getting started paas SSAS
-
hi our on prem STD implementation of SSAS currently occupies about 3.6 gig of space (projected to double in the next year or two) in the larger sales tabular model when/after processed and only a fraction of that in a smaller db that probably never should have been a cube.
I think it was jeff modem who taught me in this forum that while its processing, as much as 3 times that space can be temporarily required. Which i verified by watching resource consumption while it was processing many months ago.
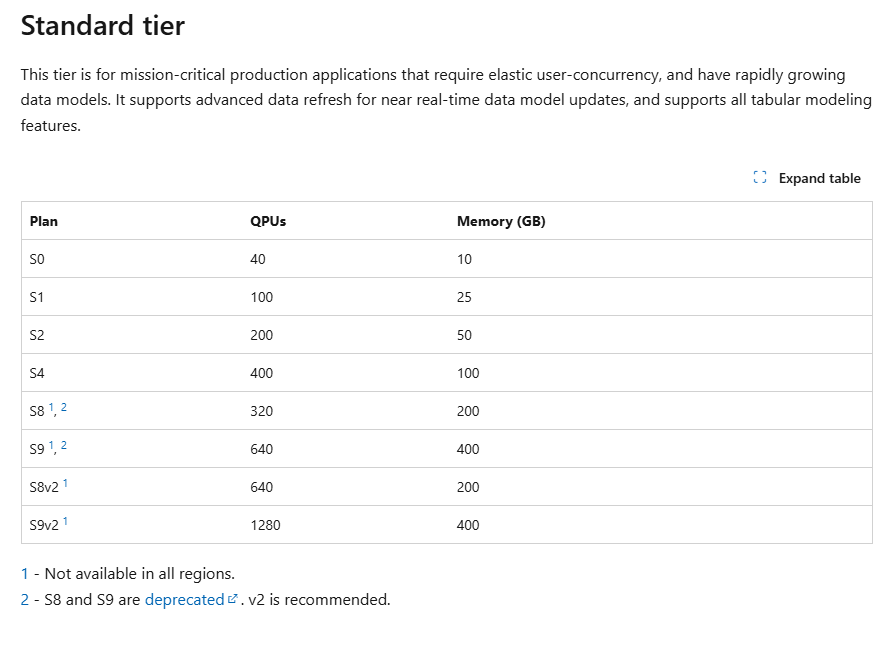
Because of acquisitions in different time zones, we believe its time to start using ssas incrementally instead of processing full each day like we do today. I looked at ssas as a paas at https://learn.microsoft.com/en-us/azure/analysis-services/analysis-services-overview and believe what im reading to be saying that neither the dev nor the basic tier would be useful to us. That rather the standard would be the only one useful to us. as you can see in the image below, there is immediate confusion because the memory shown in plan S0 is probably not enough for those rare occasions when we'd want to process full.
Can the community tell me if that memory figure is during processing or after? My understanding is that requested (resource) increases in the paas are always allowed but never decreases. I should also mention we expect other business areas like procurement to jump on the tabular model bandwagon asking for their own tabular model dbs in the next year or two, doubling the projected double figure i mentioned above. I dont know what a QCPU is but am sure we arent getting anywhere near capacity in terms of queries against our cubes today. Also im a big fan of unattended XAAP and XAAS etc products but is my tenent engineer going to ask me what other features beside "plan" I'll be wanting?

-
Not sure about the Azure piece, we tried it about 10 years ago and I think the SSAS as a service wasn't released yet, so we installed SSAS on a VM. When you process a measure group or partition, the new data is loaded into memory with the ability to roll back to the old version if anything fails. This is why the memory increases by at least 100%. If you are confident or have a fail-over sever you can process empty first to release memory. I'm not sure if it helps, but you can also process data separately from processing indexes and you can limit the number of parallel operations to alleviate some memory pressure.
We partition our tabular facts using the same effective partition function as the database fact tables. Our facts are clustered column stores, primarily to save space. We do perform updates against the facts which leaves the row groups with many "deleted" rows. We have 7 or 8 years worth of data in the fact tables, but everything before the current closed data is static. This means we can rebuild the clustered columnstore on the 10 or so open partitions which doesn't impact memory significantly and cleans up all the data that goes through the deltastore. The fact table partitions and tabular dims/partitions are maintained in a handful of metadata tables that include modelname, processing level (dim or partition), table name, index name, date boundaries, source query, final query etc. This allows two things: first we can develop TMSL scripts to process dims only, and to process update the open period fact partitions. It also allows us to generate code to split the table partition function and create new fact partitions with associated tabular partitions at the end of every month. It also allows us to generate clustered column store partition maintenance scripts so that the row groups contain the maximum number of rows.
The final part is a using powershell script to read the tabular model partitions and compare them with the metadata. This part is not essential, but without it the tabular process can be tricky to resume after failure. Again this might not be much relevance to using SAAS as a service in Azure, but it does allow piecemeal processing of partitions to limit memory use. You can also run a full process in the same way, although a process empty might be all you need.
-
thx Ed. That was useful to me. We also stood up ssas on a vm as part of a dev sql server. But are convinced separating duties between the engine and ssas is the only strategy long term.
We also split processing up into pieces parts on our prod "on prem" sql server achieving "process full " but skirting issues we had a year or 2 ago with space. Actually, i'm pretty sure it was space, not memory but wouldnt swear to it. So that brings up even more questions about what ms is telling us about each of the plans in that link. Its kind of sad that that you have to go right to std to be sure your biggest issues will be solved. Even though MS says in its doc that starting with developer will allow you to mitigate concerns. Baloney.
so this post is about paas, and i do have concerns about going all in not knowing if the additional horsepower it claims to offer will allow us to sleep a bit better at night. Both from a processing and at rest memory resource perspective.
Viewing 3 posts - 1 through 3 (of 3 total)
You must be logged in to reply to this topic. Login to reply