How to append data to the previous row
-
Hi,
I have a table that stores event transactions, the sample data see the script below. The requirement is to display both Inactive and Reactive events in the same row. The output would be something like this:
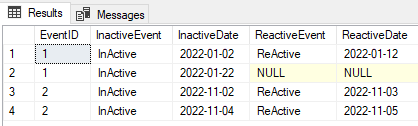
EventId InactiveEvent InactivateDate ReactiveEvent ReactivateDate
1 InActive 2022-01-02 ReActive 2022-01-12
1 InActive 2022-01-22 NULL NULL
2 InActive 2022-11-02 ReActive 2022-11-03
2 InActive 2022-11-04 ReActive 2022-11-05
How do I achieve this?
Thanks!
Sample data script:
If (OBJECT_ID('tempdb..#tbSourceData') is not null) Drop Table #tbSourceData
Create Table #tbSourceData (EventId int, EventStatus varchar(20), RowNum int, UpdatedDate date)
Insert Into #tbSourceData (EventId, EventStatus, RowNum, UpdatedDate)
Values (1, 'InActive', 1, '2022-01-02'),
(1, 'ReActive', 2, '2022-01-12'),
(1, 'InActive', 3, '2022-01-22'),
(2, 'InActive', 1, '2022-11-02'),
(2, 'ReActive', 2, '2022-11-03'),
(2, 'InActive', 3, '2022-11-04'),
(2, 'ReActive', 4, '2022-11-05')
-
I love it when someone posts "Readily Consumable" data along with a crystal clear example of the output that actually contains the same result data that's in the example data... It makes answering the question in the form of code a whole lot easier. Well done.
If the pattern in your data is true to form (especially that incredibly useful RowNum column), then the following code does the trick. The technique is known as a CROSSTAB.
SELECT dat.EventID
,InactiveEvent = MAX(IIF(v.Col=0,dat.EventStatus,NULL))
,InactiveDate = MAX(IIF(v.Col=0,dat.UpdatedDate,NULL))
,ReactiveEvent = MAX(IIF(v.Col=1,dat.EventStatus,NULL))
,ReactiveDate = MAX(IIF(v.Col=1,dat.UpdatedDate,NULL))
FROM #tbSourceData dat
CROSS APPLY (VALUES((RowNum-1)/2,(RowNum-1)%2))v(Grp,Col)
GROUP BY dat.EventID,v.Grp
ORDER BY dat.EventID,v.Grp
;Here are the results of that code using your test data.

--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Nice solution, Jeff.
-
Yes, nice solution Jeff.
Here is an alternative solution:
SELECT datOdd.EventID,
datOdd.EventStatus AS InactiveEvent,
datOdd.UpdatedDate AS InactiveDate,
datEven.EventStatus AS ReactiveEvent,
datEven.UpdatedDate AS ReactiveDate
FROM #tbSourceData datOdd
LEFT JOIN #tbSourceData datEven
ON datEven.EventId = datOdd.EventId
AND datEven.RowNum = datOdd.RowNum + 1
WHERE datOdd.RowNum % 2 = 1
; -
Thank you Johnathan.
-
@ jay-125866 ,
Just to be sure, there are some possibly significant differences between CROSSTAB and the SELF-JOIN methods that have been offered above. The CROSSTAB method does a single pass on the table (less reads) but does a sort. The SELF-JOIN does two scans and, of course, a JOIN.
Both the estimated and actual execution plans (using the very small amount of data provided) produce %_of_Batch numbers that clearly favor the SELF-JOIN but I'll also remind you that those numbers are estimates and real life can be quite different (Grant Fritchey published one of my examples in his early books on execution plans where they were listed as 0% and 100% but real life was exactly the opposite). Both are tried and true methods, and, yes, the proper indexes can make one heck of a difference but we have no clue what the indexes on your actual table are, either.
Since we don't have a lot of test data to help you decide which works best for you, you need to try both in-situ to make sure, at don't allow the estimates even in an actual execution plan decide for you. Since neither of the offerings use a user defined scalar function, SET STATISTICS IO,TIME ON is a good way to measure for which is going to work best in-situ.
Also, if you don't mind, once you've tested, please come back with some additional details and the statistics so we can learn from this, as well. Thanks.
There's also at least one other method (LEAD or LAG) that we could try if neither the CROSSTAB or SELF-JOIN seem performant for you.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jonathan AC Roberts wrote:
Yes, nice solution Jeff.
Here is an alternative solution:
That might be the way to go instead of using the CROSSTAB method on this one, Jonathan.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:Jonathan AC Roberts wrote:
Yes, nice solution Jeff.
Here is an alternative solution:
That might be the way to go instead of using the CROSSTAB method on this one, Jonathan.
Or maybe even using LEAD:
;WITH CTE AS
(
SELECT dat.RowNum,
dat.EventID,
dat.EventStatus AS InactiveEvent,
dat.UpdatedDate AS InactiveDate,
LEAD(dat.EventStatus, 1) OVER (PARTITION BY dat.EventId ORDER BY dat.RowNum ASC) ReactiveEvent,
LEAD(dat.UpdatedDate, 1) OVER (PARTITION BY dat.EventId ORDER BY dat.RowNum ASC) ReactiveDate
FROM #tbSourceData dat
)
SELECT CTE.EventID,
CTE.InactiveEvent,
CTE.InactiveDate,
CTE.ReactiveEvent,
CTE.ReactiveDate
FROM CTE
WHERE CTE.RowNum % 2 = 1
; - Jonathan AC Roberts wrote:
Or maybe even using LEAD:
Yep. I suggested that above as a possible alternative. Thanks for taking the time to write the code for it.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
@ jay-125866 ,
This thread has really gotten interesting with some great alternatives to the classic CROSSTAB method.
Can you provide some additional info about your real table?
- Number of EventID's
- Average number of rows per EventID
- Total number of rows in the table
- Average total row width in the table including any columns you didn't include in the original. We don't need the additional column names. We just need to know the average width of the rows so we can build a test table with the correct average row width.
- Indexes and their structure on the table.
Thank you.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Here is something to set up about 500k rows of test data
If (OBJECT_ID('tempdb..#tbSourceData') is not null) Drop Table #tbSourceData;
--Create Table #tbSourceData (EventId int, EventStatus varchar(20), RowNum int, UpdatedDate date, CONSTRAINT PK_#tbSourceData PRIMARY KEY CLUSTERED (EventId, RowNum))
Create Table #tbSourceData (EventId int, EventStatus varchar(20), RowNum int, UpdatedDate date)
DECLARE @EventCount int = 100000
;WITH CTE AS
(
SELECT a.N EventID,
(ABS(CHECKSUM(NewId())) % 8) + 2 SubEventCount
FROM dbo.fnTally(1, @EventCount) a
)
INSERT INTO #tbSourceData(EventId, EventStatus, RowNum, UpdatedDate)
SELECT EventID,
CASE WHEN e.N%2 = 1 THEN 'InActive' ELSE 'ReActive' END EventStatus,
e.N RowNum,
CONVERT(date,DATEADD(dd, EventID+10+e.N, '20220101')) UpdatedDate
FROM CTE
CROSS APPLY dbo.fnTally(1, CTE.SubEventCount) e
ORDER BY 1,3Then some tests:
DROP TABLE IF EXISTS #x;
DROP TABLE IF EXISTS #y;
DROP TABLE IF EXISTS #z;
GO
SET STATISTICS IO, TIME ON;
GO
SELECT dat.EventID
,InactiveEvent = MAX(IIF(v.Col=0,dat.EventStatus,NULL))
,InactiveDate = MAX(IIF(v.Col=0,dat.UpdatedDate,NULL))
,ReactiveEvent = MAX(IIF(v.Col=1,dat.EventStatus,NULL))
,ReactiveDate = MAX(IIF(v.Col=1,dat.UpdatedDate,NULL))
INTO #x
FROM #tbSourceData dat
CROSS APPLY (VALUES((RowNum-1)/2,(RowNum-1)%2)) v(Grp,Col)
GROUP BY dat.EventID,v.Grp
ORDER BY dat.EventID,v.Grp
GO
SELECT datOdd.EventID,
datOdd.EventStatus AS InactiveEvent,
datOdd.UpdatedDate AS InactiveDate,
datEven.EventStatus AS ReactiveEvent,
datEven.UpdatedDate AS ReactiveDate
INTO #y
FROM #tbSourceData datOdd
LEFT JOIN #tbSourceData datEven
ON datEven.EventId = datOdd.EventId
AND datEven.RowNum = datOdd.RowNum + 1
WHERE datOdd.RowNum % 2 = 1
;
GO
;WITH CTE AS
(
SELECT dat.RowNum,
dat.EventID,
dat.EventStatus AS InactiveEvent,
dat.UpdatedDate AS InactiveDate,
LEAD(dat.EventStatus, 1) OVER (PARTITION BY dat.EventId ORDER BY dat.RowNum ASC) ReactiveEvent,
LEAD(dat.UpdatedDate, 1) OVER (PARTITION BY dat.EventId ORDER BY dat.RowNum ASC) ReactiveDate
FROM #tbSourceData dat
)
SELECT CTE.EventID,
CTE.InactiveEvent,
CTE.InactiveDate,
CTE.ReactiveEvent,
CTE.ReactiveDate
INTO #z
FROM CTE
WHERE CTE.RowNum % 2 = 1 - Jonathan AC Roberts wrote:
Here is something to set up about 500k rows of test data
Then some tests:
You're saving me lot's of time, Jonathan. What are the conclusions of your tests?
p.s. I ask because I'm at work and don't have a lot of free time just now.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:Jonathan AC Roberts wrote:
Here is something to set up about 500k rows of test data
Then some tests:
You're saving me lot's of time, Jonathan. What are the conclusions of your tests?
p.s. I ask because I'm at work and don't have a lot of free time just now.
Without primary key:
CROSSTAB 594 ms
Left join 297 ms
Lead 229 ms
With primary key:
CROSSTAB 597 ms
Left join 265 ms
Lead 160 ms
Lead won.
The primary key only seemed to make a difference on the LEAD solution.
-
So it would seem! Thanks, Jonathan. I'll check later for things like CPU, Reads, Parallelism, and what happens with different indexes.
I take it that the PK you used was keyed on EventID and RowNum and it was a Clustered PK?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
So it would seem! Thanks, Jonathan. I'll check later for things like CPU, Reads, Parallelism, and what happens with different indexes.
I take it that the PK you used was keyed on EventID and RowNum and it was a Clustered PK?
Yes, it's the one in the commented out create table statement.
I just tried it with 11 million rows (I had to create the clustered index after populating the table as it was too slow to populate)
CREATE UNIQUE CLUSTERED INDEX IX_#tbSourceData_1 ON #tbSourceData(EventId, RowNum)and the performance of the different statements changed:CROSSTAB 4121 ms
Left join 3925 ms
Lead 7244 ms
SO LEAD went from first to last.
If (OBJECT_ID('tempdb..#tbSourceData') is not null) Drop Table #tbSourceData;
--Create Table #tbSourceData (EventId int, EventStatus varchar(20), RowNum int, UpdatedDate date, CONSTRAINT PK_#tbSourceData PRIMARY KEY CLUSTERED (EventId, RowNum))
Create Table #tbSourceData (EventId int, EventStatus varchar(20), RowNum int, UpdatedDate date)
DECLARE @EventCount int = 2000000
;WITH CTE AS
(
SELECT a.N EventID,
(ABS(CHECKSUM(NewId())) % 8) + 2 SubEventCount
FROM dbo.fnTally(1, @EventCount) a
)
INSERT INTO #tbSourceData(EventId, EventStatus, RowNum, UpdatedDate)
SELECT EventID,
CASE WHEN e.N%2 = 1 THEN 'InActive' ELSE 'ReActive' END EventStatus,
e.N RowNum,
CONVERT(date,DATEADD(dd, EventID+10+e.N, '20220101')) UpdatedDate
FROM CTE
CROSS APPLY dbo.fnTally(1, CTE.SubEventCount) e
ORDER BY 1,3
CREATE UNIQUE CLUSTERED INDEX IX_#tbSourceData_1 ON #tbSourceData(EventId, RowNum)
SET STATISTICS IO, TIME OFF;
DROP TABLE IF EXISTS #x;
DROP TABLE IF EXISTS #y;
DROP TABLE IF EXISTS #z;
GO
SET STATISTICS IO, TIME ON;
print '**************************************************************************************'
GO
SELECT dat.EventID
,InactiveEvent = MAX(IIF(v.Col=0,dat.EventStatus,NULL))
,InactiveDate = MAX(IIF(v.Col=0,dat.UpdatedDate,NULL))
,ReactiveEvent = MAX(IIF(v.Col=1,dat.EventStatus,NULL))
,ReactiveDate = MAX(IIF(v.Col=1,dat.UpdatedDate,NULL))
INTO #x
FROM #tbSourceData dat
CROSS APPLY (VALUES((RowNum-1)/2,(RowNum-1)%2)) v(Grp,Col)
GROUP BY dat.EventID,v.Grp
ORDER BY dat.EventID,v.Grp
GO
SELECT datOdd.EventID,
datOdd.EventStatus AS InactiveEvent,
datOdd.UpdatedDate AS InactiveDate,
datEven.EventStatus AS ReactiveEvent,
datEven.UpdatedDate AS ReactiveDate
INTO #y
FROM #tbSourceData datOdd
LEFT JOIN #tbSourceData datEven
ON datEven.EventId = datOdd.EventId
AND datEven.RowNum = datOdd.RowNum + 1
WHERE datOdd.RowNum % 2 = 1
;
GO
;WITH CTE AS
(
SELECT dat.RowNum,
dat.EventID,
dat.EventStatus AS InactiveEvent,
dat.UpdatedDate AS InactiveDate,
LEAD(dat.EventStatus, 1) OVER (PARTITION BY dat.EventId ORDER BY dat.RowNum ASC) ReactiveEvent,
LEAD(dat.UpdatedDate, 1) OVER (PARTITION BY dat.EventId ORDER BY dat.RowNum ASC) ReactiveDate
FROM #tbSourceData dat
)
SELECT CTE.EventID,
CTE.InactiveEvent,
CTE.InactiveDate,
CTE.ReactiveEvent,
CTE.ReactiveDate
INTO #z
FROM CTE
WHERE CTE.RowNum % 2 = 1
;

Viewing 15 posts - 1 through 15 (of 39 total)
You must be logged in to reply to this topic. Login to reply