How to calculate idle times for each session
-
Hi All,
We are seeing some stale connections open for long duration and causing blocking chains.
My question is how can track/calculate the idle time for each user session.
For example, lets say spid = 55 has open a transaction and its not yet committed/roll backed its changes. And in meantime,
another session spid = 56 comes and tries to query the same table which is updated in spid =55. So, spid 56 is essentially blocked.
So, want to identify such sessions and calculate the idle time spent by each session where status ='sleeping' or 'awaiting cmd'.
demo code
==========
CREATE TABLE [dbo].[DEPT](
[DEPTNO] [int] NOT NULL primary key,
[DNAME] [varchar](14) NULL,
[LOC] [varchar](13) NULL,
)
INSERT [dbo].[DEPT] ([DEPTNO], [DNAME], [LOC]) VALUES (10, N'ACCOUNTING',N'NEW YORK')
INSERT [dbo].[DEPT] ([DEPTNO], [DNAME], [LOC]) VALUES (20, N'RESEARCH',N'DALLAS')
INSERT [dbo].[DEPT] ([DEPTNO], [DNAME], [LOC]) VALUES (30, N'SALES',N'CHICAGO')
INSERT [dbo].[DEPT] ([DEPTNO], [DNAME], [LOC]) VALUES (40, N'OPERATIONS',N'BOSTON')
GO
spid =55
----------
BEGIN TRAN
UPDATE dept
SET [loc] = 'NEWZEALAND'
WHERE DEPTNO=10; --//updating 1 row and sitting idle
--- ROLLBACK;
spid=56
---------
SELECT * from dept;
Thank you.
Sam
-
Thanks for posting your issue and hopefully someone will answer soon.
This is an automated bump to increase visibility of your question.
-
Can we use lastbatchtime and get the difference between lastbatch and getdate() for this ?
- vsamantha35 wrote:
We are seeing some stale connections open for long duration and causing blocking chains. My question is how can track/calculate the idle time for each user session.
Almost without exception, every post that I've seen on forums that's similar to yours has been with the intent to run the KILL command on those "stale" connections. That can cause some serious delays on top of losing data, etc, etc.
What you really need to do is find out WHO and WHY you have such long winded or possibly forgotten transactions and fix that/those problems. For example, are they being caused by "Connection Leaks", someone forgetting to close a cursor, abhorrent code doing updates in prod with no commit, or some employee that needs a "Come to Jesus" meeting as well as you tightening up your security a LOT?
You need to find and fix the original problem.
And, sorry for the lecture but I've seen how people "solve" this problem with KILL way too many times. I suspect your issue is headed in that same poor direction.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Frankly, speaking my intention was not KILL but want to prove that connections are kept open with locks held and blocking other spids. When we discuss the same with the app team, they say its a database problem. And the worst answer, we got is, going forwared they are implementing query time out itseems. I don't understand , how they get those brilliant ideas.
So, all we want to show them is, it's the application code is not properly handling the txn management. That's why I want to write a DMV so that it can give us idle time of each spid and what locks held by that spid. Challenging part for us, they have defined SLA for some critical quesries as 3 secords and those queries are fired randomly and there is no pattern. Our challenge is we cant keep on running blocked process report every 3 sec and collecting continous server side trace/ extended events to capture those queries. They haven't even given those queries to us. They have given some sample queries from that API call and we have to collect the trace data and we need to look for those set of queries. Already, they are saying queries are slow, SLA 3 secs and running those traces would even put additional stress on those queries and also other queries which dont belong to the database in question.
Also, if we want to collect similar info through sql agent job using sp_whoisactive or other custom queries, the challenge we have is , sql agent schedule is allowing minimum of 10 secs. that means we can do capture only every 10 secs and not less than that. Only if we are lucky enough, we can capture those 3 sec SLA queries. All these queries are JDBC API calls and they are invoked by external customers around the globe. There is no specific time that customer logs in and invoke the functionality where API call is made to database. Its pretty random. Its quite stressfull for us. So, checking for a script to collect those idle times of each Application spid.
Worst part is, they are some app queries, if they KILL or rollback that 1 day or 2 day sleeping transaction, we don't know how much time it would take to rollback and we have Always on with 3 nodes. 2 sync replicas and 1 async replica (DR server).
What we observed is, all these API queries are prepared SQL stmts coming to SQL server, with 50-70 parameters, and they have different different transaction ID's with lot of INSERT's . UPDATES, SELECT.... within same SPID. Other thing is, within a txn as there could be mix of DML+SELECTs , sp_whoisactive and other DMVs show SELECT's blocking UPDATES but actual within that spid and within that transaction id , its the DML operation which took the lock and it is holding it and since SELECT is currently being executed as part of that transaction id / batch / spid , in sql_whoisactive and DMV's sysprocess/dm_exec_requests it is showing SELECT as blocker as it is current executing sql stmt as sql_text. Like these are seeing a lot of blocking.
We also enabled RCSI just to get relief as in readers wont block writers and vice versa. Still we see a lot of blockings.
-
Ah... totally got it. Thank you for the feedback.
Understood on the 3 second SLA but that doesn't seem to be the predominant issue. The 1 or 2 day sleeping spids seem to be the major problem. Since you have sp_WhoIsActive, I'd set it up to capture spids that have a blocking spid and all blocking spids. Once per minute for an hour should provide you with enough info (including the queries involved) to help the devs see the light.
On your original question, I believe the answer is "Yes". It's certainly good enough for the high altitude check you want to do.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
Ah... totally got it. Thank you for the feedback.
Understood on the 3 second SLA but that doesn't seem to be the predominant issue. The 1 or 2 day sleeping spids seem to be the major problem. Since you have sp_WhoIsActive, I'd set it up to capture spids that have a blocking spid and all blocking spids. Once per minute for an hour should provide you with enough info (including the queries involved) to help the devs see the light.
On your original question, I believe the answer is "Yes". It's certainly good enough for the high altitude check you want to do.
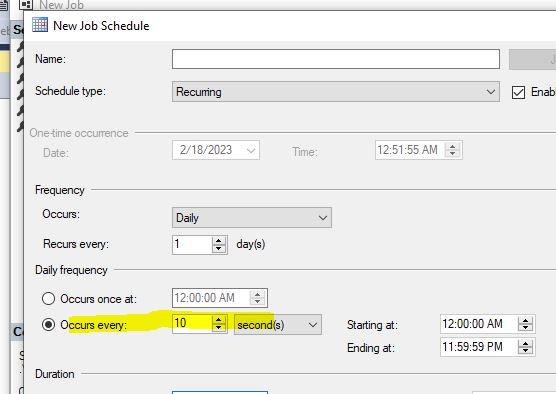
I am having challenge of executing one per minute. SQL Agent Schedule at max it is allowing to capture every 10 secs. Its not allowing me to go below value. Is there any alternative ways so that I can able to execute per min. We have sp_whoisactive in place which is running for every 1 minute.

Thank you.
-
oops.. my bad. once a minute for spids running over day yes.
-
You need to change the selection from seconds to minutes before you can type a "1" in there.
Also, if you already have sp_WhoIsActive running, why are you making another job that does the same thing? Write a stored procedure and then add a step that calls that stored procedure to you existing job.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Hi Jeff,
This is the same sp_whoisactive job which runs every 10 secs. if we are lucky enough sometimes , we are able capture those 3 sec SLA queries. Sorry for the confusion.
- Jeff Moden wrote:vsamantha35 wrote:
We are seeing some stale connections open for long duration and causing blocking chains. My question is how can track/calculate the idle time for each user session.
Almost without exception, every post that I've seen on forums that's similar to yours has been with the intent to run the KILL command on those "stale" connections. That can cause some serious delays on top of losing data, etc, etc.
What you really need to do is find out WHO and WHY you have such long winded or possibly forgotten transactions and fix that/those problems. For example, are they being caused by "Connection Leaks", someone forgetting to close a cursor, abhorrent code doing updates in prod with no commit, or some employee that needs a "Come to Jesus" meeting as well as you tightening up your security a LOT?
You need to find and fix the original problem.
And, sorry for the lecture but I've seen how people "solve" this problem with KILL way too many times. I suspect your issue is headed in that same poor direction.
One question related to transaction management and how long locks being held, suppose a transaction ran for 3 hours with an open_tran_count =2 and it was sleeping for another 3 hours (total 6 hours) with AWAITING COMMAND and if we choose to KILL that stale connection, how long the locks are going to be held ? and is rollback process is single threaded or multi threaded operation?
- vsamantha35 wrote:
Hi Jeff,
This is the sane sp_whoisactive which runs every 10 secs. if we are lucky enough sometimes , we are able capture those 3 sec SLA queries. Sorry for the confusion.
NP. I get it. Paraphrasing Red-Green, "We're all in this together and I'm pullin' for ya".
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 12 posts - 1 through 12 (of 12 total)
You must be logged in to reply to this topic. Login to reply