gut check dba's recommendation to increase log to 200gig
-
Hi , log files have always blown my mind. I'll try to explain simply what prompted this post and then ask the community for direction.
we run a 2019 std sql agent job daily early morning mostly made up of 12 steps each responsible for ingesting to our wh sales facts and dimensions from 12 different erp's. One of those erp's is instructed configurationally to always run "full", ie build from scratch daily. On occasion we configure temporarily other erp's to run full when data goes missing and/or bugs are found. We had to do the latter on a 15 million sales row erp. Which has never been a problem before. we inherited a wild multi thread/process ssis architecture that orchestrates from a root pkg in each step which sub pks can run and when. i've concluded that the sales sub pkg runs only after its dimensions are done and that when a full load is requested all fact sales are explicitly deleted (one tran which may be part of a bigger tran) for that erp. In this case that would be 15 million rows of facts alone, ie delete from factsales where erpname=?.
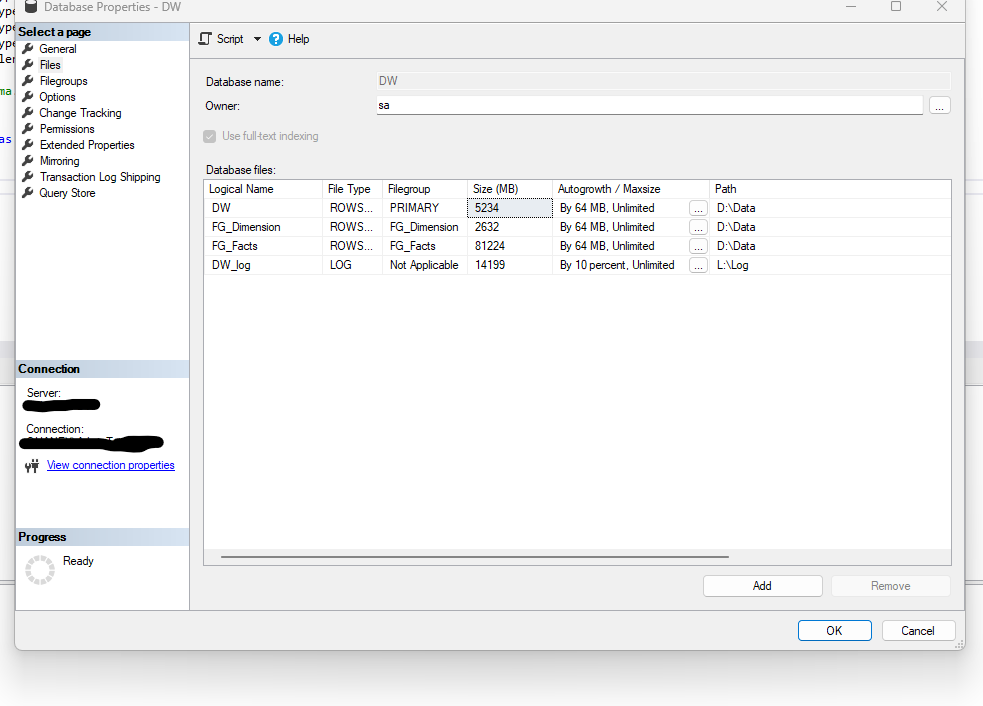
Last week when we did this we basically got errors that the log file was full and we believe it happened right when the deletes on fact sales were occurring. We tried it over and over after multiple attempts on the part of our dba to fix it. I show below some background info. I conservatively estimate that this record alone is 587 bytes. which means the table occupies approximately 8.8 gig. so even if a log file has to contain a before of each deleted record it seems it shouldnt need more than 9 gig at least for that transaction. Granted many more things are going on for each erp. But i looked at the L: drive for that server and see my wh being the most selfish resident (of about 50) in the log folder at 14.5 gig on a drive that uses currently 25.5 of its allocated 100+ gig allocation.
so the dba's remarks probably meant we need to increase the size of the L; drive but that still doesnt sound right. if for now we assume all sql was looking for was 9 gig, it seems my log had plenty of room to grow. And one of the toughest things for me to understand in recovery simple db's like this is why isnt the log file giving back most of its size instead of hogging 14.5 gig in an environment where a simple restore would suffice if we had to go back to yesterday and except for reads the db is idle all day? isnt there a way to truncate what is called the tail of a log since it does us nothing useful after daily etl is run?
so do i blindly agree to 200 more gig allowed to our l: drive? I'll ask him monday if increasing to 200 by adding 100 is what he meant. digging in to change that architecture to do something smarter than deleting millions of records is risky but i suppose is an alternative too. i suppose on the server we just migrated from i can simulate this full load and watch how much log space gets consumed during the process.
I'm looking for advice. I've played with shrinks before but they dont ever seem to do everything one would hope for. They just seem to buy a little time. and what can i do proactively/periodically to see if its time for some more powerful maintenance?

- stan wrote:
...
i've concluded that the sales sub pkg runs only after its dimensions are done and that when a full load is requested all fact sales are explicitly deleted (one tran which may be part of a bigger tran) for that erp. In this case that would be 15 million rows of facts alone, ie delete from factsales where erpname=?.
..
if the fact tables are always fully deleted then change the process to do a truncate instead of deletes - that wont take any log space.
if truncate not possible due to FK constraints then use the switch partition to another temp table with same constraints/indexes (which clears source table, then drop temporary table.
-
Even if your calculate of needing only 18GB for that one transaction is true - you are not accounting for all of the other transactions that can occur at the same time. You stated the process is a multi-threaded SSIS process which means you will have multiple active transactions.
Since your databases are in simple recovery - the method that SQL Server uses to 'clear' the space within the transaction log to be reused does not need a log backup. Once the transaction has completed - the space used in the log for that transaction can be marked as reusable. However, if there is another transaction that is also using that same space but has not yet completed - then that space cannot be marked as reusable. In other words, the virtual log files within the transaction log can only be marked reusable once *all* transactions using that space have completed.
For example - let's say you start a process that takes 1 hour to complete and will consume 18GB of log space. Right after that process starts you kick of another process that takes 2GB and 10 minutes - then another process that takes 5GB and 15 minutes - and another that takes 3 minutes and 1GB. The total space needed will be 26GB and that space is not reusable until the first process has completed.
Since the space cannot be reused (yet) - SQL Server has to extend the log file.
Looking at your configuration - what jumps out is the fact that your log file is incorrectly set to grow at a percentage. That needs to be changed to a fixed MB growth.
I would recommend reviewing that SSIS package and making sure every OLEDB Destination is set with a reasonable commit and batch size. If those are set to the default values - then you end up with a single batch for all rows. That means the single table update of 8.8GB will use at least 8.8GB of log space in a single transaction. If you set the commit and batch sizes - you can control how much of the log will be used before a commit is issued.
In most situations doing this can improve the performance of the process because it is much easier to commit the smaller batches than one large batch.
So - do you need 200GB drive? Maybe - but if you make sure you are committing in smaller batches then you almost certainly won't need any more space than is currently allocated.
Don't forget to reset the growth of the log - which will require shrinking the log to as close to zero as possible and growing it back out at that growth size. See here for how the log growth sizes affect VLF creation: https://learn.microsoft.com/en-us/sql/relational-databases/sql-server-transaction-log-architecture-and-management-guide?view=sql-server-ver16
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
thx frederico, i tried to explain that one erp is always a full, the other 11 are generally (more than 99%) done with an incremental algorithm.
-
thx Jeff, so how do we mark the log reusable after the 12th erp is done? I wasnt clear in my post but should have stated that no one erp starts up until the previous is done. The things that happen in parallel belong to one erp at a time and are presumably dimensional packages for that erp. I will try to get my head around what constitutes a transaction here but wouldnt be surprised to learn that the authors made sure to enlist all things having to do with facts in the same tran as all related dimensions. Wouldnt bet my house on it though. But without something like that tran strategy , the state of the star schema would be "unusable" after any failure. And in the erp that had the issue, the product dimension has one record for every two sales records. I've heard this is because there is a lot of stuff that is made to order.
- stan wrote:
thx frederico, i tried to explain that one erp is always a full, the other 11 are generally (more than 99%) done with an incremental algorithm.
still possible to do - partitioning of tables per ERP - or separate tables/databases even.
depending on volumes of the others, even that would be possible to do by copying data for the others to another temp table, do the switch I mentioned and then switch from this second table back to original. Almost anything is better than doing a delete of 15 million rows if the remaining volumes are smallish. (and 15 million rows for me is small by the way)
a insert into a empty table will most likely be a lot faster than the deletes (even if volume is higher),
regarding log size - Jeffrey already gave a possible explanation - the other one also relates to possible data compression on tables - log entries are uncompressed so they take more space than original table if that one has compression on.
another thing to look for - normally on a DW load, the db is on simple or bulk logging mode - with backup done prior to loads in case something goes wrong - and depending on size of db, even a further backup between loads to allow reverting to one load - this really depends on sizes though.
If the DB you mentioned above is your full DW then this is a tiny DB and backup should only take a few mins to do, and would not require that much space.
this could result is smaller log files overall as as soon as a transaction is finished its space can be reused (if set to simple), or some transactions will take less space (if set to bulk logging).
and if set to Bulk or Full then you need to ensure that trans logs are taken frequently - even more frequent when you are doing the loads, potentially a log backup between each ERP load.
-
thx frederico, not sure but i think our recovery simple choice addresses your point about logging mode. and yes i've seen backups run in seconds on this 105 gig db.
But i didnt understand when you said...
and if set to Bulk or Full then you need to ensure that trans logs are taken frequently - even more frequent when you are doing the loads, potentially a log backup between each ERP load.
did you mean backups of tran logs are taken frequently? I'll mention this to the dba. For sync issues after a problem, and depending on how selective/precise a log based backout to a certain point just before damage was done by one erp can be, this sounds like a cool idea. One challenge we would have is that at the moment the job keeps running to the following steps when there is a problem . The strategy being that we'd like to see as many erps in the wh as possible and deal with erp specific issues later. The job finishes at 5am. GENERALLY, a problem with one erp in this architecture leaves that erp looking no worse than a day old. But i saw something recently that makes me believe there are exceptions.
- stan wrote:
thx frederico, not sure but i think our recovery simple choice addresses your point about logging mode. and yes i've seen backups run in seconds on this 105 gig db.
But i didnt understand when you said...
and if set to Bulk or Full then you need to ensure that trans logs are taken frequently - even more frequent when you are doing the loads, potentially a log backup between each ERP load.
did you mean backups of tran logs are taken frequently? I'll mention this to the dba. For sync issues after a problem, and depending on how selective/precise a log based backout to a certain point just before damage was done by one erp can be, this sounds like a cool idea. One challenge we would have is that at the moment the job keeps running to the following steps when there is a problem . The strategy being that we'd like to see as many erps in the wh as possible and deal with erp specific issues later. The job finishes at 5am. GENERALLY, a problem with one erp in this architecture leaves that erp looking no worse than a day old. But i saw something recently that makes me believe there are exceptions.
apologies I missed where you stated your db's are already in simple recovery - on this case and as Jeffrey mentioned log backup will not make any difference.
but if your normal backup takes a few seconds then adding a step to do it between ERP's would potentially be interesting to you.
any further "improvements" to your process will really depend on how you have it setup - with or without table partitioning, with or without separate tables per ERP and a myriad of other stuff - normally there are ways to improve things - but one needs hands on the process to be able to determine the way forward in each case.
-
Also, you should issue an explicit CHECKPOINT on the db when you want logs to clear. Part of the requirement for freeing log space, SIMPLE recovery, is that a CHECKPOINT has been done on that db. If you think about it, that makes perfect sense, to prevent required data from potentially being lost.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
no problem frederico. your idea about partitioning jumped into my head early on also. i have to read jeff's link before i do anything.
-
thx scott is a checkpoint equivalent "result wise" to setting a log as reusable? i was surprised to hear i needed to set a log as reusable. but i have to read jeff's link to be able to look at this intelligently.
-
The CHECKPOINT is one of the steps required before SQL can mark the existing log space as reusable. Since you're in SIMPLE recovery model, the only thing that could prevent reuse is another active transaction that requires that log space (as Jeffrey already covered).
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
With everything that has been stated so far - I want to touch back on the DBA recommending adding storage to the drive and expanding the transaction logs.
Basically, that is up to the DBA and should not be something you need to be worried about. If the DBA expects the transaction logs located on that drive will grow and fill the drive, then they need to account for that space to make sure there is enough space to handle that growth.
And - if the DBA (or you) are shrinking log files after your processing completes, just for it to grow out again during the next processing cycle then stop doing that.
Regardless of what changes you make - if the processing needs 200GB of log space to succeed, then that is how much is needed. Much better to just allocate the space and leave it alone. The only concern would be how the transaction log(s) are grown to that size - and based on the incorrect growth setting of 10% then you almost certainly have an issue with the number of VLFs in each transaction log.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
appreciated jeffrey but i suspect we are going to make the wrong decision if i dont look closer at this with some of your info at my disposal. i'm trusting but verifying. i asked for proof of the 200 gig calculation and didnt get an answer. i feel that in this area of sql we really need to know what we are doing and why, developers and dbas alike. dba's arent in on every architectural decision. neither are developers.
Viewing 14 posts - 1 through 14 (of 14 total)
You must be logged in to reply to this topic. Login to reply