Incrementing ID by one on change of value
-
Hi
I have a table as below, with example data in it
ID Name
2346 M Smith
2346 M Smith
2346 M Smith
2347 M Wilson
2347 M Wilson
3347 M Wilson
I want to add another column called IDAll and do an update on the column so the data would be as follows
ID Name IDAll
2346 M Smith 1
2346 M Smith 1
2346 M Smith 1
2347 M Wilson 2
2347 M Wilson 2
3347 M Wilson 2
Any help would be appreciated
-
Given the ID 3347 value, can you confirm that the grouping should be on Name only?
And how do you determine the order in which the new IDAII values are assigned?
-
Grouping will be on ID, this is not a table ID, IDAll assigned in ID ascending order
- Polynominal wrote:
Grouping will be on ID, this is not a table ID, IDAll assigned in ID ascending order
OK, so ID 3347 should have IDAll = 3 then, shouldn't it?
-
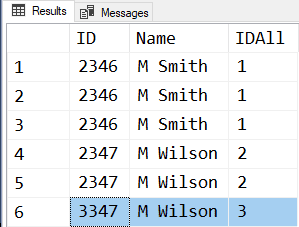
Apologies I have made a right hash of this question and asked it incorrectly.
The result should be like below. so if its the same id and a change of modified data it should increment by 1 as below
ID Name IDAll Modifed Date
2346 M Smith 1 2020-11-16 13:42:27.000
2346 M Smith 2 2020-11-16 14:02:24.000
2346 M Smith 3 2020-11-16 14:02:25.000
2347 M Wilson 1 2020-11-15 14:02:31.000
2347 M Wilson 2 2020-11-16 14:02:31.000
3347 M Wilson 1 2020-11-16 14:02:47.000
- Polynominal wrote:
Hi
I have a table as below, with example data in it
ID Name 2346 M Smith 2346 M Smith 2346 M Smith 2347 M Wilson 2347 M Wilson 3347 M Wilson
I want to add another column called IDAll and do an update on the column so the data would be as follows
ID Name IDAll 2346 M Smith 1 2346 M Smith 1 2346 M Smith 1 2347 M Wilson 2 2347 M Wilson 2 3347 M Wilson 2
Any help would be appreciated
Your test data appears to have an error in it that Phil caught.
Also, please take the time to make "Readily Consumable Data" in the future to help us help you more quickly and easily. Here's just one example of how to do that. Some nearly automatic methods are explained at the first link in my signature line below.
--===== Create and populate the test able on-the-fly.
DROP TABLE IF EXISTS #TestTable --Makes reruns in SSMS easier.
;
SELECT *
INTO #TestTable
FROM (VALUES
(2346,'M Smith')
,(2346,'M Smith')
,(2346,'M Smith')
,(2347,'M Wilson')
,(2347,'M Wilson')
,(3347,'M Wilson') --Included the original typo.
)v(ID,Name)
;
--===== Add the new column
ALTER TABLE #TestTable
ADD IDAll INT
;After that, we can demonstrate that the following code does actually work as advertised.
WITH cte AS
(--===== Select the columns we're going to work with and
-- create the value we want to update each row with.
-- We have to do it this way because you cannot use
-- windowing functions in an UPDATE. A CROSS APPLY
-- may also work but I've never tried it because the
-- method below is pretty simple.
SELECT ID
,IDAll
,IDCAllCalc = DENSE_RANK() OVER (ORDER BY ID)
FROM #TestTable
)--==== Now, UPDATE the column in the CTE using data from the CTE.
UPDATE tgt
SET IDAll = IDCAllCalc
FROM cte tgt
;The results, at this instant, are (which includes the typo in from the original post and is hi-lighted in Blue)...

I say "at this instant" because, if someone were trying to push this through to production to update any real table, I would fail it during "Peer Review". It won't automatically update the IDAll column after any data changes and the code is going to change all existing values upon the introduction of additional ID's that are not greater than all previous IDs nor is there anything to enforce that need.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Building on Jeff's code:
--===== Create and populate the test able on-the-fly.
DROP TABLE IF EXISTS #TestTable --Makes reruns in SSMS easier.
;
SELECT *
INTO #TestTable
FROM
(
VALUES
(2346, 'M Smith', '2020-11-16 13:42:27.000')
,(2346, 'M Smith', '2020-11-16 14:02:24.000')
,(2346, 'M Smith', '2020-11-16 14:02:25.000')
,(2347, 'M Wilson', '2020-11-15 14:02:31.000')
,(2347, 'M Wilson', '2020-11-16 14:02:31.000')
,(3347, 'M Wilson', '2020-11-16 14:02:47.000')
) v (ID, Name, ModifiedDate);
--===== Add the new column
ALTER TABLE #TestTable ADD IDAll INT;
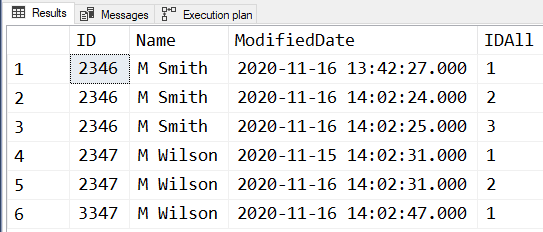
WITH numbered
AS (SELECT tt.ID
,tt.ModifiedDate
,IDAll = ROW_NUMBER() OVER (PARTITION BY tt.ID ORDER BY tt.ModifiedDate)
FROM #TestTable tt)
UPDATE t2
SET IDAll = numbered.IDAll
FROM #TestTable t2
JOIN numbered
ON numbered.ID = t2.ID
AND numbered.ModifiedDate = t2.ModifiedDate;
SELECT *
FROM #TestTable tt; -
I'm afraid that ROW_NUMBER() isn't going to hack it for this problem, Phil. Here's what the output of your code is...
EDIT: My apologies... I stand corrected! I just saw the post that I didn't see before.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Phil, I don't understand why you think you need the self-join in your code. It can still be done in a single scan of the table.
WITH cte AS
(
SELECT ID
,IDAll
,IDCAllCalc = ROW_NUMBER() OVER (PARTITION BY ID ORDER BY ID)
FROM #TestTable
)--==== Now, UPDATE the column in the CTE using data from the CTE.
UPDATE tgt
SET IDAll = IDCAllCalc
FROM cte tgt
;--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Phil, I don't understand why you think you need the self-join in your code.
It's simple, really: I never seem able to remember that you can update a CTE directly!
- Phil Parkin wrote:
Phil, I don't understand why you think you need the self-join in your code.
It's simple, really: I never seem able to remember that you can update a CTE directly!
😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
>>I have a table as below, with example data in it <<
Why did you post any DDL? Do you know what that is? Have you ever read a single book on RDBMS? By definition, not as an option, each row in a table must be different columns that make it different are called a key columns and a key cannot be null. This is usually in the first 2 to 3 chapters of any book on SQL or RDBMS.
Then on top of that, you don't have that there's no such thing as a generic "id"; ; remember your freshman logic class? The whole foundation of all Western thought depends on something called the Law of Identity. This states that to be something you must be something in particular; to be everything in general or nothing in particular, is to be nothing at all. Likewise, there is no such thing as a magic universal generic "name" and RDBMS; it must be the name of something in particular.
When you get around to reading Dr. Codd, will find one of his papers included the concept of a degree of duplication. It's a count of what would have been records in a file, punch cards, etc.
CREATE TABLE Personnel
(emp_id CHAR(4) NOT NULL PRIMARY KEY,
emp_name VARCHAR(20) NOT NULL,
degree_of_duplication INTEGER NOT NULL
DEFAULT 1
CHECK (degree_of duplication > 0)
);
INSERT INTO Personnel
VALUES
('2346', 'M Smith', 3),
('2347', 'M Wilson', 3);
>> I want to add another column called foobar_seq and do an update on the column so the data would be as follows <<
This is still not a table! These are fundamental definitions and you're not getting them right!
Another question is why do you wish to materialize a column that can be computed? I think I can answer that. You don't understand that in RDBMS, a virtual column, such as a view, is just as real to us as a physical column. It simply has the advantage is that it's always correct because it's always recomputed.
CREATE VIEW Foobar
AS
SELECT emp_id, emp_name,
ROW_NUMBER() OVER (PARTITION BY emp_id ORDER BY emp_id) AS foobar_seq
FROM Personnel;
Please post DDL and follow ANSI/ISO standards when asking for help.
Viewing 12 posts - 1 through 12 (of 12 total)
You must be logged in to reply to this topic. Login to reply