Fastest Way to Calculate Total Number of records inserted per day
- Brahmanand Shukla wrote:
Around 2-3 times.
Thanks for taking the time to do all of that (seriously... thank you) but the the test isn't repeatable for others. Yes, they can use the same test against any table but we don't have the table you used for the test. For that matter, you've not listed what the DDL of the table or the indexes actually is.
Although it may not have an effect in a single case, the use of DATEADD(DD, -1, GETDATE()) means that the test isn't actually repeatable over time.
Can you post the DDL for the table you used including the indexes, etc, please? This whole thing is a good question that could destroy at least one "Best Practice" (I mean "myth" in this case... just remember that myths can be proven true or false) and I'd like to give your findings a shot using your code and see if there may be exceptions or better ways. For example, you've also introduced the myth (again, can be true or false) that conditional execution will cause the execution plan to change at some level. I'll also remove that from the testing because we only want to test one thing at a time
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - jonas.gunnarsson 52434 wrote:
Interesting, sins of version of 2008 the COUNT(*) vs COUNT(1) should generate the same execution plan.(column 1 should be pk/not null). Also count won't read any data from the column(s), only the where clause fetch data.
Q: Did you run the test one time or 10+ times?
Interesting test at the link. It doesn't actually have any performance measurements. It only shows execution plans. Execution plans don't show actual performance (they're a mix of estimates and actuals even on supposedly "Actual" execution plans).
In fact, using only Execution Plans to decide which is the "best" code to use can actually lead you to choosing the worst solution rather than the best when it comes to performance.
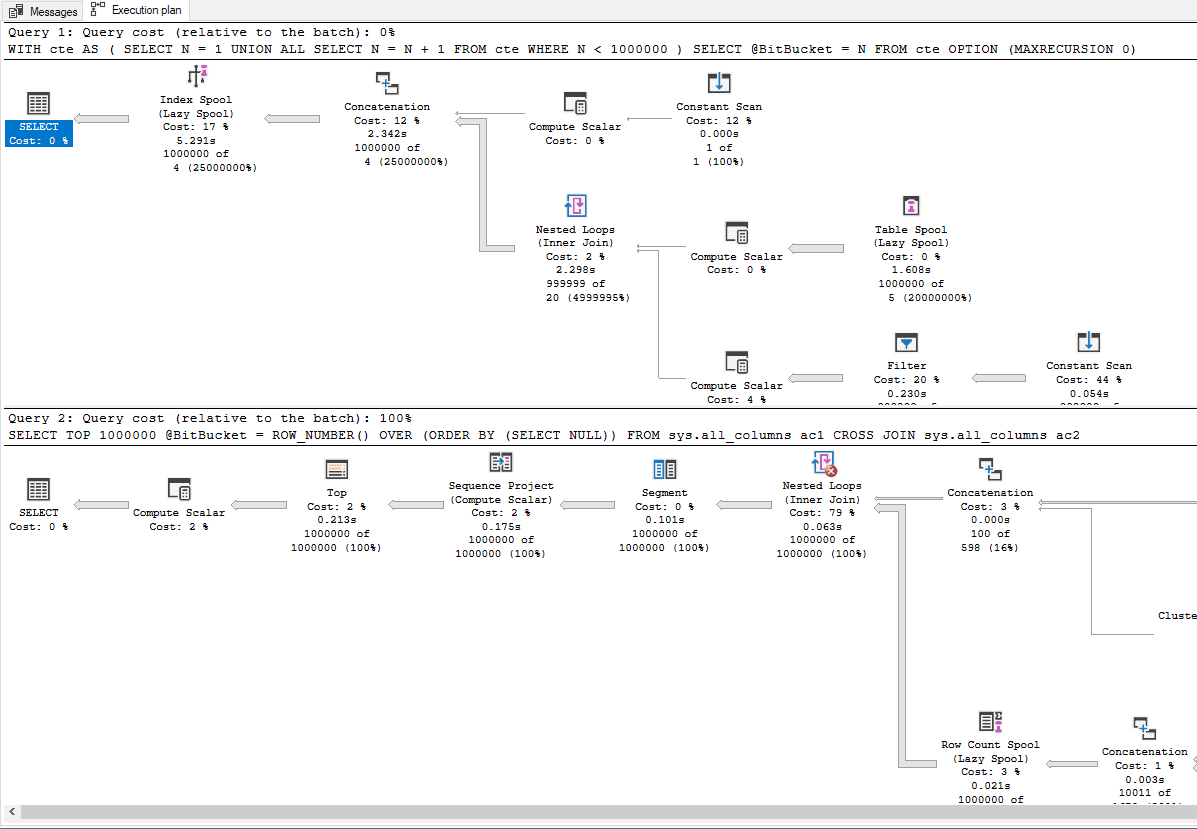
Ah... I've made a performance claim. That requires proof. So, here's the coded and easily demonstrable and repeatable code to test the claim that I've just made.
Here's the code to support my claim and similar tests have led many to incorrectly believing that rCTE's (recursive CTEs) are much better than using a "Pseudo-Cursor" based on a CROSS JOIN to accomplish the simple task of counting. Turn on the "Actual Execution" plan and run the following code.
DECLARE @BitBucket INT
;
-------------------------------------------------------------------------------
RAISERROR('--===== Reursive CTE =====',0,0) WITH NOWAIT;
SET STATISTICS TIME,IO ON;
WITH cte AS
(
SELECT N = 1
UNION ALL
SELECT N = N + 1
FROM cte
WHERE N < 1000000
)
SELECT @BitBucket = N
FROM cte
OPTION (MAXRECURSION 0)
;
SET STATISTICS TIME,IO OFF;
PRINT REPLICATE('-',119)
;
-------------------------------------------------------------------------------
RAISERROR('--===== Pseudo-Cursor =====',0,0) WITH NOWAIT;
SET STATISTICS TIME,IO ON;
SELECT TOP 1000000
@BitBucket = ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM sys.all_columns ac1
CROSS JOIN sys.all_columns ac2
;
SET STATISTICS TIME,IO OFF;
PRINT REPLICATE('-',119)
;If we look at "Query Cost" (relative to batch), at 0% for the rCTE and 100% for the "Pseudo Cursor" method, it's "clear" to even a casual user that the rCTE is MUCH better code, right?

But, if we look at the performance statistics with the Actual Execution plan turned off, we see which is the real winner when it comes to performance AND resource usage, as well.
--===== Reursive CTE =====
Table 'Worktable'. Scan count 2, logical reads 6000001, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 4687 ms, elapsed time = 4942 ms.
-----------------------------------------------------------------------------------------------------------------------
--===== Pseudo-Cursor =====
Table 'syscolpars'. Scan count 1, logical reads 467, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'sysobjvalues'. Scan count 2, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'syscolpars'. Scan count 2, logical reads 24, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 79 ms, elapsed time = 80 ms.
-----------------------------------------------------------------------------------------------------------------------
Now I'll admit that using Actual Execution plans will help you see what's going on in performance challenged code (most people miss the single row line arrows in the rCTE meaning that the execution plan is depicting a single iteration rather than the full monty like the "Pseudo Cursor"), but you MUST NOT ever use only the execution plans to determine what is actually the best code... period!
As Wernher von Braun is quoted as saying...
"One good test is worth a thousand expert opinions"
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
First, my apologies to the OP for participating in the hijacking of the thread, but this COUNT(*) vs COUNT(1) stuff is worth handling.
On COUNT(*) vs COUNT(1), I've never been able to measure anything other than noise between the two.
Before I get to testing the actual performance of these two, I should point out that it is demonstrably false than COUNT(*) somehow needs to read all column values in a row; if this were the case, then COUNT(*) would never be able to use an index that included only a proper subset of the table's columns without doing a lookup to read the remaining columns.
As a simple test can show, SELECT COUNT(*) FROM <some table> can in fact use an index that includes only a proper subset of the table's columns without having to do a lookup to read the other columns.
CREATE TABLE #test_count_star (some_int INT, some_char CHAR(50), some_float FLOAT);
WITH
n AS (SELECT n FROM (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0))n(n)),
lots_o_rows AS (SELECT n1.n FROM n n1, n n2, n n3, n n4, n n5)
INSERT INTO #test_count_star (some_int, some_char, some_float)
SELECT RAND(CHECKSUM(NEWID()))*1000, NEWID(), RAND(CHECKSUM(NEWID()))
FROM lots_o_rows;
CREATE NONCLUSTERED INDEX NCI_some_int ON #test_count_star (some_int);
SELECT COUNT(*) FROM #test_count_star;The execution plan for the SELECT COUNT(*) scans NCI_some_int, but does not do any lookups into the heap, which it would have to do if the star forced it to read all the column values.
For the more general performance question, here's one type of test I've done that suggests this is all a wash (this script does use DROP...IF EXISTS and CREATE OR ALTER, so you'll need to be on a version that supports these commands to run it without modification).
SET NOCOUNT ON;
DROP TABLE IF EXISTS #count_test;
CREATE TABLE #count_test (some_int INT, some_char CHAR(50), some_float FLOAT);
WITH
n AS (SELECT n FROM (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0))n(n)),
lots_o_rows AS (SELECT n1.n FROM n n1, n n2, n n3, n n4, n n5, n n6, n n7)
INSERT INTO #count_test (some_int, some_char, some_float)
SELECT RAND(CHECKSUM(NEWID()))*1000, NEWID(), RAND(CHECKSUM(NEWID()))
FROM lots_o_rows;
GO
CREATE OR ALTER PROCEDURE count_star AS
BEGIN
SET NOCOUNT ON;
DECLARE @int_bucket INT;
SELECT @int_bucket=COUNT(*) FROM #count_test OPTION (MAXDOP 1);
END
GO
CREATE OR ALTER PROCEDURE count_star2 AS
BEGIN
SET NOCOUNT ON;
DECLARE @int_bucket INT;
SELECT @int_bucket=COUNT(*) FROM #count_test OPTION (MAXDOP 1);
END
GO
CREATE OR ALTER PROCEDURE count_one AS
BEGIN
SET NOCOUNT ON;
DECLARE @int_bucket INT;
SELECT @int_bucket=COUNT(1) FROM #count_test OPTION (MAXDOP 1);
END
GO
EXECUTE count_one;
EXECUTE count_star;
GO 1000
SELECT [procedure_name]=OBJECT_NAME(object_id,database_id), total_elapsed_time_ms=total_elapsed_time/1000, execution_count, total_logical_reads,total_physical_reads
FROM sys.dm_exec_procedure_stats
WHERE database_id=DB_ID() AND object_id IN (object_id('count_star'),object_id('count_one'), object_id('count_star2'))
ORDER BY total_elapsed_time ASC;Now for some results. The script as posted uses MAXDOP 1 to keep things more reproducible, but I did run it a few times without the MAXDOP hint just to get a taste of those results.
Parallelism-enabled
procedure_nametotal_elapsed_time_msexecution_counttotal_logical_readstotal_physical_reads
count_one 341740 1000 87756000 0
count_star 341782 1000 87756000 0
procedure_nametotal_elapsed_time_msexecution_counttotal_logical_readstotal_physical_reads
count_star 347868 1000 87756000 0
count_one 349575 1000 87756000 0So in the first run, COUNT(1) was indeed faster....by 42 milliseconds total after 1000 runs. .042 ms per execution is very likely noise.
To that point, in the second run COUNT(*) was actually faster, this time by 1707 ms over 1000 runs, so about 1.7 ms per execution. Compared to the nearly 350 ms average duration and given that the first run even gave an advantage to the other procedure, this is most likely noise.
Now some results with MAXDOP 1, which should be a bit more reproducible (I'd expect a bit more variation with unlimited MAXDOP pegging my CPUs, but your mileage may vary).
Parallelism-disabled
procedure_nametotal_elapsed_time_msexecution_counttotal_logical_readstotal_physical_reads
count_one 499316 1000 87756000 0
count_star 499426 1000 87756000 0
procedure_nametotal_elapsed_time_msexecution_counttotal_logical_readstotal_physical_reads
count_one 505273 1000 87756000 0
count_star 507265 1000 87756000 0
procedure_nametotal_elapsed_time_msexecution_counttotal_logical_readstotal_physical_reads
count_star 542544 1000 87756000 0
count_one 544325 1000 87756000 0In the first run, COUNT(1) was faster by 110 ms over 1000 runs, or 0.11 ms per execution. This is so small a difference I'd suspect it was noise as well.
In the second run, COUNT(1) was again faster, this time by 1992 ms over 1000 runs, or 1.992 ms per execution. That's the biggest difference in any run so far, but is still so small that it is likely noise, especially given the second biggest difference, 1.7 ms per execution, was actually in favor of COUNT(*).
In the third run, COUNT(*) was faster by by 1781 ms over 1000 runs, or 1.781 ms per execution. Again very small, and again we got a result going in the opposite direction of "COUNT(1) is faster than COUNT(*)".
Here's the real kicker, though. I keep saying that I expect this small difference to be noise. Why would I suspect that?
Because I ran a control test ahead of time, comparing two procedures that both ran the exact same COUNT(*) query (the eagle-eyed among you will have already noticed that my script creates two procedures for the COUNT(*) query).
Here are those results:
procedure_nametotal_elapsed_time_msexecution_counttotal_logical_readstotal_physical_reads
count_star 544497 1000 87756000 0
count_star2 547651 1000 87756000 0As we can see, one procedure in this run took 3154 ms over 1000 runs more than the other, for a difference of 3.154 ms per execution, and they were running the exact same query.
Differences around this amount, then, likely don't indicate much for these particular testing conditions.
I should also point out that in addition to other more obvious sources of noise, like Jeff and Solomon noted recently in another thread, even some seemingly irrelevant things like which query runs first in a batch or which batch runs first between two can introduce mild, consistent differences between elapsed times even if plans are already compiled and all data is already in the buffer pool, so getting results from a control test to see what kind of variance is expected even for identical queries is important.
Cheers!
-
good to see that at least 2 members did understand what I was stating about count(*) vs count(1).
Brahmanand stated that "count(*) would need to read all data from the table" and this is what I said was incorrect - performance as proven by Jacob can go up and down in either case but main thing is that only the index used by the engine is required - that may or not be the clustered index, but if the engine decides to use another index it does not need to do a lookup to read the remaining data from the table.
- frederico_fonseca wrote:
good to see that at least 2 members did understand what I was stating about count(*) vs count(1).
Brahmanand stated that "count(*) would need to read all data from the table" and this is what I said was incorrect - performance as proven by Jacob can go up and down in either case but main thing is that only the index used by the engine is required - that may or not be the clustered index, but if the engine decides to use another index it does not need to do a lookup to read the remaining data from the table.
It was a myth that I was bringing with me since years and was cleared when I did that test which I posted in my earlier reply. If you would have seen that then you will find I've mentioned "Physical and Logical Reads were same". This is now proved that COUNT really does not reads the pages (neither with * nor with a constant), it's the columns of WHERE clause that causes the reads in terms of table scan (in the absence of index) or the Index Scan and pages associated with the scan.
I also did not posted the rerunnable test scripts due to which Jacob had to do it from scratch. I really fee bad about it !
I must appreciate all the efforts made by Jeff and Jacob to follow this thread and proving the myth !!
Efforts spent by Jacob is really worth applause and 5 stars to the analysis published by him !!
I think this thread is one of the most purposeful and productive thread I've seen in the recent few weeks. Sometimes, a lot of good things come out of a mess 🙂
I feel we must conclude in order to make this thread complete in nature so that future readers should get benefited with the healthy discussion we had.
Can we conclude there is absolutely no difference between COUNT(1) & COUNT(*) ? or COUNT(*) is better than COUNT(1) ?
-
First the conclusion :
Count(1) and count(*) perform similar.
Getting the count from the meta tables is a lot faster.
Based on a test with a table with 1 000 000 (one milion) rows.
dbcc dropcleanbuffers
SELECT COUNT(*) FROM plate2 -- timing around 0.32 secs (From 0.316666 to .3333333)
dbcc dropcleanbuffers
SELECT COUNT(1) FROM plate2 -- timing around 0.32 secs (From .316666 to .4366666)
dbcc dropcleanbuffers
SELECT o.name, SUM(p.rows) sum_rows FROM sys.objects o
JOIN sys.partitions p ON o.object_id = p.object_id
WHERE p.index_id IN (0, 1) and o.name = 'plate2'
GROUP BY o.name order by sum_rows desc
-- timing around 0.06 seconds (From .05666 to .07666666)With dropcleanbuffers removed, the timing for the count(*) and count(1) goes to around 0.06 seconds. For the last query the time goes to 0 (zero) seconds.
Ben
Database specifics:
-- Field Value--
-- 01 Generated 2019-12-12 09:31:00--
-- 04a Version -- SQL Server Microsoft SQL Server 2008 R2 (SP3-GDR) (KB4057113) - 10.50.6560.0 (X64) Dec 28 2017 15:03:48 Copyright (c) Microsoft Corporation Developer Edition (64-bit) on Windows NT 6.1 <X64> (Build 7601: Service Pack 1)--
-- 04b Version -- SQL Server 10.50.6560.0 - SP3 (Developer Edition (64-bit))--
-- 05 user dbo--
-- 06 Startuptime 2019-12-12 08:48:59.850--
-- 07 Database --------------------------------------------------------
-- 08 Databasename TestDb--
-- 10 Recovery SIMPLE--
-- 11 Status ONLINE--
-- 12 Collation SQL_Latin1_General_CP1_CI_AS -
Getting the count from the meta tables is a lot faster.
I guess, that's purely depend upon the STATISTICS which is calculated using the HISTOGRAM with up-to 200 samples. STATISTICS is purely maintained by SQL Server unless we want to update it before getting the number of rows. I'm not sure if we can guarantee the correctness of the count returned from sys.partitions system table. Data authenticity is also equally important with performance.
At least this is what I feel. I could be wrong also. Other participating members can share their opinion.
-
The query is (to my knowledge) not based on the updated statistics. I have been using this query a lot on many different systems and use this query mainly to see what is happening in a short time. (Take one measurement, do something, take another measurement and see what the difference is). The numbers always came out as expected by me. So although I do not give a guarantee, I never have seen this fail. **)
If I am wrong, please inform me.
Thanks for your comments,
Ben
**)
(It might be that during open transactions the count all ready includes not committed actions within the count).
Viewing 8 posts - 16 through 23 (of 23 total)
You must be logged in to reply to this topic. Login to reply