Find average of child records within date range
-
hi,
I am working with three different tables:
headerTable
lineTable and
saleDateTableI am trying to figure out average saleAmount (lineTable) for each of the products within the SaleStartDate and SaleEndDate (this is in saleDateTable ).
Using Outer Apply I am able to get average sale amount - however I am not sure how to build on further add the part where the average is for amounts when the sale on was (based on SaleStartDate and SaleEndDate).
Here is the sample DDL for all three tables and some sample insert statements:
create table #headerTable(
ProductKey int,
IntroDateKey int,
Cost money
)create table #lineTable(
ProductKey int,
SaleDateKey int,
SaleAmount money
)create table #saleDateTable(
ProductKey int,
StartSaleDateKey int,
EndSaleDateKey int,
)insert into #headerTable values(1,20180101,30.00)
insert into #headerTable values(2,20170101,50.00)
insert into #headerTable values(3,20160101,10.00)insert into #lineTable values(1,20180101,30.00)
insert into #lineTable values(1,20180102,35.00)
insert into #lineTable values(1,20180103,40.00)
insert into #lineTable values(1,20180104,10.00)
insert into #lineTable values(1,20180105,20.00)
insert into #lineTable values(1,20180106,30.00)
insert into #lineTable values(1,20180107,110.00)
insert into #lineTable values(1,20180108,70.00)
insert into #lineTable values(1,20180109,30.00)
insert into #lineTable values(1,20180110,20.00)insert into #lineTable values(2,20180101,50.00)
insert into #lineTable values(2,20180102,35.00)
insert into #lineTable values(2,20180103,40.00)
insert into #lineTable values(2,20180104,10.00)
insert into #lineTable values(2,20180105,20.00)
insert into #lineTable values(2,20180106,30.00)
insert into #lineTable values(2,20180107,100.00)
insert into #lineTable values(2,20180108,5.00)
insert into #lineTable values(2,20180109,30.00)
insert into #lineTable values(2,20180110,20.00)insert into #saleDateTable values (1, 20180101, 20180105)
insert into #saleDateTable values (2, 20180107, 20180109)this is what I have so far:
select *
from #headerTable a
outer apply (
select avg(saleamount) as avgSale from #lineTable b
where a.ProductKey = b.ProductKey
) Z
goWith OuterApply I can also see which products didn't have a sale. For example for product key 3 - there are no sales in the lineTable.
Any thoughts on how can I go about getting an average for just the date range where sale was on?thanks
-
Here's something more readable – with > 5000 points, you should know how to use IF tags. Perhaps you would also include desired results, based on your sample data?
DROP TABLE IF EXISTS #headerTable;CREATE TABLE #headerTable
(
ProductKey INT
, IntroDateKey INT
, Cost MONEY
);DROP TABLE IF EXISTS #lineTable;
CREATE TABLE #lineTable
(
ProductKey INT
, SaleDateKey INT
, SaleAmount MONEY
);DROP TABLE IF EXISTS #saleDateTable;
CREATE TABLE #saleDateTable
(
ProductKey INT
, StartSaleDateKey INT
, EndSaleDateKey INT,
);INSERT #headerTable ( ProductKey, IntroDateKey, Cost )
VALUES ( 1, 20180101, 30.00 )
, ( 2, 20170101, 50.00 )
, ( 3, 20160101, 10.00 )INSERT #lineTable ( ProductKey, SaleDateKey, SaleAmount )
VALUES ( 1, 20180101, 30.00 )
, ( 1, 20180102, 35.00 )
, ( 1, 20180103, 40.00 )
, ( 1, 20180104, 10.00 )
, ( 1, 20180105, 20.00 )
, ( 1, 20180106, 30.00 )
, ( 1, 20180107, 110.00 )
, ( 1, 20180108, 70.00 )
, ( 1, 20180109, 30.00 )
, ( 1, 20180110, 20.00 )INSERT #lineTable ( ProductKey, SaleDateKey, SaleAmount )
VALUES ( 2, 20180101, 50.00 )
, ( 2, 20180102, 35.00 )
, ( 2, 20180103, 40.00 )
, ( 2, 20180104, 10.00 )
, ( 2, 20180105, 20.00 )
, ( 2, 20180106, 30.00 )
, ( 2, 20180107, 100.00 )
, ( 2, 20180108, 5.00 )
, ( 2, 20180109, 30.00 )
, ( 2, 20180110, 20.00 )INSERT #saleDateTable ( ProductKey, StartSaleDateKey, EndSaleDateKey )
VALUES ( 1, 20180101, 20180105 )
, ( 1, 20180107, 20180109 ) -
Thanks Phil. I will keep IF Code in mind next time.
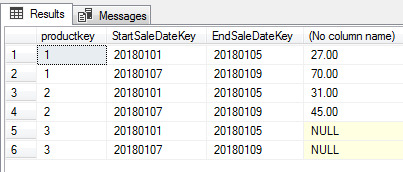
Desired results are such:
ProductKey AvgSaleAmount (within Sale Period)
1 27.00
2 45.00
3 NULLI did another iteration some what close to the result but not there yet since it is missing header data - I am able to get average in the sale period:
select * from #saleDateTable a
outer apply (
select avg(saleAmount) as avgSaleAmount from #lineTable b
where b.ProductKey = a.ProductKey
and b.SaleDateKey between a.StartSaleDateKey and a.EndSaleDateKey
) Zthanks
-
I think I have figured it out:
select k.ProductKey, cost, avgSaleAmount from #headerTable k
outer apply(
select * from #saleDateTable a
outer apply (
select avg(saleAmount) as avgSaleAmount from #lineTable b
where b.ProductKey = a.ProductKey
and b.SaleDateKey between a.StartSaleDateKey and a.EndSaleDateKey
) Z
where a.ProductKey = k.ProductKey
) PWould like to know what you guys think about this solution. Is this correct? Looks correct.
-
select h.productkey,s.StartSaleDateKey, s.EndSaleDateKey, avg(l.SaleAmount)
from #headerTable h
cross join #saleDateTable s
left join #lineTable l
ON l.SaleDateKey between s.StartSaleDateKey and s.EndSaleDateKey
AND l.ProductKey = h.ProductKey
group by h.ProductKey, s.StartSaleDateKey, s.EndSaleDateKey - Jonathan AC Roberts - Tuesday, October 23, 2018 8:05 AM
Thanks Jonathan - this produces incorrect results. This is averaging for all products for all sale dates.
Also - I used OUTER APPLY because I wanted to get all the rows from the parent table. - sqlstar2011 - Tuesday, October 23, 2018 9:27 AM
It is averaging for each product within each StartDate and EndDate range.
The left join ensures all rows are returned from the parent tables.
- Jonathan AC Roberts - Tuesday, October 23, 2018 9:45 AM
this is still incorrect. please run my query and you will see why.
you have two averages for each product. where you should have one average for each product.
there were only two sales - one for product 1 and one for product 2. - sqlstar2011 - Wednesday, October 24, 2018 11:41 AM
Your query is just taking the average sale amount for each product across all dates, including dates outside the sales period.
So this (your query):select *
from #headerTable a
outer apply (
select avg(saleamount) as avgSale from #lineTable b
where a.ProductKey = b.ProductKey
) Z
is equivalent to this:select h.productkey,h.IntroDateKey,h.cost,avg(l.SaleAmount)
from #headerTable h
left join #lineTable l on l.ProductKey = h.ProductKey
group by h.ProductKey,h.IntroDateKey,h.cost
order by 1
You need to add a constraint so the lineTable rows are only within the sale dates, like this:select h.productkey,h.IntroDateKey,h.cost,avg(l.SaleAmount)
from #headerTable h
cross join #saleDateTable s
left join #lineTable l
ON l.SaleDateKey between s.StartSaleDateKey and s.EndSaleDateKey
AND l.ProductKey = h.ProductKey
group by h.ProductKey,h.IntroDateKey,h.cost
order by 1 -
Why did you fail to post DDL? Now we have to guess from what you did post and how to correct it. But more than that, you have no idea how to design a database. Identifiers are measured on nominal scale, a fact that is usually covered in the first week of any class on data modeling. They can never be integers, but if you grew up with network databases, you’ll make things integers so the look like pointers for you.
We would never put the word “table” in the table name because that would be mixing data and metadata in a data element name. In fact it such a classic error that It has a name; Tibble. In SQL. We have referenced and referencing tables, not the original magnetic tape file headers and lines (or parent and child files. The R in RDBMS stands for relations, and you have nothing to show the relationship between these tables. We never use the old Sybase proprietary money data type because it doesn’t do correct arithmetic (Google it! You may have already screwed up a bunch of reports) and because it doesn’t port. Do you even know the tables have to have a key, by definition? You don’t seem to know that, SQL has temporal datatypes. Why do you think that using integers for dates makes any sense?
You probably haven’t been programming long enough to remember punch cards. When we use those over 50 years ago, we always put the, in a list on the left-hand side of the card. Yes, this made it measurably harder to read and more error-prone, but you could save the cards in between programs and rearrange the deck. The last 20 years, however, you can simply hit a key on a pretty print tool and reformat your code to keep it neat and easily maintainable
Here’s an attempt at correcting this posting
CREATE TABLE Products
(gtin CHAR(14) NOT NULL PRIMARY KEY
intro_date DATE NOT NULL,
item_cost DECIMAL(10,2) NOT NULL
CHECK(item_cost > 0.00));the GTIN is a barcode used for global trade item numbers. It is an industry-standard industry-standard. It’s printed on packages, and is part of the UPC code system. It is not an integer.
CREATE TABLE Sales
(gtin CHAR(14) NOT NULL REFERENCES Products(gtin),
sale_date DATE DEFAULT CURRENT_TIMESTAMP NOT NULL,
sale_amount DECIMAL(10,2) NOT NULL,
CHECK (sale_amount >= 0.00)
);There is a big difference between a sale and a promotion. A sale is one where we get some money from a customer. A promotion changes the price of the item or gives some other bonus during the time Interval that it is active.
CREATE TABLE Promotions
(promo_name VARCHAR(15) NOT NULL PRIMARY KEY,
gtin CHAR(14) NOT NULL REFERENCES Products(gtin),
start_promo_date DATE NOT NULL,
end_promo_date DATE,
CHECK(start_promo_date <= end_promo_date)
);Microsoft has always supported the ANSI standard “INSERT INTO” syntax, as well as the old, proprietary original Sybase “INSERT” syntax. But when you use proprietary syntax, you are sending out a message that you don’t know how to use the language. It’s a style point that I use when I’m looking for bad code. Another Sybase proprietary shorthand is using ISO 8601 dates without dashes in them. We spent a lot of time, the committee on this one and wanted to make sure there was no way to mistake a date for an integer. Standard SQL requires a semi-colon, but the original Sybase proprietary syntax did not. The bad news is that is Microsoft is added more standard features, so standard syntax is becoming required in some places.
INSERT INTO Products
VALUES
('0001234560012', '2018-01-01', 30.00),
('0001234560088', ‘2017-01-01’, 50.00),
('0001234560099', ‘2016-01-01’, 10.00);INSERT INTO Sales
VALUES
('0001234560012', '2018-01-01', 30.00),
('0001234560012', '2018-01-02, 35.00),
('0001234560012', '2018-01-03, 40.00),
('0001234560012', '2018-01-04, 10.00),
('0001234560012', '2018-01-05, 20.00),
('0001234560012', '2018-01-06, 30.00),
('0001234560012', '2018-01-07, 110.00),
('0001234560012', '2018-01-08, 70.00),
('0001234560012', '2018-01-09, 30.00),
('0001234560012', '2018-01-10, 20.00),
('0001234560088', '2018-01-01', 50.00),
('0001234560088', '2018-01-02’, 35.00),
('0001234560088', '2018-01-03’, 40.00),
('0001234560088', '2018-01-04’, 10.00),
('0001234560088', '2018-01-05’, 20.00),
('0001234560088', '2018-01-06’, 30.00),
('0001234560088', '2018-01-07’, 100.00),
('0001234560088', '2018-01-08’, 5.00),
('0001234560088', '2018-01-09’, 30.00),
('0001234560088', '2018-01-10’, 20.00);
I’m trying to keep your original structure as best I can, but I think I’d give the promotions a name. My favorite is “annual going out of business sale”, since I remember a store that did that 🙂INSERT INTO Promotions
VALUES
(‘First week promo’, '0001234560012', '2018-01-01', '2018-01-05’),
(‘Second week promo’, '0001234560012', '2018-01-07’, '2018-01-09’);SELECT X.promo_name, AVG(X.sale_amount)AS sale_amount_avg
FROM (SELECT P.gtin, P.promo_name, S.sale_amount
FROM Promotions AS P, Sales AS S
WHERE P.gtin = S.gtin
AND S.sale_date
BETWEEN P.start_promo_date AND P.end_promo_date)
AS X
GROUP BY X.promo_name;
this is untested.Please post DDL and follow ANSI/ISO standards when asking for help.
- jcelko212 32090 - Wednesday, October 24, 2018 1:59 PM
Funny, Mr. Celko, but there is DDL posted in the initial post or did you fail to read it.
And of course your code is untested since you NEVER test any code you post here.
Viewing 11 posts - 1 through 11 (of 11 total)
You must be logged in to reply to this topic. Login to reply