Ignore the entire record if a matching record is found
-
Hello,
Kindly guide me with the following code in T-SQL.
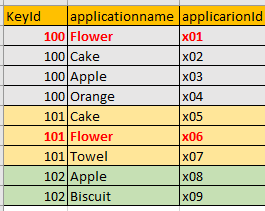
I need to only extract those KeyId where the applicationname = 'Flower' does not exist. So Flower is present in keyId = 100, 101, so in the output I should not have 100 and 101. Just need to display 102.

Thanks.
-
select distinct a.KeyId
from applications a
where not exists (select 1
from applications app
where a.KeyId=app.KeyId
and app.applicationname='Flower');Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
Thank you, Steve. Working like a charm.
By the way, can we tune this to be used like a self join?
Thanks.
-
There are a couple of ways.
The most preferred imo would be to create 'count_grp' using a windowing function and exclude in the WHERE clause of the outer query.
with flower_cte(KeyId, applicationname, applicationId, count_grp) as (
select *, max(case when applicationname='Flower' then 1 else 0 end)
over (partition by KeyId order by (select null))
from applications)
select KeyId, count(*) app_count, max(applicationId) max_app_id,
min(applicationId) min_app_id
from flower_cte fc
where count_grp=0
group by KeyId;It could be done using a LEFT JOIN
with flower_cte(KeyId) as (
select distinct KeyId
from applications
where applicationname='Flower')
select a.KeyId, count(*) app_count, max(a.applicationId) max_app_id,
min(a.applicationId) min_app_id
from applications a
left join flower_cte fc on a.KeyId=fc.KeyId
where fc.KeyId is null
group by a.KeyId;Or it could be done using NOT IN (which I do not prefer)
with flower_cte(KeyId) as (
select distinct KeyId
from applications
where applicationname='Flower')
select a.KeyId, count(*) app_count, max(a.applicationId) max_app_id,
min(a.applicationId) min_app_id
from applications a
where a.KeyId not in(select * from flower_cte)
group by a.KeyId;Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
Heh... as a bit of a sidebar, it's nice to see someone use the term "Record" correctly. 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
Heh... as a bit of a sidebar, it's nice to see someone use the term "Record" correctly. 😀
Has a consensus been reached and record = row? I fear you've invited a taxonomy sermon upon us
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
- Steve Collins wrote:Jeff Moden wrote:
Heh... as a bit of a sidebar, it's nice to see someone use the term "Record" correctly. 😀
Has a consensus been reached and record = row? I fear you've invited a taxonomy sermon upon us
No. I share no such consensus. While a single row CAN be a record, not all rows are records by themselves. In a normalized database, it usually takes more than 1 row in multiple tables to form a "record".
For example, if you look at the OPS table, the 4 rows for KeyID 100 form a "record" as do the 3 rows for keyid 101 and the two rows for key id 102.
It's also one of those "pure" things that's not usually worth fighting over because it usually doesn't matter. I was just impressed to see someone actually use the term in a more correct manner than most folks do for the first time in over a decade.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 7 posts - 1 through 7 (of 7 total)
You must be logged in to reply to this topic. Login to reply