Everything is Code
-
Comments posted to this topic are about the item Everything is Code
-
From the Article:
That's a tough process to implement, and one many companies don't spend the time doing, but for those that do, they end up deploying many fewer bugs.
That's what we've done. Actually, we did it almost 12 years ago and have been enjoying nearly bug free success since. It is NOT CI/CD at all. It's good ol' rock solid development methods, a.k.a. "Waterfall" for the big stuff and abbreviated versions for the urgent stuff. We were doing what a lot of people call "NetOps" long before it became a term. In fact, I've been doing it since the '80's.
"Make it work, make it fast, make it pretty... and it ain't done 'til it's pretty".
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Two comments on this topic. First, I like what you said, Steve, "I think part of the reason that people try to ignore config data is that it is hard to manage." I completely agree with you. Occasionally I have to create GitHub Actions, i.e.: YAML files. It is not easy developing YAML files. There's very little to help me. There's no such thing as a breakpoint like I would have in Visual Studio or other programming languages. And there's only rudimentary printing, like in the old days when I would put in printf statements throughout the code to figure out what was going wrong. Honestly, I don't find writing YAML to be fun at all. And even using GitHub Copilot is only somewhat helpful.
The other thing, at least where I work, is people tend to think that writing YAML files is something that, "only the GitHub Administrator does". That is 100% false!!! Millions of developers worldwide write their own YAML code on GitHub and other DevOps platforms.
Kindest Regards, Rod Connect with me on LinkedIn.
-
For me, I often find I have a "test repo" or a "test pipeline" alongside the real one because I constantly run into things that I don't quite know how to do. So I copy things over, experiment, and test. For repos, a fork is good so you don't clutter the main repo up with branches.
- Jeff Moden wrote:
"Make it work, make it fast, make it pretty... and it ain't done 'til it's pretty".
I like this Jeff. I wish my place didn't stop at "Make it work". If you want your end users to appreciate the work you do, doing all 3 is important.
-
Ha, I certainly make it work and make it fast. The pretty part I have to depend on others because I'm lost beyond basic HTML, SQL tables, or stealing code from others that a client says looks good.
- Rod at work wrote:
Occasionally I have to create GitHub Actions, i.e.: YAML files. It is not easy developing YAML files. There's very little to help me.
Rod, I use Visual Studio code with the GitHub Actions extension from Omar Tawfik. It makes writing the workflow YAML files far simpler and robust.
I use https://www.yamllint.com/ to format the files
For command line tooling I use YQ. This website gives some useful examples. https://dev.to/vikcodes/yq-a-command-line-tool-that-will-help-you-handle-your-yaml-resources-better-8j9. The tool does much of what the JQ tools does for JSON but also covers YAML and can convert JSON to CSV and vice verse.
-
We use Terragrunt/Terraform for infrastructure as code and deploying different config for different environments.
As our CICD pipelines are GitHub workflows we use Github environment secrets. One of the inputs to a workflow is the environment name and for a specific variable the value appropriate for the environment is used.
One thing we have found is that we have a number of data pipeline applications that have a lot of commonality between their config data. This caused us some headaches because we would have to change the value for, say a file location, in more than place. What we worked out was that we could have a larger master config file and the deployment process would extract the parts relevant for each application to produce the smaller config files needed for that application.
In a past role my company underwent a quarterly audit that asked who had access to what, what level of access and how was it validated and audited.
It was useful being able to show that config data was under centralised version control and could only be deployed through a mechanical pipeline that included validation.
Many things in software engineering are hard to bolt on as after market additions. If they are built in as foundation stones then their adoption is much smoother and more reliable.
-
"Everything is code" as the follower of "code as data"? Data in VCS... but not hard coded in the code 🙂 The data do not belong to the code, but still alongside.
Testing PROD config tend to be hard. it is the part of code that differs from other environments. That being said they are ways to tame this issue and if it is under source control it can be reviewed and controled for changes and pipeline deployed. That only nake it worth pushing it to git.
Would you have different repo / pipeline for the logic vs the config?
And to be VCS ready is just the beginning. We also need to have tool not playing the game of shuffling the yaml or xml every time we do changes in the dev UI. Merge conflicts and collaboration on code is okay, merge conflicts on config files can really be a show stopper.
We rework the SSIS XML before the commit to get changes we can "easily" track in the commit... just to discover how fabric plays with our yaml... a good tool is what will make the difference between a okay day and a nightmare.
- David.Poole wrote:Rod at work wrote:
Occasionally I have to create GitHub Actions, i.e.: YAML files. It is not easy developing YAML files. There's very little to help me.
Rod, I use Visual Studio code with the GitHub Actions extension from Omar Tawfik. It makes writing the workflow YAML files far simpler and robust.
I use https://www.yamllint.com/ to format the files
For command line tooling I use YQ. This website gives some useful examples. https://dev.to/vikcodes/yq-a-command-line-tool-that-will-help-you-handle-your-yaml-resources-better-8j9. The tool does much of what the JQ tools does for JSON but also covers YAML and can convert JSON to CSV and vice verse.
Thank you, David! I'm not familiar with any of those, so I appreciate ti. BTW, what's the name of the GitHub Actions extension by Omar Tawfik? I tried searching by his name but couldn't find it.
Kindest Regards, Rod Connect with me on LinkedIn.
- Rod at work wrote:
Thank you, David! I'm not familiar with any of those, so I appreciate ti. BTW, what's the name of the GitHub Actions extension by Omar Tawfik? I tried searching by his name but couldn't find it.
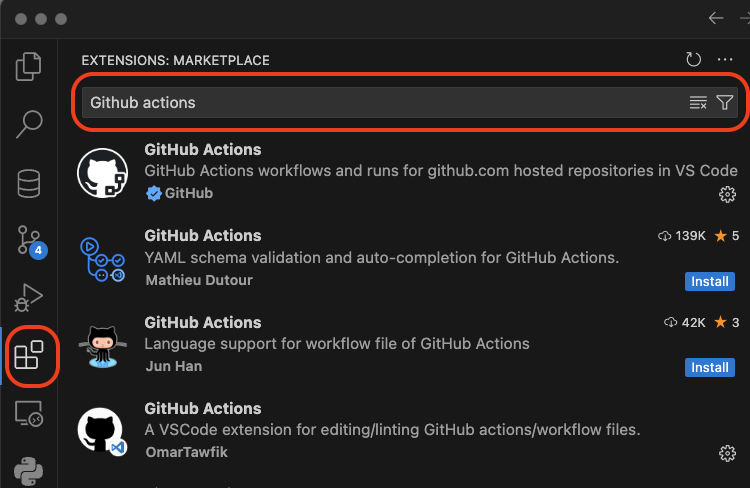
As shown in in Visual Studio code screen shot below
- Choose the extensions panel, selected by clicking the icon circled in red on the left
- In the search bar type Github actions
- Choose the extension you want to try

Periodically I review which extensions I am using and uninstall those I don't use anymore. Having looked at this just now I would look at the extension by Matthew Dutour as an alternative to the one by Omar Tawfik as it has a high number of downloads and 5 star rating.
I notice that there is a Github Actions Locally extension in beta. That could be a Godsend.
Viewing 11 posts - 1 through 11 (of 11 total)
You must be logged in to reply to this topic. Login to reply