find the number of values less than the current row
-
declare @DaysToLookBack int = 5
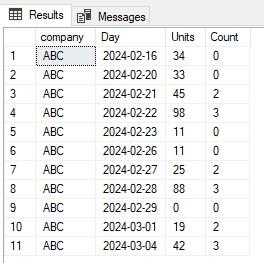
select *
from [dbo].[TestTable1] a
cross apply (select count(*) Count
from (select NULL x) x
cross apply (select top(@DaysToLookBack) *
from [dbo].[TestTable1] b
where b.Day <= a.Day
order by b.Day desc) b
where b.Units < a.Units
) c
order by a.Day
;
-
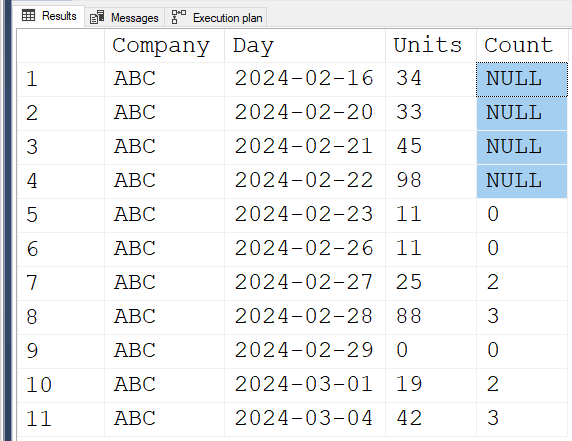
If you need the count to be NULL when there aren't 5 preceding days then this query will do the trick:
declare @DaysToLookBack int = 5
select a.company,
a.Day,
a.Units,
case when g.TotalCountFound < @DaysToLookBack then NULL ELSE c.Count END Count
from [dbo].[TestTable1] a
cross apply (select count(*) Count
from (select NULL x) x
cross apply (select top(@DaysToLookBack) *
from [dbo].[TestTable1] b
where b.Day <= a.Day
order by b.Day desc) b
where b.Units < a.Units
) c
cross apply (select count(*) TotalCountFound
from (select NULL x) x
cross apply(select top(@DaysToLookBack) *
from [dbo].[TestTable1] f
where f.Day <= a.Day
order by f.Day desc) f
) g
order by a.Day
; - Jonathan AC Roberts wrote:
declare @DaysToLookBack int = 5
select *
from [dbo].[TestTable1] a
cross apply (select count(*) Count
from (select NULL x) x
cross apply (select top(@DaysToLookBack) *
from [dbo].[TestTable1] b
where b.Day <= a.Day
order by b.Day desc) b
where b.Units < a.Units
) c
order by a.Day
;Thank you so much for this.
FYI..this version is way faster than the one where NULLs are explicitly outputted. It is nice to have the NULLS showing but its resulting in performance issues so I will deal with those records in the parent query.
Again, thank you so much for your help! I appreciate it very much!!
-
Interesting solutions, so far. Let's try one more...
First, let's simplify the code to make the readily consumable data. This is the best one of the better ways to post such a thing if, for no other reason, just super easy readability. It also takes a lot less work on your part to make it.
DROP TABLE IF EXISTS #TestTable1; --Do in TempDB for "safety"
GO
CREATE TABLE #TestTable1
(
company nvarchar(50) NOT NULL
,[Day] date NOT NULL
,Units tinyint NOT NULL
)
;
INSERT #TestTable1 WITH (TABLOCK)
(company, [Day], Units)
VALUES (N'ABC','2024-02-16',34)
,(N'ABC','2024-02-20',33)
,(N'ABC','2024-02-21',45)
,(N'ABC','2024-02-22',98)
,(N'ABC','2024-02-23',11)
,(N'ABC','2024-02-26',11)
,(N'ABC','2024-02-27',25)
,(N'ABC','2024-02-28',88)
,(N'ABC','2024-02-29', 0)
,(N'ABC','2024-03-01',19)
,(N'ABC','2024-03-04',42)
;Looking at the data and the request, you REALLY need to add this index to the table. It'll help with other queries, as well. If the table is wider and already has a clustered index, post the CREATE TABLE for the who real table and the CREATE of the clustered index and let's talk.
--===== If you don't have this index, you really need to create it.
-- It'll also make the query that follows lightning quick and use a
-- whole lot less resources.
CREATE UNIQUE CLUSTERED INDEX UCI_TestTable1 ON #TestTable1 (Company,[Day])
;Ok... I'm assuming that you'll want to do this "by company" if there's more than one company involved. The following code uses the very fast method of a reverse sort TOP to find the 4 preceding rows for each given row. That's why we need the better CI, which will also help support other queries.
--===== Possible solution code
-- The key takeaway here is, if you have a conditional count,
-- use a conditional SUM(IIF(condition,1,0)) instead.
-- It makes code a whole lot easier.
SET STATISTICS TIME,IO ON
;
DECLARE @DaysToLookBack int = 5
;
SELECT t0.Company
,t0.Day
,t0.Units
,[Count] = IIF(COUNT(*) = 4, SUM(ISNULL(oa1.UnitCount,0)), NULL)
FROM #TestTable1 t0
OUTER APPLY (--===== Look back N-1 days for each row using Fast Indexed Order By
SELECT TOP (@DaysToLookBack-1)
UnitCount = IIF(toa.Units < t0.Units,1,0)
FROM #TestTable1 toa
WHERE toa.company = t0.company --Remember, "By Company"
AND toa.[Day] < t0.[Day]
ORDER BY toa.[Day] DESC) oa1
GROUP BY t0.company,t0.[Day],t0.Units
ORDER BY Company, [Day]
;
SET STATISTICS TIME,IO OFF;
GOResults:
Not sure if a SUM() OVER Rows Preceding thing might work or not. We can try that a little later.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 4 posts - 16 through 19 (of 19 total)
You must be logged in to reply to this topic. Login to reply