How do we tune a huge DB with ~2TB with huge tables , where do we start ?
-
Forum,
How do we tune a huge DB with ~2TB with huge tables most of them are heaps and some have cluster and non clustered indexes, this is not about query tuning need to implement best practices to run this huge DB efficiently.
Index rebuilt/reorg is in place and working as expected, archiving most unused tables and moving to a separate DB, heap tables im trying to create a PK/Clustered Index, Statistics are being updated and stale unused stats dropped , Unused PK being dropped.
What am i missing and what are any other best practices that can be implemented to make this huge DB run smooth. I did not try compressing the DB file which is a no no
Any pointers much appreciated and thanks in advance
- JSB_89 wrote:
Forum,
How do we tune a huge DB with ~2TB with huge tables most of them are heaps and some have cluster and non clustered indexes, this is not about query tuning need to implement best practices to run this huge DB efficiently.
Index rebuilt/reorg is in place and working as expected, archiving most unused tables and moving to a separate DB, heap tables im trying to create a PK/Clustered Index, Statistics are being updated and stale unused stats dropped , Unused PK being dropped.
What am i missing and what are any other best practices that can be implemented to make this huge DB run smooth. I did not try compressing the DB file which is a no no
Any pointers much appreciated and thanks in advance
I wouldn't use REORGANIZE on such table. You'd be seriously surprised at how many log file transactions it causes on large tables even if there isn't much in the line of logical fragmentation.
Have you looked at "Forwarded Rows" for the heaps?
There's a ton of things that need to be looked at for such large databases. For example, do you have any large "history" or "audit" tables that have ever-increasing keyed clustered indexes that would seriously benefit from page compression?
Have you considered any form of partitioning (I prefer partitioned views for many reasons but people will tell you it's a "Best Practice" to use partitioned tables, instead) for larger such tables so that you can stop backing up partitions that will never have data added to them ever again?
Have you determined the correct Fill Factor for ALL of your indexes or do you still have a bunch at "0"? And, determining the "correct" Fill Factor is easier said than done. Just because an index is fragmenting, doesn't mean it can be fixed by lowering the Fill Factor. In the meantime, I'd be tempted to (and did, for nearly 4 years) stop index maintenance on indexes that you don't actually know about (most of them having a "0" Fill Factor). You might actually be perpetuating fragmentation especially if you're using REORGANIZE at all.
Are you using compressed backups? If not, you should be.
Do you know which tables are suffering from "ExpAnsive" updates and which ones you can fix?
Do you have any LOB columns and have you forced them to go out-of-row AND have a default to prevent the mess they make in your Clustered Index or Heaps? If not, seriously consider doing so.
Have you given any consideration to using "column store" for your larger history/audit tables (which would include such things as InvoiceDetail and other WORM tables)?
Have you moved your larger Clustered Index and Heaps to their own File Groups so you can more easily rebuild them without blowing out your MDF/NDF files using the WITH DROP EXISTING method for index rebuids?
Like I said, there's a ton of things to consider and you're probably not going to get then all from a single post on any forum.... especially since some of the more well advertised "Best Practices" are actually mistakes that everyone has decided to make because they don't realize that one size doesn't actually fit all. 😉
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
@jeff ,
Thanks a lot for these ideas i will do my research on the topics outlined
Moving PK /FK to file groups / Compression/Forwarded Rows i will try to look into these
Fill factor is set to 80% at the instance level and we have 80% set
We use Ola Hallengren’s for compressed backups ..
-
Setting a Fill Factor of 80% across the board is a huge and totally unnecessary waste of memory and disk space especially if you have ever increasing index keys that suffer "ExpAnsive" updates especially on recent inserts that get updated. And, no... Not PK/FK... Clustered Indexes and Non-Clustered index on large tables, which may or may not be PKs or FKs. Once they're moved, you can use a Swap'n'Drop method of bouncing between two file groups during REBUILDs to keep from blowing up you MDF file with a huge amount of unnecessary free space.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thanks again Jeff
Like i mentioned this DB is massive and queries are running fine as expected , issue here is the DB is chewing up massive amounts of disk space and everytime we keep adding 500GB. Of course the data is also piling up which is expected and i believe it was not designed correctly in the first place . Moving forward i want to implement best practices and reclaim storage .
-
So, you're not looking for tuning then, just management?
What about index compression? That's a huge win for some people, depending on your data. Also, columnstore indexes may, emphasize that word, result in reduced data storage, depending on your data, and depending on if using a columnstore is supported by the query patterns (large scale scans, aggregates, that kind of thing). That would be something to explore. I've found the biggest win is in identifying data that just doesn't really need to be there. Deleting it or archiving it to a secondary source is frequently the best thing. Otherwise, I think Jeff covered everything I'd suggest in terms of large scale management.
One huge question though. You said this:
Unused PK being dropped
Unused primary keys? What? With exceptions (that are exceptional), every table should have a primary key. The idea that we're creating lots of tables w/o PKs I would find more than a little concerning. Also, assuming you're following defaults (and no, I don't think we should always), that means the PK is also the cluster, so we'd be creating a big stack of heap tables too. Again, concerning. Am I misunderstanding something here?
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
Understood. A large part of the problem may actually be the 80% Fill Factor thing you folks have done. It actually takes 25% (not just 20%) more space to store things at 80%. I can almost guarantee that you have some large tables where such a Fill Factor is doing nothing but wasting space.
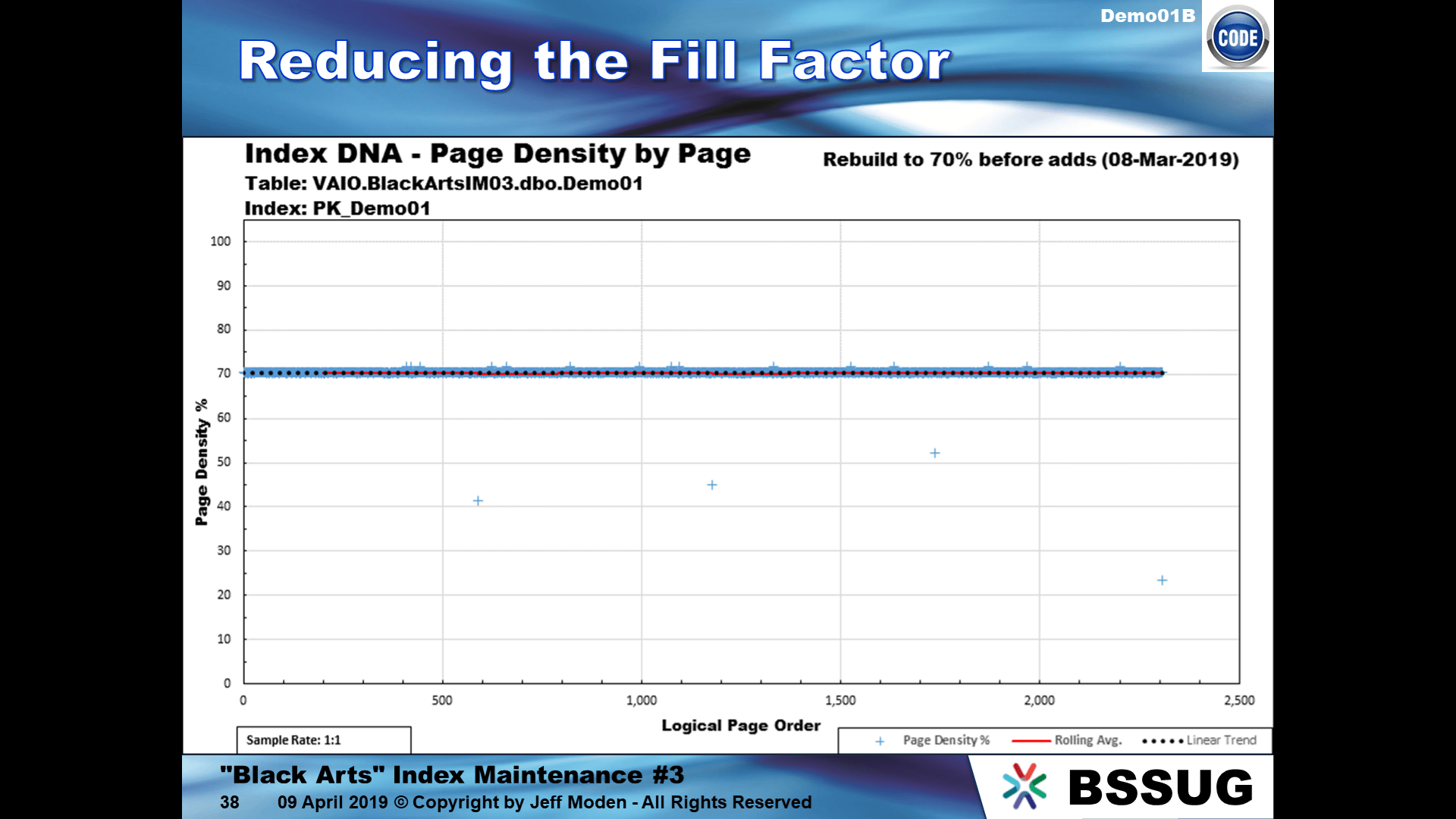
Here's an example of what I'm talking about. Here's an index that was rebuilt at 70%. That number is lower than what you did but the principle is the same.

This is a small clustered index for demo purposes but larger indexes behave the same way. It's also an "ever-increasing" index, which means inserts will go in at the far right of this index. Here's what happens when you do new inserts on such an index...
As you can see, the new rows ignore then Fill Factor and and try to fill each page to the maximum, coming very close to being 100% full. Now, since those are the latest rows, let's see what happens when we update just every 30th row with a simple comment saying it's been processed, which results in every 30th row being expanded a bit...
The newly insert rows had filled in all the pages they lived on to nearly 100% and the updates caused those rows to expand which cause all of those new pages to split to 50% full. As the big Yellow comment says in the graphic above, having a reduced Fill Factor does ABSOLUTELY NOTHING to prevent fragmentation for this kind of index and usage.
This is what I call "ExpAnsive" updates, which are really "ExpEnsive". These type of indexes need to be fixed at the column level.
There's a ton of things like this that are just wasting memory and disk space. This type of thing also wastes a huge amount of transaction log file space because every row that moves during a page split is fully logged. The shorter the rows, the more rows there are that fit on any given page, the more log file usage (and related blocking) occurs.
Unless you fix this, the page splits will continue. If you can't fix them, rebuild them at 97% to use the Fill Factor to identify the index as an "ExpAnsive" update ever-increasing index that you'll someday need to fix. Once you fix them so that they're no longer expansive, rebuild them at 99% to use the Fill Factor to identify that they're ever-increasing and have no "ExpAnsive" updates any more. Once fixed, you won't have to do any index maintenance on them for many months or even several years and they won't be wasting space any more.
p.s. IndexDNA is a trademark of mine.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
@Grant
You are spot on,the removal of the unused PK might have caused creation of big stack of heap tables which i will need to fix moving forward ..
Thanks for you suggestions
-
Thanks again for your valuable inputs and directions .. now i do have robust road map to follow and fix my DB issues ..
Appreciate all your help !!
-
Great. I wish you well on your endeavor.
As a bit of a sidebar, consider documenting the various things you did and writing an article about it here on SSC even (I should say "especially" because problems are frequently the best teachers) if you run into problems. It would be a great help to others as their data gets to be large enough to take on a similar endeavor.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Let's go back to square one. If you have a truly large, large database, then you might want to look at products that were designed to handle such creatures. Teradata and other products were specifically designed to handle the volume. Later we have other products that were designed to handle the volume and velocity problem of large data. I also hate to say this (because I am Mr. SQL), sometimes a non-SQL database is a better solution! Please don't tell mother; she would be so ashamed 🙂
Please post DDL and follow ANSI/ISO standards when asking for help.
-
Yep... let's go back to square one... if they were to move to Teradata and do the same types of things that they've done with their SQL Server, they'd still be in deep Kimchi. 😉 And 2TB isn't that large. Eddie Wuerch has been running with a Peta-Byte or more on SQL Server for a long time.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)


Viewing 12 posts - 1 through 12 (of 12 total)
You must be logged in to reply to this topic. Login to reply