GUIDs as clustered index
- ScottPletcher - Thursday, May 31, 2018 3:18 PM
Heh... convince management that they should do such a thing as splitting (perhaps even normalizing) a table and they'll remind you that there's not enough time to test all the applications that depend on that table even if there were ROI in doing so. But, you and I both digress.
I'm absolutely agree with you that one should not automatically and blindly assign the CI to an IDENTITY column. I also don't believe that you should necessarily base it on the most common queries because of the likeness to SELECT * and the decrease in performance that goes with it even on relatively normal width tables.
As you say (and I'm known for preaching about), model for overall performance and as I have said and you have now confirmed, that should also include index (and stats) maintenance, backups, restores, etc, etc. No single rule is a panacea when it comes to design. Truly, "It Depends". We're actually "arguing" in support of the same thing. 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Thursday, May 31, 2018 8:32 AM
As Russian proverb says:
With the head taken off no crying for the hair. (СнÑвши голову, по волоÑам не плачут).With column liker "ModifiedOn", "ModifiedBy", "DeletedOn" it's too late to worry about page splits.
And with 2 columns of nvarchar(max) type the identity hot spot is the list of the worries."INSERT-only CIs" you're dreaming about may happen only in well normalised table structure, and, as you said, "try to convince the management".
Dropping number of reads from multi-column tables will require having covering indexes to read the relevant data from.
Those indexes will have to be populated too, when insering data, and they are prone to page splitting as well as the CI.
And then you need to read the data from that badly fragmented covered index , or run index defragmetation continuosly.
Not sure where is the performance gain here.As for a single ID look-up - it does not matter at all if the index on ID is clustered or not.
The lowest level (non-leaf) page of any index will point to the page in CI with relevant data.
No matter what columns are included in that CI._____________
Code for TallyGenerator - Jeff Moden - Thursday, May 31, 2018 11:31 AM
Enterprise. Sorry I have missed that part.
-
First and while I'm waiting for the other info I asked about, a couple of comments about the AMT.ItemVersions table... here's the list of columns you provided along with some comments I made on some of the columns.
Column Suggestions
[Id] [uniqueidentifier] NOT NULL,
[ChangesetId] [uniqueidentifier] NOT NULL,
[Code] [nvarchar](10) NULL, --Makes this table a nasty INSERT/ExpAsive Update table. I'd be strongly temped to change this to an NCHAR(10).
[CreatedAt] [datetimeoffset](0) NOT NULL,
[CreatedBy] [int] NOT NULL,
[DeletedAt] [datetimeoffset](0) NULL,
[DeletedBy] [int] NULL,
[Description] [nvarchar](max) NULL, --Do you really need more than 4000 characters for a description?
[DisplayId] [nvarchar](100) NULL, --If this is an "ID" or reference to a lookup table, do you really need NVARCHAR(100) here?
[InUse] [bit] NOT NULL,
[InternationalStatus] [nvarchar](1) NULL, --This needs to be changed to NCHAR(1) especially because of the NULL
[IsActive] [bit] NOT NULL, --This might be overkill for the same reason that IsDeleted is.
[IsDeleted] [bit] NOT NULL, --This is overkill. If you have a "DeletedBy" present, that will indicate if something is deleted or not.
[IsMandatory] [bit] NOT NULL,
[IsReordered] [bit] NOT NULL,
[ItemId] [uniqueidentifier] NOT NULL,
[ItemTypeId] [uniqueidentifier] NOT NULL,
[ModifiedAt] [datetimeoffset](0) NULL,
[ModifiedBy] [int] NULL,
[PreviousChangesetId] [uniqueidentifier] NULL,
[PropertyBag] [nvarchar](max) NULL, --Do you really need more than 4000 characters for a property bag?
[SequenceNumber] [int] NOT NULL,
[Status] [nvarchar](1) NULL, --This needs to be changed to NCHAR(1) especially because of the NULL
[Title] [nvarchar](200) NULL, --Makes this table a nasty INSERT/ExpAsive UPDATE table.
[UserAction] [nvarchar](2) NULL, --This needs to be change to NCHAR(2) especially because of the NULL
[NewId] [bigint] IDENTITY(1,1) NOT NULL, --Because of the INSERT/ExpAnsive UPDATE columns, this will NOT help prevent fragmentation.The NVARCHAR(1) and NVARCHAR(2) columns are a bit crazy because there is a 2 byte overhead for column length for each of those. As I say above, the should be changed to NCHAR(1) and NCHAR(2) respectively. This will do 3 things... 1) it'll save two bytes for each column instance and 2) it'll make it so the NULLable instances don't add to the INSERT/ExpAnsive UPDATE problem because they'll be fixed length. 3) It'll make up for my recommendation of changing the NULLable NVARCHAR(10) (which also has a 2 byte length overhead) to an NCHAR(10) so that it doesn't add to the INSERT/ExpAnsive UPDATE problem either. The bytes saved here and in the NCHAR(1) and NCHAR(2) conversions will make up a fair bit for this becoming a 10 character (20 byte) column.
The NVARCHAR(200) for TITLE is still going to be a sore spot for the INSERT/ExpAnsive UPDATE problem for this table. The same holds true for the NULLABLE NVARCHAR(100) DisplayId column.
Fill Factor Suggestions
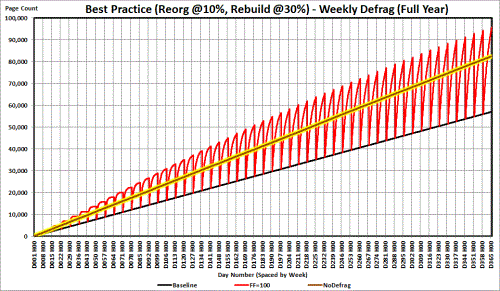
None of your indexes have a declared Fill Factor. That means they're all using the DEFAULT value, which is probably "0" which is the same as a 100% Fill Factor, which is a form of "Death-by-SQL" for non-ever-increasing tables or tables that suffer from the INSERT/ExpAnsive UPDATE problem. It's not a trivial problem, either. Here's what happens to a 123 byte Clustered Index the uses a random GUID as the key if you only defrag once per week.For best viewing of all these charts, right click on them and open them in a new window.

The vertical grid lines in the chart are week separators and the chart shows what happens as a 123 byte CI with a 0/100% Fill Factor (the Red zig-zag line) goes though a growth of just 1,000 rows for 10 hours per day for a year with Index Maintenance occurring once per week. Each upswing is a growth in page count caused by "Bad" page splits which also cause huge amounts (5.5 or more times) log file usage, which takes time to resolve for each insert. During the final week of the year, the table is approaching 3.65 million rows. During that final week, there are 39,779 bad page splits. That's almost 10 bad page splits PER MINUTE (7 days, 10 hours per day) and that's just for ONE INDEX!!!
Every downswing of the Red line is where a REBUILD happens and they're all REBUILDs because of the massive bad page splits causing massive fragmentation. It's worse than shrinking your database every day!
The Black line is if you use NEWSEQUENTIALIDs and never suffer a reboot or restart of the SQL Server instance and is comprised of only "good"/"append only" page splits, which still suck but to a lesser extent than "bad" page splits.
The Brown line with the "golden halo" is what happens if you don't do any index maintenance on the index. It also sucks because it also has "bad" page splits (although a lot less than the 100% Fill Factor and is much more preferable than defragging a 0/100% index).
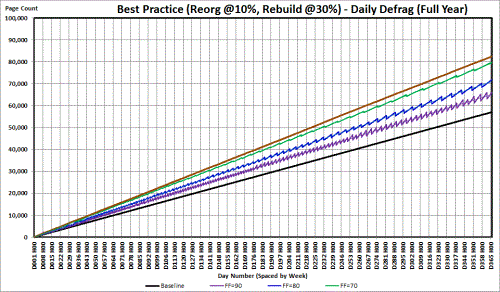
Step One: Do index maintenance daily instead of weekly
If you rebuild daily using the current best practice recommendations, here's what you end up with for multiple different Fill Factors. Remembering that any increase (rise on the chart) is due to bad page splits, which would you pick for the Fill Factor for daily defrags?If you said to yourself "Ummm... they all have page splits and the downward swings indicate where REORGs occurred so they all look like they suck", then you'd have come to the correct conclusion.
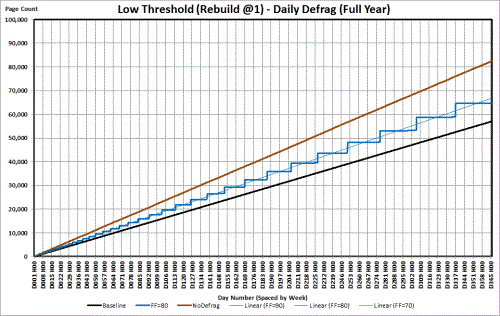
Step 2: REBUILD at 1% Fragmentation instead of ever using REORGANIZE.
If you do your index maintenance daily and you set the threshold to REBUILD (not REORGANIZE) at 1% and the Fill Factor for the "middle of the road" at 80%, here's what happens to the life time of that 123 byte GUID keyed index.
Remember that a rise in the line is due to bad page splits except for the vertical segments on this chart which is where REBUILD allocated extra free space when it reestablished the 80% fill factor. Notice the horizontal flat segments. When there are no page splits at all (good or bad), there will be no increase in page counts and so the flats also indicate when virtually NO fragmentation exists (it REBUILDs at 1%).The REORGANIZES in the chart previous to the one above were happening once a week near the end of the year and they take (not shown on the chart) anywhere from 16 seconds to 49 seconds to run because Reorgs are always single threaded and fully logged.
The REBUILDs in the cart immediately above occurred only once in 4.5 weeks during the same time frame and took between only 6 and 10 seconds each because they can run multi-threaded and minimally logged (BULK LOGGED or SIMPLE Recovery Model required for the minimal logging to occur... and, no, don't use SIMPLE unless that's the way your database started out, which I doubt).
Also notice that the top corners of the line are about where the nearly solid REORGANIZE line was. That also means that you're actually using less memory during most of the duration of the flat "no split" periods (works out to be about 10% less memory usage on average.)
For a non-clustered index just for the GUID, the same method I just recommended would like this this over a 1 year lifetime. Notice the extremely long flats where virtually no page splits occur. During the same timeframe previously mentioned, the REBUILD at 1% fragmentation would only occur once every 8 weeks and take only 2.5 seconds.
And all those times are from when I did this testing on my poor ol' dual core I5 Laptop with only 6GB of ram allocated to SQL Server. Imagine how fast your server could handle this.
Oh yeah... almost forgot. The Black baseline is proof that the conversion to an IDENTITY column is a waste of time. Even though it'll produce only good (fast) page splits, they're still totally unnecessary and will do nothing to help the fragmentation that will occur when those nasty ExpAnsive Updates happen. Because of the random nature of GUIDs, there's a pretty good chance that you won't even be bothered by those types of updates with an 80% Fill Factor and doing Index Maintenance every day with a REBUILD threshold of just 1% fragmentation unless you have wide rows that only allow 10 or 20 rows per page (typically, a Clustered Index). Those might take some human a little time to figure out what is actually best. One strong hint is that logical fragmentation only affects queries that have to read from disk and perform "Read Aheads", which will cause about 7-1/2 times the run duration for an 80% Fill Factor GUID index and a whopping 35 times longer for a GUID index that's never been defragged. Once in memory, the NoDefrag method is a dead heat with the 80% line and the BASELINE (ever increasing GUID) for SELECTs. The only thing that matters then is how much memory you're using/wasting. The NoDefrag line pans out at about a 68% "Natural Fill Factor" which wastes about 32% of the memory but isn't nearly as bad as what happens to a 100% Fill Factor as it rampantly splits each day after it has rebuilt..
Guess I don't need the rest of the information you gave me. Really too bad that some of your tables use that damned NEWSEQENTIALID because they're as bad as an IDENTITY column is for page splits.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - vsamantha35 - Thursday, May 31, 2018 10:22 PM
Excellent... that means that you can do the Rebuilds I propose ONLINE if you need to (although that's a fair bit less efficient than OFFLINE).
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Sergiy - Thursday, May 31, 2018 8:22 PM
Absolutely understood. See the post with the graphs above.
Also, while I don't particularly care for blob datatypes like NVARCHAR(MAX), they DO usually take large, updateable, "free form" text junk out of the Clustered Index making them a lot less obnoxious when it comes to page splits on the CI. As for the NCI's, even GUIDs stand a chance of long periods (8 weeks in my testing) where there are nearly zero page splits which also means nearly zero fragmentation. Heh... to play on your proverb a bit, worry about the hair because even a corpse needs to look good at a funeral. 😀
As for single lookups, I totally agree. Logical fragmentation doesn't matter at all. The only thing that might matter is the page density because, even for just one row, the entire page must be in memory before the row can be retrieved. If most of your pages have resolved to a low natural fill factor or you've caused huge numbers of page splits (a natural fill factor of about 50% right after they split), then even single row lookups can cause slowness if there are a large number of them knocking stuff out of cache.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Thursday, May 31, 2018 8:32 AM
Well, if you're database happens to live in a MPP system, GUID's work great as your main key as it gets hashed evenly across N databases on N nodes. Having sequential keys causes data movement to happen and or data skew.
Food for thought on where GUID's may shine the most. 🙂
- xsevensinzx - Friday, June 1, 2018 7:21 AM
Contrary to most touts of "Best Practices" and opinion, they can also work great on non-MPP systems for the very same reasons. To be sure, I was one of those that thought otherwise in the past.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Friday, June 1, 2018 7:40 AM
On one condition - index padding.
_____________
Code for TallyGenerator -
Definitely need index overhauls. [And wow do you all love guids!] Would you mind running the script below and posting the results? I always prefer to tune including actual SQL usage, and missing index info, rather than just simple table DDL.
At first analysis, I think the clus indexes should be as follows:
(1) [AMT].[ItemVersions] = ( ChangesetId, ItemId ) {most likely, although it's possible it could be just ( ChangesetId ) <or> ( ChangesetId, ItemTypeId ). Can't be absolutely sure without further info.
Also, verify that you really need Unicode for all those columns. Don't you assign the "Code"? Will you ever use "extreme" chars in it? Of course "Description" and certain other columns might truly need Unicode, in which case of course you still use it.(2) [AMT].[ItemTags] = (ParentNewId[, NewId]) (the ParentId = NewId from the ItemVersions table). You don't have to use a guid to clus this table, so there's no reason to. You can still include the parent's guid if you really need it in this table for some very odd reason. Join / lookup using NewId rather than the guids. NewId is optional in the index, but some people don't feel comfortable without a unique clustering key. The table itself doesn't really need an identity, but again, some people panic without their identity crutch in the table.
(3) [Questionnaire].[ItemActions] = (ParentNewId[, NewId]). Same comments as table (2).
DECLARE @table_name_pattern sysname
SET @table_name_pattern = 'item%'SET NOCOUNT ON;
SET DEADLOCK_PRIORITY -8;IF OBJECT_ID('tempdb.dbo.#index_specs') IS NOT NULL
DROP TABLE dbo.#index_specs
IF OBJECT_ID('tempdb.dbo.#index_missing') IS NOT NULL
DROP TABLE dbo.#index_missing
IF OBJECT_ID('tempdb.dbo.#index_usage') IS NOT NULL
DROP TABLE dbo.#index_usageCREATE TABLE dbo.#index_specs (
object_id int NOT NULL,
index_id int NOT NULL,
min_compression int NULL,
max_compression int NULL,
drive char(1) NULL,
alloc_mb decimal(9, 1) NOT NULL,
alloc_gb AS CAST(alloc_mb / 1024.0 AS decimal(9, 2)),
used_mb decimal(9, 1) NOT NULL,
used_gb AS CAST(used_mb / 1024.0 AS decimal(9, 2)),
rows bigint NULL,
table_mb decimal(9, 1) NULL,
table_gb AS CAST(table_mb / 1024.0 AS decimal(9, 2)),
size_rank int NULL,
approx_max_data_width bigint NULL,
UNIQUE CLUSTERED ( object_id, index_id )
)DECLARE @list_missing_indexes bit
DECLARE @include_schema_in_table_names bit
DECLARE @order_by smallint --1=table_name; 2=size; -2=size DESC;.
DECLARE @format_counts smallint --1=with commas, no decimals; 2/3=with K=1000s,M=1000000s, with 2=0 dec. or 3=1 dec. places;.
DECLARE @debug smallint--NOTE: showing missing indexes can take some time; set to 0 if you don't want to wait.
SET @list_missing_indexes = 1
SET @include_schema_in_table_names = 1
SET @order_by = 1
SET @format_counts = 3
SET @debug = 0PRINT 'Started @ ' + CONVERT(varchar(30), GETDATE(), 120)
DECLARE @is_compression_available bit
DECLARE @sql varchar(max)IF CAST(SERVERPROPERTY('ProductVersion') AS varchar(30)) LIKE '9%'
OR (CAST(SERVERPROPERTY('Edition') AS varchar(40)) NOT LIKE '%Developer%' AND
CAST(SERVERPROPERTY('Edition') AS varchar(40)) NOT LIKE '%Enterprise%')
SET @is_compression_available = 0
ELSE
SET @is_compression_available = 1SET @sql = '
INSERT INTO #index_specs ( object_id, index_id,' +
CASE WHEN @is_compression_available = 0 THEN '' ELSE '
min_compression, max_compression,' END + '
alloc_mb, used_mb, rows )
SELECT
base_size.object_id,
base_size.index_id, ' +
CASE WHEN @is_compression_available = 0 THEN '' ELSE '
base_size.min_compression,
base_size.max_compression,' END + '
(base_size.total_pages + ISNULL(internal_size.total_pages, 0)) / 128.0 AS alloc_mb,
(base_size.used_pages + ISNULL(internal_size.used_pages, 0)) / 128.0 AS used_mb,
base_size.row_count AS rows
FROM (
SELECT
dps.object_id,
dps.index_id, ' +
CASE WHEN @is_compression_available = 0 THEN '' ELSE '
ISNULL(MIN(p.data_compression), 0) AS min_compression,
ISNULL(MAX(p.data_compression), 0) AS max_compression,' END + '
SUM(dps.reserved_page_count) AS total_pages,
SUM(dps.used_page_count) AS used_pages,
SUM(CASE WHEN dps.index_id IN (0, 1) THEN dps.row_count ELSE 0 END) AS row_count
FROM sys.dm_db_partition_stats dps ' +
CASE WHEN @is_compression_available = 0 THEN '' ELSE '
INNER JOIN sys.partitions p /* WITH (NOLOCK)*/ ON
p.partition_id = dps.partition_id ' END + '
WHERE dps.object_id > 100
GROUP BY
dps.object_id,
dps.index_id
) AS base_size
LEFT OUTER JOIN (
SELECT
it.parent_id,
SUM(dps.reserved_page_count) AS total_pages,
SUM(dps.used_page_count) AS used_pages
FROM sys.internal_tables it /* WITH (NOLOCK)*/
INNER JOIN sys.dm_db_partition_stats dps /* WITH (NOLOCK)*/ ON
dps.object_id = it.parent_id
WHERE it.internal_type IN ( ''202'', ''204'', ''211'', ''212'', ''213'', ''214'', ''215'', ''216'' )
GROUP BY
it.parent_id
) AS internal_size ON base_size.index_id IN (0, 1) AND internal_size.parent_id = base_size.object_id
'
IF @debug >= 1
PRINT @sql
EXEC(@sql)UPDATE [is]
SET approx_max_data_width = index_cols.approx_max_data_width
FROM #index_specs [is]
INNER JOIN (
SELECT index_col_ids.object_id, index_col_ids.index_id,
SUM(CASE WHEN c.max_length = -1 THEN 16 ELSE c.max_length END) AS approx_max_data_width
FROM (
SELECT ic.object_id, ic.index_id, ic.column_id
--,object_name(ic.object_id)
FROM sys.index_columns ic
WHERE
ic.object_id > 100
UNION
SELECT i_nonclus.object_id, i_nonclus.index_id, ic_clus.column_id
--,object_name(i_nonclus.object_id)
FROM sys.indexes i_nonclus
CROSS APPLY (
SELECT ic_clus2.column_id
--,object_name(ic_clus2.object_id),ic_clus2.key_ordinal
FROM sys.index_columns ic_clus2
WHERE
ic_clus2.object_id = i_nonclus.object_id AND
ic_clus2.index_id = 1 AND
ic_clus2.key_ordinal > 0 --technically superfluous, since clus index can't have include'd cols anyway
) AS ic_clus
WHERE
i_nonclus.object_id > 100 AND
i_nonclus.index_id > 1
) AS index_col_ids
INNER JOIN sys.columns c ON c.object_id = index_col_ids.object_id AND c.column_id = index_col_ids.column_id
GROUP BY index_col_ids.object_id, index_col_ids.index_id
) AS index_cols ON index_cols.object_id = [is].object_id AND index_cols.index_id = [is].index_idUPDATE ispec
SET table_mb = ispec_ranking.table_mb,
size_rank = ispec_ranking.size_rank
FROM #index_specs ispec
INNER JOIN (
SELECT *, ROW_NUMBER() OVER(ORDER BY table_mb DESC, rows DESC, OBJECT_NAME(object_id)) AS size_rank
FROM (
SELECT object_id, SUM(alloc_mb) AS table_mb, MAX(rows) AS rows
FROM #index_specs
GROUP BY object_id
) AS ispec_allocs
) AS ispec_ranking ON
ispec_ranking.object_id = ispec.object_idPRINT 'Index Usage Stats @ ' + CONVERT(varchar(30), GETDATE(), 120)
-- list index usage stats (seeks, scans, etc.)
SELECT
IDENTITY(int, 1, 1) AS ident,
DB_NAME() AS db_name,
--ispec.drive AS drv,
ispec.size_rank, ispec.alloc_mb - ispec.used_mb AS unused_mb,
CASE WHEN @include_schema_in_table_names = 1 THEN OBJECT_SCHEMA_NAME(i.object_id /*, DB_ID()*/) + '.'
ELSE '' END + OBJECT_NAME(i.object_id /*, i.database_id*/) AS Table_Name,
CASE WHEN @format_counts = 1 THEN REPLACE(CONVERT(varchar(20), CAST(dps.row_count AS money), 1), '.00', '')
WHEN @format_counts = 2 THEN CAST(CAST(dps.row_count * 1.0 / CASE ca1.row_count_suffix
WHEN 'M' THEN 1000000 WHEN 'K' THEN 1000 ELSE 1 END AS int) AS varchar(20)) + ca1.row_count_suffix
WHEN @format_counts = 3 THEN CAST(CAST(dps.row_count * 1.0 / CASE ca1.row_count_suffix
WHEN 'M' THEN 1000000 WHEN 'K' THEN 1000 ELSE 1 END AS decimal(14, 1)) AS varchar(20)) + ca1.row_count_suffix
ELSE CAST(dps.row_count AS varchar(20)) END AS row_count,
ispec.table_gb, ispec.alloc_gb AS index_gb,
SUBSTRING('NY', CAST(i.is_primary_key AS int) + CAST(i.is_unique_constraint AS int) + 1, 1) +
CASE WHEN i.is_unique = CAST(i.is_primary_key AS int) + CAST(i.is_unique_constraint AS int) THEN ''
ELSE '.' + SUBSTRING('NY', CAST(i.is_unique AS int) + 1, 1) END AS [Uniq?],
REPLACE(i.name, oa1.table_name, '~') AS index_name,
--fc_row_count.formatted_value AS row_count,
i.index_id,
ispec.approx_max_data_width AS [data_width],
CAST(CAST(ispec.used_mb AS float) * 1024.0 * 1024.0 / NULLIF(dps.row_count, 0) AS int) AS cmptd_row_size,
key_cols AS key_cols,
LEN(nonkey_cols) - LEN(REPLACE(nonkey_cols, ';', '')) + 1 AS nonkey_count,
nonkey_cols AS nonkey_cols,
ius.user_seeks, ius.user_scans, --ius.user_seeks + ius.user_scans AS total_reads,
ius.user_lookups, ius.user_updates,
dios.leaf_delete_count + dios.leaf_insert_count + dios.leaf_update_count as leaf_mod_count,
dios.range_scan_count, dios.singleton_lookup_count,
DATEDIFF(DAY, STATS_DATE ( i.object_id , i.index_id ), GETDATE()) AS stats_days_old,
DATEDIFF(DAY, CASE
WHEN o.create_date > cj1.sql_startup_date AND o.create_date > o.modify_date THEN o.create_date
WHEN o.modify_date > cj1.sql_startup_date AND o.modify_date > o.create_date THEN o.modify_date
ELSE cj1.sql_startup_date END, GETDATE()) AS max_days_active,
dios.row_lock_count, dios.row_lock_wait_in_ms,
dios.page_lock_count, dios.page_lock_wait_in_ms,
ius.last_user_seek, ius.last_user_scan,
ius.last_user_lookup, ius.last_user_update,
fk.Reference_Count AS fk_ref_count,
i.fill_factor,
ius2.row_num,
CASE
WHEN ispec.max_compression IS NULL THEN '(Not applicable)'
WHEN ispec.max_compression = 2 THEN 'Page'
WHEN ispec.max_compression = 1 THEN 'Row'
WHEN ispec.max_compression = 0 THEN ''
ELSE '(Unknown)' END AS max_compression,
ius.system_seeks, ius.system_scans, ius.system_lookups, ius.system_updates,
ius.last_system_seek, ius.last_system_scan, ius.last_system_lookup, ius.last_system_update,
GETDATE() AS capture_date
INTO #index_usage
FROM sys.indexes i /*WITH (NOLOCK)*/
INNER JOIN sys.objects o /*WITH (NOLOCK)*/ ON
o.object_id = i.object_id
CROSS JOIN (
SELECT create_date AS sql_startup_date FROM sys.databases /*WITH (NOLOCK)*/ WHERE name = 'tempdb'
) AS cj1
OUTER APPLY (
SELECT CASE WHEN EXISTS(SELECT 1 FROM #index_specs [is] WHERE [is].object_id = i.object_id AND [is].index_id = 1)
THEN 1 ELSE 0 END AS has_clustered_index
) AS cj2
LEFT OUTER JOIN dbo.#index_specs ispec ON
ispec.object_id = i.object_id AND
ispec.index_id = i.index_id
OUTER APPLY (
SELECT STUFF((
SELECT
'; ' + COL_NAME(ic.object_id, ic.column_id)
FROM sys.index_columns ic /*WITH (NOLOCK)*/
WHERE
ic.key_ordinal > 0 AND
ic.object_id = i.object_id AND
ic.index_id = i.index_id
ORDER BY
ic.key_ordinal
FOR XML PATH('')
), 1, 2, '')
) AS key_cols (key_cols)
OUTER APPLY (
SELECT STUFF((
SELECT
'; ' + COL_NAME(ic.object_id, ic.column_id)
FROM sys.index_columns ic /*WITH (NOLOCK)*/
WHERE
ic.key_ordinal = 0 AND
ic.object_id = i.object_id AND
ic.index_id = i.index_id
ORDER BY
COL_NAME(ic.object_id, ic.column_id)
FOR XML PATH('')
), 1, 2, '')
) AS nonkey_cols (nonkey_cols)
LEFT OUTER JOIN sys.dm_db_partition_stats dps /*WITH (NOLOCK)*/ ON
dps.object_id = i.object_id AND
dps.index_id = i.index_id
LEFT OUTER JOIN sys.dm_db_index_usage_stats ius /*WITH (NOLOCK)*/ ON
ius.database_id = DB_ID() AND
ius.object_id = i.object_id AND
ius.index_id = i.index_id
LEFT OUTER JOIN (
SELECT
database_id, object_id, MAX(user_scans) AS user_scans,
ROW_NUMBER() OVER (ORDER BY MAX(user_scans) DESC) AS row_num --user_scans|user_seeks+user_scans
FROM sys.dm_db_index_usage_stats /*WITH (NOLOCK)*/
WHERE
database_id = DB_ID()
--AND index_id > 0
GROUP BY
database_id, object_id
) AS ius2 ON
ius2.database_id = DB_ID() AND
ius2.object_id = i.object_id
LEFT OUTER JOIN (
SELECT
referenced_object_id, COUNT(*) AS Reference_Count
FROM sys.foreign_keys /*WITH (NOLOCK)*/
WHERE
is_disabled = 0
GROUP BY
referenced_object_id
) AS fk ON
fk.referenced_object_id = i.object_id
LEFT OUTER JOIN (
SELECT *
FROM sys.dm_db_index_operational_stats ( DB_ID(), NULL, NULL, NULL )
) AS dios ON
dios.object_id = i.object_id AND
dios.index_id = i.index_id
OUTER APPLY (
SELECT OBJECT_NAME(i.object_id/*, DB_ID()*/) AS table_name
--, CASE WHEN dps.row_count >= 1000000 THEN 'M' WHEN dps.row_count >= 1000 THEN 'K' ELSE '' END AS row_count_suffix
) AS oa1
CROSS APPLY (
SELECT CASE WHEN dps.row_count >= 1000000 THEN 'M' WHEN dps.row_count >= 1000 THEN 'K' ELSE '' END AS row_count_suffix
) AS ca1WHERE
i.object_id > 100 AND
i.is_hypothetical = 0 AND
i.type IN (0, 1, 2) AND
o.type NOT IN ( 'IF', 'IT', 'TF', 'TT' ) AND
(
o.name LIKE @table_name_pattern AND
o.name NOT LIKE 'dtprop%' AND
o.name NOT LIKE 'filestream[_]' AND
o.name NOT LIKE 'MSpeer%' AND
o.name NOT LIKE 'MSpub%' AND
--o.name NOT LIKE 'queue[_]%' AND
o.name NOT LIKE 'sys%'
)
ORDER BY
db_name,
CASE WHEN @order_by IN (-2, 2) THEN ispec.size_rank * -SIGN(@order_by) ELSE 0 END,
--ius.user_scans DESC,
--ius2.row_num, --user_scans&|user_seeks
table_name,
-- list clustered index first, if any, then other index(es)
CASE WHEN i.index_id IN (0, 1) THEN 1 ELSE 2 END,
key_colsSELECT *
FROM #index_usage
ORDER BY identPRINT 'Ended @ ' + CONVERT(varchar(30), GETDATE(), 120)
SET DEADLOCK_PRIORITY NORMAL
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
For [AMT].[ItemVersions] :
If [Description] and [PropertyBag] are (1) used more than rarely *and* (2) are used in at least 1 time-critical task *and* (3) for a majority of rows, they fit within the page, then leave them in the main table. Otherwise, strongly consider forcing them out of the main table, to overflow pages. Edit: Btw, to force that, run proc sp_tableoption '<table_name>', 'large value types out of row', 1. Sorry, DBA too long, forget to provide details on these types of things for non-DBAs.For all tables, do a compressed data savings estimate to see if page compression would significantly reduce the size.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Thanks all. Special thanks to Jeff & Scott for valuable inputs. Loads of pouring knowledge. Never thought, so much goes into the database design. I am going to test this in our environment.
- ScottPletcher - Friday, June 1, 2018 1:41 PM
Awesome suggestion on the blobs, Scott. Get them the heck out of the CI, especially if they're a part of expansive updates.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Sergiy - Friday, June 1, 2018 7:53 AM
Great point/tip. Thanks. It's normally not a big problem because of the ratio of the intermediate pages in the BTree to the Leaf Level but, considering the comparatively low number of pages, why tolerate intermediate page splits? Padding the index would make that problem go away and it's a real low cost to do it.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - ScottPletcher - Friday, June 1, 2018 1:10 PM
All these index suggestions are good, but a little bird on a tree out of my window sings that all the queries they're are running have IsDeleted = 0 as a part of WHERE clause.
If the bird is right, it would be quite useful to have IsDeleted as a first column in a clustered index.
It would be especially useful, if non-deleted sets make <20% of all records._____________
Code for TallyGenerator
Viewing 15 posts - 31 through 45 (of 59 total)
You must be logged in to reply to this topic. Login to reply