How to remove NULLs from Query Result
-
Hello Community,
Can someone let me know how to remove NULLs from my query result.
I appreciate there are multiple ways to achieve this result without using case statements, however I would like help tweaking the query to exclude NULLs.
The sample data is as follows:
CREATE TABLE employee (
id int,
first_name varchar(50),
last_name varchar(50),
age int,
sex varchar(50),
employee_title varchar(50),
department varchar(50),
salary int,
target int,
bonus int,
email varchar(50),
city varchar(50),
address varchar(50),
manager_id int)
INSERT employee VALUES
(1,'Allen','Wang',55,'F','Manager','Management',200000,0,300,'Allen@company.com','California','23St',1),
(13,'Katty','Bond',56,'F','Manager','Management',150000,0,300,'Katty@company.com','Arizona','',1),
(19,'George','Joe',50,'M','Manager','Management',100000,0,300,'George@company.com','Florida','26St',1),
(11,'Richerd','Gear',57,'M','Manager','Management',250000,0,300,'Richerd@company.com','Alabama','',1),
(10,'Jennifer','Dion',34,'F','Sales','Sales',100000,200,150,'Jennifer@company.com','Alabama','',13),
(18,'Laila','Mark',26,'F','Sales','Sales',100000,200,150,'Laila@company.com','Florida','23St',11),
(20,'Sarrah','Bicky',31,'F','Senior Sales','Sales',200000,200,150,'Sarrah@company.com','Florida','53St',19),
(21,'Suzan','Lee',34,'F','Sales','Sales',130000,200,150,'Suzan@company.com','Florida','56St',19),
(22,'Mandy','John',31,'F','Sales','Sales',130000,200,150,'Mandy@company.com','Florida','45St',19),
(23,'Britney','Berry',45,'F','Sales','Sales',120000,200,100,'Britney@company.com','Florida','86St',19),
(24,'Adam','Morris',30,'M','Sales','Sales',130000,200,100,'Adam@company.com','Alabama','24St',19),
(25,'Jack','Mick',29,'M','Sales','Sales',130000,200,100,'Jack@company.com','Hawaii','54St',19),
(26,'Ben','Ten',43,'M','Sales','Sales',130000,150,100,'Ben@company.com','Hawaii','23St',19),
(27,'Tom','Fridy',32,'M','Sales','Sales',120000,200,150,'Tom@company.com','Hawaii','23St',1),
(28,'Morgan','Matt',25,'M','Sales','Sales',120000,200,150,'Morgan@company.com','Hawaii','28St',1),
(29,'Antoney','Adam',34,'M','Sales','Sales',130000,180,150,'Antoney@company.com','Hawaii','45St',1),
(30,'Mark','Jon',28,'M','Sales','Sales',120000,200,150,'Mark@company.com','Alabama','43St',1),
(2,'Joe','Jack',32,'M','Sales','Sales',100000,200,150,'Joe@company.com','California','22St',1),
(3,'Henry','Ted',31,'M','Senior Sales','Sales',200000,200,150,'Henry@company.com','California','42St',1),
(4,'Sam','Mark',25,'M','Sales','Sales',100000,120,150,'Sam@company.com','California','23St',1),
(5,'Max','George',26,'M','Sales','Sales',130000,200,150,'Max@company.com','California','24St',1),
(8,'John','Ford',26,'M','Senior Sales','Sales',150000,140,100,'Molly@company.com','Alabama','45St',13),
(9,'Monika','William',33,'F','Sales','Sales',100000,200,100,'Molly@company.com','Alabama','',13),
(17,'Mick','Berry',44,'M','Senior Sales','Sales',220000,200,150,'Mick@company.com','Florida','',11),
(12,'Shandler','Bing',23,'M','Auditor','Audit',110000,200,150,'Shandler@company.com','Arizona','',11),
(14,'Jason','Tom',23,'M','Auditor','Audit',100000,200,150,'Jason@company.com','Arizona','',11),
(16,'Celine','Anston',27,'F','Auditor','Audit',100000,200,150,'Celine@company.com','Colorado','',11),
(15,'Michale','Jackson',44,'F','Auditor','Audit',70000,150,150,'Michale@company.com','Colorado','',11),
(6,'Molly','Sam',28,'F','Sales','Sales',140000,100,150,'Molly@company.com','Arizona','24St',13),
(7,'Nicky','Bat',33,'F','Sales','Sales',140000,400,100,'Molly@company.com','Arizona','35St',13)
SELECT * FROM employeeMy query code is as follows:
SELECT
Sub_cities.*
FROM (SELECT
CASE
WHEN employee.first_name = SubQuery.first_name AND
SubQuery.city = 'Arizona' THEN employee.first_name
END AS arizona
,CASE
WHEN employee.first_name = SubQuery.first_name AND
SubQuery.city = 'California' THEN employee.first_name
END AS california
,CASE
WHEN employee.first_name = SubQuery.first_name AND
SubQuery.city = 'Hawaii' THEN employee.first_name
END AS hawaii
FROM (SELECT
employee.id
,employee.first_name
,employee.last_name
,employee.age
,employee.sex
,employee.employee_title
,employee.department
,employee.salary
,employee.target
,employee.bonus
,employee.email
,employee.city
,employee.address
,employee.manager_id
FROM dbo.employee
WHERE employee.city = 'Arizona'
OR employee.city = 'Hawaii'
OR employee.city = 'California') SubQuery
,dbo.employee) Sub_cities
GROUP BY Sub_cities.arizona
,Sub_cities.california
,Sub_cities.hawaiiThanks in advance
-
Man-o-Man, Carton! Nice job on the DDL and test data. It ran perfectly and made my life a whole lot easier to help. Very well done.
Here's one fairly easy answer using what is known as a "CROSSTAB". I've included a couple of links in the code that explain how to use a CROSSTAB, why they're usually better/faster than PIVOT, and how to easily convert them into dynamic CROSSTABs. The code will also do the things you'd expect the code to do if you don't have an even number of names for each "city" and will work with (in this case) any duplicated names within each city as expected, as well. It's also quite easy to add additional columns to.
WITH
cteEnumerate AS
(--==== Assign a "row number" in order to each name for each "city".
SELECT ByCityFirstNameID = ROW_NUMBER() OVER (PARTITION BY City ORDER BY first_name,id)
,first_name
,city
FROM dbo.employee
WHERE city in ('Arizona','California','Hawaii')
)--==== This is known as a "CROSSTAB" and is usually more efficient and is easier to
-- understand than a PIVOT. See the following articles on the subject.
-- https://www.sqlservercentral.com/articles/cross-tabs-and-pivots-part-1-%e2%80%93-converting-rows-to-columns-1
-- https://www.sqlservercentral.com/articles/cross-tabs-and-pivots-part-2-dynamic-cross-tabs
SELECT Arizona = MAX(CASE WHEN city = 'Arizona' THEN first_name ELSE '' END)
,California = MAX(CASE WHEN city = 'California' THEN first_name ELSE '' END)
,Hawaii = MAX(CASE WHEN city = 'Hawaii' THEN first_name ELSE '' END)
FROM cteEnumerate
GROUP BY ByCityFirstNameID
ORDER BY ByCityFirstNameID
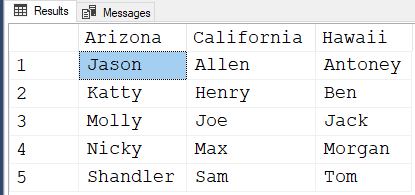
;Here are the results of that code using the test data you provided... Notice that the names within each "city" column are in alphabetical order, as well.

--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
p.s. Since Joe Celko is one of my "followers" (and this site won't allow me to reject certain people as "followers" 🙁 ), if he shows up with his normal tirade about "ID" columns, a bunch of ISO stuff, having a PK, etc, etc, just ignore him. While his advice is correct, he still doesn't understand the concept that your data is just for this post and doesn't reflect what you probably/actually have.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Hi Jeff,
Thanks so much for reaching out. This is beautiful.
The reason I asked if my code could be tweaked to achieve the same resutls as your code, is because I use a 'Query Builder' to assist in compiling my code and it doesn't recognize the 'WITH' statement. Although, I appreciate using the WITH statement is the best way to achieve the result with NULLs.
Therefore, without meaning to sound ungrateful, is it a possible to tweak my code without the WITH statement?
-
Yes...
To be sure, the "WITH" that you speak of is called a "CTE", which stands for "Common Table Expression". In many cases, you can simply move such things to a sub-query in the FROM clause... like this...
SELECT Arizona = MAX(CASE WHEN city = 'Arizona' THEN first_name ELSE '' END)
,California = MAX(CASE WHEN city = 'California' THEN first_name ELSE '' END)
,Hawaii = MAX(CASE WHEN city = 'Hawaii' THEN first_name ELSE '' END)
FROM (--==== Assign a "row number" in order to each name for each "city".
SELECT ByCityFirstNameID = ROW_NUMBER() OVER (PARTITION BY City ORDER BY first_name,id)
,first_name
,city
FROM dbo.employee
WHERE city in ('Arizona','California','Hawaii')
) enum
GROUP BY ByCityFirstNameID
ORDER BY ByCityFirstNameIDThe problem is (and with the understanding that I've not used "query builder" in well over a decade), I don't know if "query builder" will recognize the sub-query. It seemed quite limited according to my memory of it.
As a suggestion for your career (and I did, indeed, follow the same suggestion a long time ago), I would only use query builder to build the parts of a query if I were to use it at all. For example, the query in the cte is a "part" that could be designed as a "standalone" query to begin with. As I said though, practicing to write code without it will be really good for your career even if it's not going to be as a Database Developer or DBA.
As a bit of a sidebar, I wouldn't have guessed that you used "query builder" to create the code you posted. Your code was too nicely formatted to have been a simple copy'n'paste from "query builder", so nicely done there, as well.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Hey Jeff,
Thanks for the lesson.
And this is very nice. I missed the option to do
WHERE city in ('Arizona','California','Hawaii')
Also, not entirely sure how this line works
SELECT ByCityFirstNameID = ROW_NUMBER() OVER (PARTITION BY City ORDER BY first_name,id)
Very nice indeed.
Thanks
-
I wish you would post an actual table. This DDL is not a valid table because it lacks a key. The fact that you named your table "employee" says that you only have one of them! Since the table models a set, it must be a plural or collective noun. I see that you are paying your people in a magical country that does not use decimal currency. I also find it really strange (impossible) that everything is a 50 character string of characters. By definition, identifiers cannot be numeric because you do know calculations with them; they are measured on a nominal scale and should be character strings. Think about what your credit card number divided by three means. Demp_idyou know that an email can be as long as 255 characters? You have no constraints or reference clauses, so you have no data integrity. We don't store age, because that's always changing; we store the birthdate so we can compute the age as needed. In a normalized database. Departments are separate things, which are related by job assignment to an employee. Basically what you've done is transcribe a very crude file system layout into bad SQL.
CREATE TABLE Personnel
(emp_id CHAR(10) NOT NULL PRIMARY KEY,
first_name VARCHAR(35) NOT NULL,
last_name VARCHAR(35) NOT NULL,
birth_date DATE NOT NULL,
sex_code CHAR(1) NOT NULL
CHECK(sex_code IN ('0','1','2','9'));
The international postal Union standard on address line is 35 characters. This is because the standard used to be a 3.5" mailing label, and 10 pitch type. While "DOB" is a common abbreviation for birthdate, it's better to be consistent and follow the ISO 11179 naming rules. The sex code is an ISO standard that has been built into several other codes over the years. Google it
The rest of your schema might look something like this really raw skeleton:
CREATE TABLE Departments
(..);
CREATE TABLE Jobs
(job_title CHAR(15) NOT NULL PRIMARY KEY,
salary_amount DECIMAL(8,2) NOT NULL CHECK (salary_amount >= 0.00),
sales_target_amount DECIMAL(8,2) NOT NULL CHECK (sales_target_amount >= 0.00),
bonus _amount DECIMAL(8,2) NOT NULL CHECK (salary_amount >= 0.00),
employee_email VARCHAR(255) NOT NULL,
..);
CREATE TABLE Job_Assignments
(employee_id CHAR(10) NOT NULL REFERENCE$S Personnel,
job_title CHAR(15) NOT NULL REFERENCES Jobs,
PRIMARY KEY (employee_id, job_title),
city_name VARCHAR(35) NOT NULL,
street_address VARCHAR(35) NOT NULL);p
I'm also very surprised that you don't know the difference between the city and the state in which the city appears.
Your first job would be to just give us something that is correct, at least in first normal form, and internally consistent. Your next step is to see if you can get rid of nulls in your schema, so they never appeared to give you trouble. When you do have nulls, they should have very exact definitions and operational rules within your data model.
Please post DDL and follow ANSI/ISO standards when asking for help.
-
BWAAAAA-HAAAAA-HAAAA!!! See? As predicted including the rubbish about how "identifiers can't be numeric". 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - carlton 84646 wrote:
Hey Jeff,
Thanks for the lesson.
And this is very nice. I missed the option to do
WHERE city in ('Arizona','California','Hawaii')
Also, not entirely sure how this line works
SELECT ByCityFirstNameID = ROW_NUMBER() OVER (PARTITION BY City ORDER BY first_name,id)
Very nice indeed.
Thanks
The ROW_NUMBER() line simply numbers the data. The PARTITION BY City part simply says "Restart the numbering at 1 for each "City". The ORDER BY says that the numbering should be done by first_name and id within each city found by the PARTITION BY. Run just the query in the FROM clause and see what it's doing.
Also, you might want to read up on ROW_NUMBER(). It's known as a "windowing function" and they're incredibly powerful, fast, and useful for a great many things. The following link is a "starter" for you.
https://www.sqlservertutorial.net/sql-server-window-functions/sql-server-row_number-function/
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 9 posts - 1 through 9 (of 9 total)
You must be logged in to reply to this topic. Login to reply