Filter single field using comma delimited criteria and delimitedsplit8k
-
Hi SQL Experts,
I'd appreciate any help with this. I have a simple table as per example below. I want to filter the ProductName field using a comma delimited string of short words.
Example 'NonPot,Meter,2 Year' I'd like to return the product names that contain all of those short words/phrases.ProductID ProductName WholesalerID ServiceID 1 AL,Pot,Metered,100+,Select 50,22mm,5 Year 1 1 2 AN,NonPot,Metered,<15,Select 750/+,22mm,2 Year 2 2 3 AL,NonPot,Unmetered,100+,Standard,No,2 Year 1 1 4 Non,Unmetered Water,<15,<50000,No,1 Year 1 30 5 Non,Unmetered Water,100+,>750000,No,2 Year 1 3 6 NW,Non,Unmetered,16-22,180000<750000,15mm,3 Year 1 15
I have come across this brilliant function delimitedsplit8k which will split out a comma delimited string.USE [AquaFlow]
GO
/****** Object: StoredProcedure [dbo].[FilterProductList] Script Date: 13/06/2017 23:55:50 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
ALTER PROCEDURE [dbo].[FilterProductList]
(
@criteria varchar(100)=''
)
ASSELECT *
FROM tblProduct t1
WHERE NOT EXISTS
(
SELECT *
FROM tblProduct t2
CROSS APPLY dbo.delimitedsplit8k(@criteria,',')
WHERE t2.ProductName NOT LIKE '%'+item+'%'
)
Order by ProductName
I've set it up as per the example above but I am not having a lot of joy.
Can someone point me in the right direction or correct what I currently have.Thank you in advance!
Joe
-
Hi Guys,
Apologies, I think I have posted this in the wrong forum., it should have been in the TSQL forum, anyway I started so I'll finish...I persevered with this and realised I'd made a silly mistake.... I was comparing t2.ProductName instead of t1.ProductName to the split item. It's working great now.
(
SELECT *
FROM tblProduct t2
CROSS APPLY dbo.delimitedsplit8k(@criteria,',')
WHERE t1.ProductName NOT LIKE '%'+item+'%'
)
For those of you interested in using this brilliant function the zipped code can be downloaded from the bottom of this page which also explains how it all works.Joe
-
I had a couple of questions about this query.
1.) If your subquery isn't using t2, then why the extra reference to tblProducts?
2.) using your sample of 'NonPot,Meter,2 Year' then ProductName LIKE '%Meter%' is LIKE both Metered and Unmetered, is that intended?
3.) are you trying to include or not include products with any of the criteria keywords? The double negative logic makes it confusing -
Jeff Moden's DelimitedSplit8K is the best in the business on pre-2012 systems and non-max data types; on SQL 2012+ I suggest DelimitedSplit8k_LEAD by Eirikur Eiriksson which is based on Jeff's splitter. I suggest reading and understanding what's in both articles, both are excellent.
As Chris pointed out, your query should not return any results if the objective is to find an exact match (or lack of) between values. In your query "Meter" is matching "metered" and "unmetered" which is why the records with ID 2&3 come back. That logic doesn't make much sense. If the criteria is an exact match I would suggest this approach:
1. Use DelimitedSplit8K and CROSS APPLY to split tblProduct.product
2. Use Use DelimitedSplit8K to split @criteria
3. Compare the "items" from both queriesNote that Eirikur's splitter is named DelimitedSplit8K_LEAD in his article, I changed the name to end with 2012 on my systems.
USE tempdb
GOIF OBJECT_ID('dbo.tblProduct') IS NOT NULL DROP TABLE dbo.tblProduct;
SELECT -- note: CAST sets the datatype, ISNULL sets column to NOT NULL
ProductID = ISNULL(CAST(ProductID as int),0),
ProductName = ISNULL(CAST(ProductName as varchar(100)),''),
WholesalerID = ISNULL(CAST(WholesalerID as tinyint),0),
ServiceID = ISNULL(CAST(ServiceID as int),0)
INTO dbo.tblProduct
FROM (VALUES
(1,'AL,Pot,Metered,100+,Select 50,22mm,5 Year',1,1),
(2,'AN,NonPot,Metered,<15,Select 750/+,22mm,2 Year,xxx',2,2),
(3,'AL,NonPot,Unmetered,100+,Standard,No,2 Year,xxx',1,1),
(4,'Non,Unmetered Water,<15,<50000,No,1 Year',1,30),
(5,'Non,Unmetered Water,100+,>750000,No,2 Year',1,3),
(6,'NW,Non,Unmetered,16-22,180000<750000,15mm,3 Year',1,15))
x(ProductID, ProductName, WholesalerID, ServiceID);
Now my solution:DECLARE @criteria varchar(100)='NonPot,2 Year';SELECT product.ProductID
FROM dbo.tblProduct product
-- let's split both strings then check for products that exist in @criteria but not dbo.tblProduct.productname
CROSS APPLY dbo.delimitedSplit8K_2012(product.productName, ',') AS productSplit
CROSS JOIN dbo.delimitedSplit8K_2012(@criteria, ',') AS criteria
WHERE productSplit.item = criteria.item
GROUP BY product.ProductID
HAVING COUNT(*) = LEN(@criteria)-LEN(REPLACE(NULLIF(@criteria,''), ',',''))+1; --how to "count" the number of "items" in @criteria
Note that, if you really are doing LIKE matching then you could easily modify this logic accordingly.It sure is a shame that you have to split the string each time you run this query. Yet another another example of why this is a bad design but I'll skip the normal form lecture. This is common these days, especially with vendors. The best thing to do is to correctly normalize your data and index it but if that's not an option, I have a way you can really speed things up.
The Indexed View Alternative
First we need a tally table - a permanent tally table, a numbers function or cte tally table wont work. Note my comments.
IF OBJECT_ID('dbo.tally') IS NOT NULL DROP TABLE dbo.tally;
CREATE TABLE dbo.tally
(
N int NOT NULL,
CONSTRAINT pk_dbo_tally PRIMARY KEY CLUSTERED(N) WITH FILLFACTOR = 100,
CONSTRAINT uq_dbo_tally UNIQUE NONCLUSTERED(N)
);-- 10,000 is plenty but you are not limited to 8K. Also, we're starting our tally table at 0.
INSERT dbo.tally
SELECT TOP (10000) ROW_NUMBER() OVER (ORDER BY (SELECT 1))-1
FROM sys.all_columns a, sys.all_columns b;Next, our view.
CREATE VIEW dbo.vProductSplit
WITH SCHEMABINDING AS
SELECT
p.ProductID,
position = t.N+1,
item =
SUBSTRING
(
p.ProductName,
N+1,
ISNULL(NULLIF(CHARINDEX(',', p.ProductName, t.N+1), 0),8000)-(t.N+1)
)
FROM dbo.tblProduct p
CROSS JOIN dbo.tally t
WHERE t.N < DATALENGTH(p.ProductName) AND (t.N=0 OR SUBSTRING(p.ProductName,t.N,1)=',');
GO
Here we've extracted the splitter logic from delimitedSplit8K and re-wrote it in a way that it can live in an indexed view. Now for the required unique clustered index; again, note my comments.-- Notice that I left the "N+1" column which represents the position of where the "item" starts.
CREATE UNIQUE CLUSTERED INDEX uq_cl_vProductSplit ON dbo.vProductSplit(ProductId, position);
Note only is the split happening before you execute your select statement, we've made it possible to further index the content of these delimited strings. Now for a more useful nonclustered Index.CREATE NONCLUSTERED INDEX nc_vProductSplit_item ON dbo.vProductSplit(item)
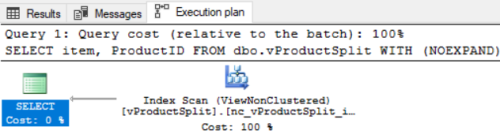
INCLUDE (ProductID);Check out the execution plan for this query:
SELECT item, ProductID FROM dbo.vProductSplit WITH (NOEXPAND);
That's me retrieving my "pre-split" values from a nonclustered index. I am extremely cautious about query hints but the WITH (NOEXPAND) hint is vital here.Item Number?
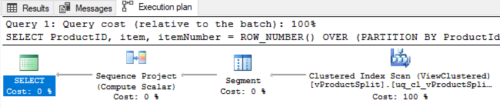
DelimitedSplit8K and DelimitedSplit8K_LEAD both use ROW_NUMBER() to produce the ItemNumber column. ROW_NUMBER is not allowed in indexed views which is why I included the "position" (N1) column in my indexed view. Check out the execution plan after I've rolled my own itemNumber
SELECT ProductID, item, itemNumber = ROW_NUMBER() OVER (PARTITION BY ProductId ORDER BY position)
FROM dbo.vProductSplit WITH (NOEXPAND)
ORDER BY ProductID, position; -- for display and learning purposes only
That's a good execution plan.Performance
And before I call it a night, the obligatory performance test. Let's add 150K additional rows of your data.
INSERT dbo.tblProduct
SELECT
ProductID = ROW_NUMBER() OVER (ORDER BY (SELECT 1))+6,
ProductName,
WholesalerID,
ServiceID
FROM tblProduct
CROSS JOIN dbo.tally
WHERE N < 150000;Here we're comparing the performance of the indexed view vs the 2012 version of the iTVF (function).
DECLARE @criteria varchar(100)='NonPot,2 Year';PRINT 'Using View'+char(13)+char(10)+replicate('-',50);
GO
DECLARE @criteria varchar(100)='NonPot,2 Year', @st datetime = getdate(), @x int;SELECT @x = product.productID
FROM dbo.vProductSplit AS product WITH (NOEXPAND)
JOIN dbo.DelimitedSplit8K_2012(@criteria, ',') AS criteria
ON criteria.Item = product.item
GROUP BY product.ProductID
HAVING COUNT(*) = LEN(@criteria)-LEN(REPLACE(NULLIF(@criteria,''), ',',''))+1;PRINT DATEDIFF(ms, @st, getdate());
GO 5PRINT char(13)+char(10)+'Splitter Only'+char(13)+char(10)+replicate('-',50);
GO
DECLARE @criteria varchar(100)='NonPot,2 Year', @st datetime = getdate(), @x int;SELECT @x = product.productID
FROM dbo.tblProduct product
CROSS APPLY dbo.delimitedSplit8K_2012(product.productName, ',') AS productSplit
CROSS JOIN dbo.delimitedSplit8K_2012(@criteria, ',') AS criteria
WHERE productSplit.Item = criteria.item
GROUP BY product.ProductID
HAVING COUNT(*) = LEN(@criteria)-LEN(REPLACE(NULLIF(@criteria,''), ',',''))+1;PRINT DATEDIFF(ms, @st, getdate());
GO 5In this test the "indexed split" technique get's us about 5X the performance.
Using View
--------------------------------------------------
Beginning execution loop
740
736
910
786
960
Batch execution completed 5 times.Splitter Only
--------------------------------------------------
Beginning execution loop
5140
4207
4300
4566
4363
Batch execution completed 5 times.If you run the above queries with STATISTICS IO ON you'll see that a huge reason for the performance gains is how that nonclustered reduces the reads from ~1.8Million to 3,000.
Using View
--------------------------------------------------
Beginning execution loop
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 24, logical reads 1376, physical reads 124, read-ahead reads 1252, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'vProductSplit'. Scan count 2, logical reads 2243, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.Splitter Only
--------------------------------------------------
Table 'Worktable'. Scan count 6, logical reads 1800087, physical reads 0, read-ahead reads 6333, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'tblProduct'. Scan count 5, logical reads 7847, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0."I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
-
Hi there, thank you for the replies and also thank you for the comprehensive information on the DelimitedSplit8k_LEAD by Eirikur Eiriksson, a nice bit of bedtime reading! I was using the splitter to filter out product names that contain all portions of the delimited words. By using the word 'meter' this meant that unmetered and metered would get picked, in the limited selection of records I gave it does seem a bit pointless using that term but in the extensive list of product names not all the products contain the term metered or unmetered in them so they would have automatically been excluded. The product name is in reality a log winded description of the product that is made up of several selected components concatenated together which can be very varied. By typing in just small subsets of the component terms the specific product is whittled down very quickly without needing to knowing too many specifics. It works as intended so I'm delighted. In terms of efficiency it seems to work very fast as it is because the product table will not have more than 1500 unique products so I'm happy with what we have. I can see a benefit of the other splitter on larger tables though.
Thanks again,
Joe
Viewing 5 posts - 1 through 5 (of 5 total)
You must be logged in to reply to this topic. Login to reply