From each string, extract numbers following a '#' and create separate row
-
Hi there,
This was posted in the wrong forum, hence duplicating here. I have SQL version 2019 (thanks to Phil, Scott and Steve for their previous inputs).
I've tried CROSS APPLY, PATINDEX and many other functions, but can't nail this.
For each record, I want to extract all numbers which follow a '#' and then create a new row for each.
Example String 1: "Hello world. #1234 has been replaced by #014521"
To return:
1234
014521
Example String 2: "#687459"
To return:
687459
If there is no '#', then return blank.
Thanks in advance. 🙂
-
Post got submitted twice. Sorry.
"I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
-
For this you can use a "splitter" (AKA "tokenizer" function.)
DECLARE @String VARCHAR(8000) = 'Hello world. #1234 has been replaced by #014521';
SELECT SomeNbr = REPLACE(split.[value],'#','')
FROM STRING_SPLIT(@String,' ') AS split
WHERE split.[value] LIKE '#[0-9]%';Returns:
SomeNbr
----------
1234
014521Against a table it would look like this:
DECLARE @Strings TABLE (StringID INT IDENTITY, SomeString VARCHAR(1000));
INSERT @Strings(SomeString)
VALUES
('Hello world. #1234 has been replaced by #014521'),
('Numbers, numbers... #012 #999 #Numbers'),
('The quick brown fox...'),
('#000 Another row... #123') ;
SELECT
StringID = s.StringID,
SomeNbr = REPLACE(split.[value],'#','')
FROM @Strings AS s
CROSS APPLY STRING_SPLIT(s.SomeString,' ') AS split
WHERE split.[value] LIKE '#[0-9]%';This returns:
StringID SomeNbr
----------- -----------
1 1234
1 014521
2 012
2 999
4 000
4 123This gets us what we need except for "If there is no '#', then return blank." For the blanks we'll need to push our logic into a subquery and leverage OUTER APPLY like so:
SELECT
StringID = s.StringID,
SomeNbr = ISNULL(split.SomeNbr,'')
FROM @Strings AS s
OUTER APPLY
(
SELECT SomeNbr = REPLACE(split.[value],'#','')
FROM STRING_SPLIT(s.SomeString,' ') AS split
WHERE split.[value] LIKE '#[0-9]%'
) AS split;Returns:
StringID SomeNbr
----------- -----------
1 1234
1 014521
2 012
2 999
4 000
4 123"I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
-
Hi Alan,
Many thanks for the code you have provided. I am still evaluating how to apply this to an existing table, but I do have an observation. If there is no space between the number and '#', I get this:-
DECLARE @String VARCHAR(8000) = 'Hello world. #1234 has been replaced by #014521#2345';
SELECT SomeNbr = REPLACE(split.[value],'#','')
FROM STRING_SPLIT(@String,' ') AS split
WHERE split.[value] LIKE '#[0-9]%';Result:
1234
0145212345Should be:
1234
014521
2345
Also, if I declare this string with parenthesis around a number, it give me just the first occurrence of a #, 1234:-
DECLARE @String VARCHAR(8000) = 'Hello world. #1234 has been replaced by (#014521) (#2345)
Result:
1234
Thank you again! 🙂
p.s. How do I avoid the extra spaces between each line of text? lol
-
Or what's the question? It seems the topic's scope has crept after solutions were posted
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
It's too difficult to answer. I am a new learner.
-
It is too difficult for me.
-
UPDATED 10/31/2024
The was an error in my code, I just changed "bernieML.samd.ngrams8K" to "dbo.ngrams8K". I was using code from my own DB (BernieML) with a different schema (samd).
Sorry for the late reply - I didn't get the email saying there were replies...
To deal with cases where there aren't spaces before "#" or situations like (#123), or (for fun) numbers without preceding #'s, we can do this:
SELECT
Item = SUBSTRING(split.[value],1,IIF(i.Pos=0,8000,i.Pos-1))
FROM STRING_SPLIT(@String,'#') AS split
CROSS APPLY (VALUES(PATINDEX('%[^0-9]%',split.[Value]))) AS i(Pos)
WHERE split.[value] LIKE '[0-9]%';On a pre-2019 system I would recommend delimitedSplit8K. The solution would look like this:
SELECT
Item = SUBSTRING(split.[value],1,IIF(i.Pos=0,8000,i.Pos-1))
FROM STRING_SPLIT(@String,'#') AS split
CROSS APPLY (VALUES(PATINDEX('%[^0-9]%',split.[Value]))) AS i(Pos)
WHERE split.[value] LIKE '[0-9]%';This parameter value includes each of the aforementioned issues, and will still be handled correctly:
DECLARE @String VARCHAR(8000) =
'Emp 223 says: (#1234) has been replaced by #014521#2345. Please call me at 555-333-1234.';For customized split requirements I use NGrams8K. Note the code below and results.
DECLARE @String VARCHAR(8000) =
'Emp 223 says: (#1234) has been replaced by #014521#2345. Please call me at 555-333-1234.';
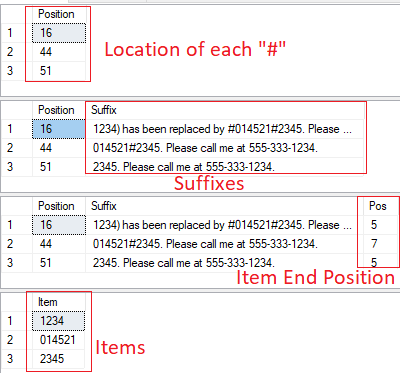
;--==== (1) Get the position of each delimiter (ng.Position)
SELECT ng.Position
FROM dbo.NGrams8k(@String,1) AS ng
WHERE ng.Token = '#';
;--==== (2) Build out suffixes from each delimiter position (s.Suffix)
SELECT
ng.Position,
s.Suffix
FROM dbo.NGrams8k(@String,1) AS ng
CROSS APPLY (VALUES(SUBSTRING(@String,ng.Position+1,8000))) AS s(Suffix)
WHERE ng.Token = '#';
;--==== (3) Find the end position for each item (i.Pos)
SELECT
ng.Position,
s.Suffix,
i.Pos
FROM dbo.NGrams8k(@String,1) AS ng
CROSS APPLY (VALUES(SUBSTRING(@String,ng.Position+1,8000))) AS s(Suffix)
CROSS APPLY (VALUES(PATINDEX('%[^0-9]%',s.Suffix))) AS i(Pos)
WHERE ng.Token = '#';
;--==== (4) use s.Suffix and i.Pos to build the "Item"
SELECT
Item = SUBSTRING(s.Suffix,1,IIF(i.Pos=0,8000,i.Pos-1))
FROM dbo.NGrams8k(@String,1) AS ng
CROSS APPLY (VALUES(SUBSTRING(@String,ng.Position+1,8000))) AS s(Suffix)
CROSS APPLY (VALUES(PATINDEX('%[^0-9]%',s.Suffix))) AS i(Pos)
WHERE ng.Token = '#';Results from each:
 "I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."
"I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
-
Alan... you might want to explain what the bernieML.samd. stuff is.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - SqlRookie wrote:
I am still evaluating how to apply this to an existing table..
And there's the rub. Please provide 5 to 10 rows of readily consumable data for use to operate with. Please see the article at the first link in my signature line below for one way to provide such a thing.
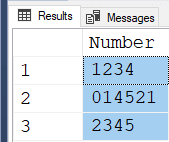
In the meantime, the following works for the variable version...
DECLARE @String VARCHAR(8000) = 'Hello world. #1234 has been replaced by #014521#2345';
SELECT Number = TRIM(sp2.Number)
FROM STRING_SPLIT(@String,'#') sp1
CROSS APPLY (SELECT value FROM STRING_SPLIT(sp1.value,' '))sp2(Number)
WHERE sp2.Number LIKE ('[0-9]%')
;Here's the result...
This would make a good, fairly high performance iTVF (inline Table Valued Function).
Looking forward to some readily consumable data to take it there.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
Alan... you might want to explain what the bernieML.samd. stuff is.
Thanks Jeff - I fixed my code. I was using my own DB and forgot to remove the DB.Schema reference. It's been a couple years since I posted here - rust and lack of coffee 😉
"I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
Viewing 11 posts - 1 through 11 (of 11 total)
You must be logged in to reply to this topic. Login to reply