How does SQL determine which column a table level check constraint is applied to
-
Jeff,
I'll take a look at the tally table and the other link you posted. I think this is way beyond my level but I'll look into it and see what I can find out. I'm sure this will help me later, but I'm willing to learn what I can right now.
- michael.leach2015 wrote:
DesNorton,
You mentioned:
The N'xxx' is an indicator that the contents between the quotes is unicode (which is what the function is expecting). The N'U' does in fact indicate a user-defined table.
Thank you for clarifying this. The N being Unicode sounds like the difference between char ( ) and nchar( ) as well as varchar( ) vs. nvarchar( ).
Correct. If you don't use the N'' notation, SQL does an implicit conversion from varchar to nvarchar.
-
Jeff Moden,
I started to read the first link you posted. Before I progress any further, I should understand the concept of splitting. I came across this website which has this code:
CREATE TABLE StudentClasses
(ID INT, Student VARCHAR(100), Classes VARCHAR(100))
GO
INSERT INTO StudentClasses
SELECT 1, 'Mark', 'Maths,Science,English'
UNION ALL
SELECT 2, 'John', 'Science,English'
UNION ALL
SELECT 3, 'Robert', 'Maths,English'
GO
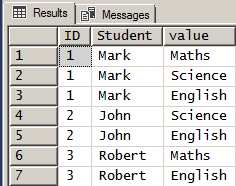
SELECT *
FROM StudentClasses
GOand then this:
SELECT ID, Student, value
FROM StudentClasses
CROSS APPLY STRING_SPLIT(Classes, ',')
GO- In the second block of code, the SELECT statement has a column called value. But the table that was created in the first block of code doesn’t have a column called value. So what is the significance of value in the SELECT statement of the second block of code?
2. Also, in the second block there is the keyword CROSS. Does this mean CROSS JOIN?
- michael.leach2015 wrote:
1. In the second block of code, the SELECT statement has a column called value. But the table that was created in the first block of code doesn’t have a column called value. So what is the significance of value in the SELECT statement of the second block of code?
The code looks at each row of the table and "splits" the "Classes" column based on where the comments are in that column. It does that by "applying" (that's a hint as to the answer for your second question) the STRING_SPLIT() function to "Classes" column in each row of the table. The output of the STRING_SPLIT() function returns the "split out values" as a column called "values" that can be "brought up to" the SELECT statement and used like anything else.
In the process, it does what a lot of people call "Relational Multiplication".
In plain English, for every value that has been split in a given row, it will return a copy of the data in the original table. The number of copies produced are based on the number of values that have been "split out" by the splitter function.
So, for the row that looks like this...
1, 'Mark', 'Maths,Science,English'
... we have an ID of 1 and a Student of "Mark", and a CSV (Comma Separated Values) of 3 classes. What will be returned by the code for that row are 3 copies of the ID and Student followed by one of the split-out values. In other words, the output for that row alone will be...
1, 'Mark', 'Maths'
1, 'Mark', 'Science'
1, 'Mark', 'English'
The other rows would produce a similar effect except that John and Robert would be "copied" by the number of times equal to the number of "elements" or "values" that have been split-out. In both of those cases, John and Robert have only taken 2 classes and so their information would only produce 2 row each.
 michael.leach2015 wrote:
michael.leach2015 wrote:2. Also, in the second block there is the keyword CROSS. Does this mean CROSS JOIN?
You kind of have the right idea but, technically, it's not a CROSS JOIN. It's actually a "Correlated SubQuery" with the correlation being implied by the APPLY. In other words, it's actually a special INNER JOIN. Rather than CROSS JOINing all of the rows in the table with all of the rows that could be produced by the split function, it only joins each row of the table with the results of the function for the given row.
Sidebar: I had a similar confusion when I was first saw the term CROSS APPLY. I don't know why MS named it that way. I wish they had just called it APPLY or maybe INNER APPLY so that the name more closely represented the functionality.
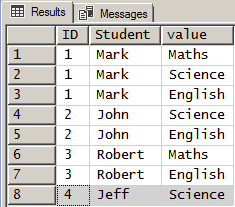
To demonstrate this, lets add two more rows to the example and then run the code. Here are the rows being added and we make no changes to the SELECT code we're running.
INSERT INTO dbo.StudentClasses
(ID,Student,Classes)
SELECT 4, 'Jeff', 'Science'
UNION ALL
SELECT 5, 'Michael', NULL
;When we run the SELECT code, here's what we get for results...
Notice that "Jeff" was only taking one subject and so only one row was produced. Since "Michael" took no classes (he had a NULL), nothing was returned for him.
So this "correlation" of CROSS APPLY isn't actually a Cartesian Product. It basically says, "For each row, split and return 1 row for each item that was split out". If no items were split out, no row is returned.
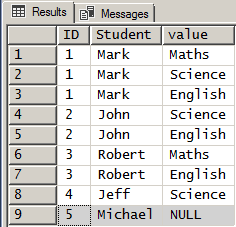
What if we want to clearly show that Michael took no courses? That's where OUTER APPLY comes in.
Think of the rows in the table as the "left table" in a join and the results of the split function as the "right table". Using classic terms, if we did a LEFT OUTER JOIN (I just used LEFT JOIN in my coding and it means the same thing), then all rows in the "left table" would be returned even if the "right table" had no match and that's what OUTER APPLY is like.
So, if we change the code to use an OUTER APPLY instead of a CROSS APPLY, here are the results we get.
... and now we can clearly see that Michael is a student but hasn't taken any courses.
Shifting gears a bit to what we've previous talked about, the code is horrendous format wise and breaks several (mandatory, IMHO) best practices.
- The NULLability of the columns in the table has not been defined.
- Tables, functions, views, etc, etc, should almost ALWAYS be referenced using a 2 part naming convention to prevent possible schema conflicts based on the person using the code.
- An "INSERT column list" should almost ALWAYS be used for INSERTs.
- There are two sources of data in the query but no aliasing has been uses. If object aliases had been properly used, you would have been able to identify where the "values" column was coming from even if you had never seen the split function before.
- The general formatting sucks. Code should almost NEVER suck because of formatting even if the code is otherwise perfect 😀
As with anything else, there are exceptions to such "Best Practice" rules but they are very rare.
And, yeah, before someone "Goes Celko" on this... for a real table, I'd make sure that there was a Primary Key , that the columns were correctly named (the names of the columns don't actually tell you what's in the column and should be fixed) and, of course, the table is totally denormalized in the worst possible ways.
With all that in mind except the stuff in the paragraph above about naming and normalization, here's the way I would have written the code with the understanding the I've moved away from writing code that works equally well in 2005 as it does in later versions.
And, yes... I realize the condition of the code was not your doing. You were just copying what was there. I'm just extending our previous discussion about formatting and using actual "Best Practices" for code here.
--===============================================
-- Create and populate the test table.
-- This is not a part of the solution.
-- We're just setting up test data here.
--===============================================
CREATE TABLE dbo.StudentClasses
(
ID INT NOT NULL
,Student VARCHAR(100) NOT NULL
,Classes VARCHAR(100) NULL
)
;
INSERT INTO dbo.StudentClasses
(ID,Student,Classes)
VALUES (1, 'Mark' , 'Maths,Science,English' )
,(2, 'John' , 'Science,English' )
,(3, 'Robert' , 'Maths,English' )
,(4, 'Jeff' , 'Science' )
,(5, 'Michael', NULL )
;
--===============================================
-- Demonstrate the use of OUTER APPLY.
-- Except for demonstration, I wouldn't
-- include the ID column here.
--===============================================
SELECT ID = sc.ID
,StudentName = sc.Student
,ClassAttended = split.[value]
FROM dbo.StudentClasses sc
OUTER APPLY STRING_SPLIT(Classes, ',') split
ORDER BY ID, ClassAttended
;--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
p.s. Two of the better articles in this world on what APPLY does can be found on Paul White's "author" page. He has some other helpful articles there, as well. Here's the link.
https://www.sqlservercentral.com/author/paul-white
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Jeff,
That was a very clear and thorough explanation. I had to read it twice but I see what you are seeing. I understand the concept. Now I just have to commit it to memory. Thank you for taking the time to write all of that.
I'll take a look at the link also.
Ok, now I'm going back to your article on tally tables.
-
Jeff,
I spent the last 2 days or so on the first article. I got about half way through. I think I understand the concept. One part I couldn't figure out was the following part:
SELECT TOP 11000 --equates to more than 30 years of dates
IDENTITY(INT,1,1) AS N
INTO dbo.Tally
FROM Master.dbo.SysColumns sc1,
Master.dbo.SysColumns sc2You are joining two tables that are the same, dbo.SysColumns. Why did you pick the table called dbo.SysColumns to create the tally table? Why not some other table?
- michael.leach2015 wrote:
Jeff,
I spent the last 2 days or so on the first article. I got about half way through. I think I understand the concept. One part I couldn't figure out was the following part:
SELECT TOP 11000 --equates to more than 30 years of dates
IDENTITY(INT,1,1) AS N
INTO dbo.Tally
FROM Master.dbo.SysColumns sc1,
Master.dbo.SysColumns sc2You are joining two tables that are the same, dbo.SysColumns. Why did you pick the table called dbo.SysColumns to create the tally table? Why not some other table?
Excellent question. I thought I explained it in the article but probably not thorough enough.
The article is actually pretty old. I wrote it when SQL Server 2000 was still the "hot thing" even though it wasn't the "current" thing. dbo.SysColumns was deprecated when SQL Server 2005 came out. Instead of using dbo.SysColumns, you should now use sys.All_Columns, which is the rough equivalent.
Ok, so why sys.All_Columns? The answer is because on a brand new system even without any user data, it's the largest system view there is (as did the old dbo.SysColumns table on old systems). In 2005, sys.All_Columns has at least 4000 rows in it (which is NOT enough to count to 11,000) and a Cartesian Product (as a result of the CROSS JOIN) will easily allow for a return of up to 16 MILLION rows. Since we're using the CROSS JOIN to do nothing but create the "Presence of Rows" as you might with a nested loop and we're not actually reading any data from the object, it's nasty fast... much, much faster than a Cursor or While loop that would do the same thing. This is where the term "Pseudo-Cursor" comes from. It counts like the various forms of "RBAR" but it does so using the near machine language speeds of the underlying loops or "cursors" that create the CROSS JOIN.
As time wears on and more functionality and management view are added to SQL Server, their columns are also added to sys.All_Columns. I forget the "fresh install" count of 2016 for this "table" but it's absolutely huge compared to the original 4000 entries.
There's also a method that I call "Cascading CTEs" (cCTE for short) that you can do similar with. It actually replaces the physical Tally table. The method was first documented by Itzik Ben-Gan (wicked smart dude!) and a lot of us will build one into the code examples we use to help people solve problems on these and other forums. I've recently completed an article about the "Inline Table Valued Function" (a lot of us refer to those simply as "iTVF") and that should be coming out in a couple of weeks. Note that it doesn't tell you how to use it... it just tells you why I used it. The Tally table article you're reading tells you how it works and why you can use it to replace Cursors and While loops.
And, to be sure, yes... I refer to the technique of using the underlying near machine-language loops available in every SELECT, INSERT, UPDATE, an DELETE as a "Psuedo-Cursor", which was coined by R. Barry Young on these very forums. I use to refer to them as "Set Based Loops" but Barry's term is much more to the point and descriptive.
If I were to rewrite the article, I'd use the following code as a method to create the Tally Table and then use that as a segue to teaching what a "Pseudo-Cursor" is and how it can be replaced using cCTEs either inline or as an iTVF. Notice there's no longer a need to refer to the "Master" database because SQL Server makes sys.All_Columns available in every database.
SELECT TOP 11000 --equates to more than 30 years of dates
N = IDENTITY(INT,1,1)
INTO dbo.Tally WITH (TABLOCK)
FROM sys.All_Columns ac1
CROSS JOIN sys.All_Columns ac2
;
ALTER TABLE dbo.Tally
ADD CONsTRAINT PK_Tally PRIMARY KEY CLUSTERED (N)
;--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Jeff,
Thanks for your reply. The more I read your comments, the more these concepts sink in. I may not be able to put it into words but by this point, I'm 95% sure I see what you are saying.
Thanks again for your explanations.
-
Thanks for the feedback, Michael.
My fnTally script was published. I have a link for it in my signature line below.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Jeff,
I will take a look at the tally function article and see what I can find out. It is probably above my skill level but eventually I will need to get there so I will give it a try anyway.
-
Remember that it's a script and not an article. It's not designed to teach either how it works or potential usage. It's simply a script in a repository for people to use and for me to refer others to when I use it so that I don't have to attach it to every post that I use it in.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 12 posts - 16 through 27 (of 27 total)
You must be logged in to reply to this topic. Login to reply