT;
UPDATE STATISTICS [sys].[sysxmlplacement] ([nc1]) WITH FULLSCAN;
RAISERROR('Working on 3 of 173: [Test].[sys].[sysprufiles] ([_WA_Sys_0000000A_00000018])',0,0) WITH NOWAIT;
UPDATE STATISTICS [sys].[sysprufiles] ([_WA_Sys_0000000A_00000018]) WITH FULLSCAN;
RAISERROR('Working on 4 of 173: [Test].[sys].[sysclsobjs] ([_WA_Sys_00000006_00000040])',0,0) WITH NOWAIT;
UPDATE STATISTICS [sys].[sysclsobjs] ([_WA_Sys_00000006_00000040]) WITH FULLSCAN;
RAISERROR('Working on 5 of 173: [Test].[sys].[sysclsobjs] ([_WA_Sys_00000005_00000040])',0,0) WITH NOWAIT;
UPDATE STATISTICS [sys].[sysclsobjs] ([_WA_Sys_00000005_00000040]) WITH FULLSCAN; -
I updated the procedure (for my purposes) so it doesn't attempt to update stats on the sys schema by updating one of the ANDs in the WHERE to include 'sys':
AND OBJECT_SCHEMA_NAME(stat.object_id) NOT IN ('arch','scratch', 'sys') -
That's probably ok but the sys schema needs "love" as well. 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)

Viewing 12 posts - 1 through 12 (of 12 total)
You must be logged in to reply to this topic. Login to reply