dm_db_index_physical_stats - LIMITED or DETAILED
-
I'm interested to hear what most DBAs do to evaluate fragmentation using dm_db_index_physical_stats.
Using this web site as a reference: dm_db_index_physical_stats I have the following reasoning.
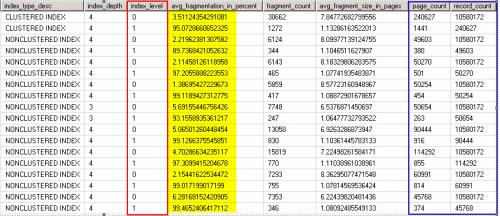
Using LIMITED is very efficient, but only returns details on the Leaf Level of the index. The results show level 0, and on a server I'm reviewing these levels are all very low, typically less than 5% as I manage fragmentation with rebuilds or reorgs.When we use DETAILED, it returns two sets of results, one for the Leaf Level (0), and the other for the Remaining levels (B-Tree), level 1. While the level 0 is the same as for LIMITED, in a lot places the level 1 (B-Tree) fragmentation is far worse at 95%. Here's a sample of the output.

I have reviewed various systems, including Ola Hallengren's code, and they all seem to have hard coded the LIMITED mode. However I'm not sure there isn't value in finding some sort of average for these values, and then using that to define effective fragmentation, or maybe use the worst of the values.
Is anyone using level 1 fragmentation to decide if they should REBUILD or REORG? Anyone got another option? Or is everyone doing the normal thing and using level 0?
Leo
Nothing in life is ever so complex that with a little effort it can't be made more complexLeo
Nothing in life is ever so complicated that with a little work it can't be made more complicated. - Leo.Miller - Monday, July 23, 2018 8:59 PM
This will come as a shock to you because it likely violates everything that you've been taught about index fragmentation.
First, the fragmentation at the B-Tree levels don't really matter that much. If you're going for a single row, it doesn't matter because it will have to travers the B-Tree to get to the row and fragmentation doesn't matter for single rows.
Second, fragmentation isn't going to matter for seeks followed by a range scan because, just like finding one row (a seek), it will find (ssek) the first row and then scan the leaf level for the rest.
Also, there's really only one place where fragmentation really matters and I've done literally hours of testing to prove it. The only place fragmentation matters is when the system needs to read from disk because what you're asking for doesn't already exist in memory. Even more strictly defining where fragmentation matters is when the system tries to do read-aheads for something not already in memory. Once in memory, you can wallop on the data all day and night with no degradation that most people could notice even if the fragmentation is at 99.9%. How can that be? Simple... remember what the acronym "RAM" stands for... Random Access Memory and it's very fast in finding out of order pages that are proverbially yards apart. That's why a lot of people cherish SSDs because they're non-volatile Random Access Memory and even nasty ol' Read-Aheads on a fragmented index aren't much of a bother.
To wit, I've not done regularly scheduled index maintenance since Sunday, 17 Jan 2016 and performance actually improved in the first 3 months and has remained in the improved state since then. I do, however, rebuild statistics on a fairly regular basis.
So far, all we've talked about is "logical fragmentation" where the pages are logically in a different order than the physical order on disk. Let's talk about the other type of fragmentation, which is called "physical" fragmentation. There are two types. The first type is that not all pages of any table are necessarily contiguous. There are a few exotic tricks to help that somewhat but most people just live with it. This can also happen on the underlying disk and that's where disk defragmentation tools have come into play. Most people don't bother anymore because SANs (and certainly SSDs) handle that pretty well (although sector offset can still be a problem if the SAN manufacturer didn't do it right).
The other type of physical fragmentation affects not only space on disk but space in memory and that shows up in sys.dm_db_index_physical_stats as "avg_page_space_used_in_percent" and I know of few people who even give it a second look when it's actually one of the most important factors especially when it's combined with knowledge of logical fragmentation (avg_fragmentation_in_percent), the FILL FACTOR, the average size of rows, and what kind of index you actually have on your hands.
And, no... by "kind of index", I'm not referring to index types such as Clustered and Non-Clustered indexes. I'm talking about "even distribution inserts", "append only inserts", "expAnsive updates", "silo inserts", "silo updates", "Deletes", and combinations of many of those.
Paul Randal said it best when he wrote it in Books Online...
Fragmentation alone is not a sufficient reason to reorganize or rebuild an index. The main effect of fragmentation is that it slows down page read-ahead throughput during index scans. This causes slower response times. If the query workload on a fragmented table or index does not involve scans, because the workload is primarily singleton lookups, removing fragmentation may have no effect.
What I found on that fateful morning of Monday, 18 Jan 2016 (the day after index maintenance) was that the index maintenance, particularly the REORGANIZEs, where taking away much needed page free space and that caused an insane amount of page splits that actually crippled the system bad enough so that it was noticeable by the users and certainly noticeable by the run durations of the batch jobs and the amount of log file activity that was generated..
I do occasional rebuilds to recover disk space on some of the larger indexes but not before I've identified what KIND (rather than type) of index I'm dealing with.
I'm also working on methods to automatically figure what KIND of index I might be dealing with but I'm not done with the full analysis and coding yet.
Getting back to your original question, don't worry about fragmentation in the B-Tree. The use of "LIMITED" (which, ironically, never touches the leaf level to get the leaf level information) will do just fine unless you're doing a deeper analysis and need super accurate leaf level information and information from the columns that are "NULL" in the "LIMITED" model.
I will say, though, that I don't ever use the "LIMITED" model because it doesn't actually go near the Leaf Level and that means that it provides absolutely no clue about "Page Density" (avg_page_space_used_in_percent). Instead, I use the "SAMPLED" model, which is slower than "LIMITED" but a whole lot faster than "DETAILED" because "SAMPLED" only looks at every one hundredth page after the index gets to a certain size and it provides as much aggregated information about the every hundredth collection of pages as "DETAILED" does.
Again, though, I don't do regular index maintenance and when I do some maintenance on a given index, I don't follow the supposed "Best Practice" of...
<10% do nothing
10-30% Reorg
>30% Rebuild
...because not all KINDs of indexes are the same and each requires deep esoteric knowledge (and, sometimes special technique if the index is huge like rebuild to a temporary file group and rebuild back again and then drop the temporary file group to keep from blowing out the MDF). I'm also finding out the REORGANIZE can be a real problem for certain KINDs of indexes.Heh... that came out kind'a long, didn't it? 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
The issue is, getting the exact detailed information isn't going to radically change the majority of your systems and it costs a lot more to produce. So, slightly better information that's not much more actionable for a greater cost... Nah, I'll pass.
Hey Jeff! Have you done defrag testing on columnstore as well as rowstore? Just curious because I suspect (but don't know for 100% certain), that defragmentation of columnstore indexes could be useful since it moves rows from the delta store to the pivoted, deduped, columnstore storage as well as completing logical deletes to actually remove deleted rows.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning - Grant Fritchey - Tuesday, July 24, 2018 10:10 AM
I've not had the opportunity to even play with columnstore. IIRC, if you set it up, you can't un-set it up. Is that a true statement?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Tuesday, July 24, 2018 8:10 PM
Only of the clustered index. You'd have to migrate that data into a new rowstore table. The nonclustered columnstore index you can add & drop to your heart's content (now, I know I don't have to tell YOU to not do this in a production system, but for others out there, don't add & drop a columnstore over & over on your production system).
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
Thanks Jeff for your great response, there's a lot of good material in that. Being in the SQL Server Managed Services business I (we) have too many clients to customize my optimization to the level you are talking about. I also still have many customers not on SSDs or flash storage, so I'm looking at this from a generic best practice perspective. Basically deciding if our current solution should be modified to accommodate the B-Tree data or not, and if it should, to what extent and how. Also, many of my clients have 3rd party applications that to be honest can be pretty badly designed, with no option to redesign, so SCANs are not that unusual. In this situation (thanks Paul Randal) there is benefit in optimizing.
Based on the distinct lack of responses, it looks like there are very few people looking at this beyond basic optimization.
This comment from you was very interesting and makes a lot of sense:
The other type of physical fragmentation affects not only space on disk but space in memory and that shows up in sys.dm_db_index_physical_stats as "avg_page_space_used_in_percent" and I know of few people who even give it a second look when it's actually one of the most important factors especially when it's combined with knowledge of logical fragmentation (avg_fragmentation_in_percent), the FILL FACTOR, the average size of rows, and what kind of index you actually have on your hands.
And, no... by "kind of index", I'm not referring to index types such as Clustered and Non-Clustered indexes. I'm talking about "even distribution inserts", "append only inserts", "expAnd, no... by "kind of index", I'm not referring to index types such as Clustered and Non-Clustered indexes. I'm talking about "even distribution inserts", "append only inserts", "expAAnsive updates", "silo inserts", "silo updates", "Deletes", and combinations of many of those.nsive updates", "silo inserts", "silo updates", "Deletes", and combinations of many of those.
I'm aware of this "kind of index" concept, and as I understand you, you are identifying the index kind based on where new values are added within the index structure. So an "append only inserts" index would be something like a timestamp, where any new value is always going to be added on the logical "end" and not in the middle of the B-Tree and/or Leaf Level (assuming sequential timestamps). My thought is that an "append only insert" index would show no fragmentation, so would (almost) never need to be optimized once created, where an "even distribution inserts" index would become fragmented and so eventually need to be optimized. So as I see it, the fragmentation behavior would identify the kind of index, and is still a reflection of whether an index should be optimized.
In my situation dealing with so many diverse servers, SANs, and databases/applications, unless I have specific instructions not to optimize (which I could manage down to an index level if I needed to) I would prefer to carry on as we currently do, and determine if there are ways I can improve the process generally for every client. I have more clients complaining about poor performance when there is no optimization (before we support their servers) than after we take them on and optimize. Where we optimize and have had performance problems we have always been able to find some sort of solution, and I'm not aware of any research that expressly says optimization negatively impacts performance.
Leo
Nothing in life is ever so complex that with a little effort it can't be made more complexLeo
Nothing in life is ever so complicated that with a little work it can't be made more complicated. - Leo.Miller - Wednesday, July 25, 2018 8:46 PM
I have the same problem with just one server. 😀 That's why I'm working on methods to "auto-discover" the types of things I talked about and to implement them in a mostly "auto-magical" way.
Basically deciding if our current solution should be modified to accommodate the B-Tree data or not, and if it should, to what extent and how.
I'll repeat myself here... I wouldn't worry about the B-Tree for the reasons I stated. There may be the occasional extreme use case where concern over the B-Tree may have some benefit but I've not yet run into one.Also, many of my clients have 3rd party applications that to be honest can be pretty badly designed, with no option to redesign, so SCANs are not that unusual.
Again, repeating myself... scans aren't helped by index defragmentation based on logical fragmentation except on the very first scan after the data/index is knocked out of RAM when read-aheads are likely to occur. Paul Randal clearly stated that both in Books Online and in many of his wonderful presentations and I've verified that with literally a hundred hours of testing. If you don't pay attention to the page density, you could be wasting a whole lot of memory that can really hurt boxes with lower amounts of RAM. And let me know if those 3rd party apps are using GUIDs for PKs/Clustering Keys... I know how to fix those so that fragmentation is almost non-existent.... and, no, that's not a misprint or a mistake. I've tested the bejeebers out of how to do index maintenance on those that virtually eliminates all page splits during inserts.My thought is that an "append only insert" index would show no fragmentation, so would (almost) never need to be optimized once created
Absolutely correct ... unless it also suffers "expAnsive" updates. Gotta especially hate those "Modified_By" columns unless they have an integer datatype. 😀I have more clients complaining about poor performance when there is no optimization
If by "optimization" you mean standard "Best Practice" methods for index optimization, I had my main server drop from doing massive timeouts caused by massive blocking on Mondays and, generally, a 22% usage across all CPUs to no blocking on Mondays and, over a 3 month period, have CPU drop to an average of 8% by using Brent Ozar's wonder method for index maintenance... which is to stop doing scheduled "Best Practice" index maintenance. 😉 I've not rebuilt indexes on my production box on a regular basis since Jan of 2016. I have reworked a couple of very large indexes when page density gets too low but that's far and few between. It's much more effective to keep stats up to date. As a part of my more than a hundred hours of testing, I can actually demonstrate why it's better to not do any maintenance on certain types of indexes than it is to use the standard REORGANIZE between 10 and 30 % and REBUILD after 30%. Stop and think about that... the ONLY thing that cause fragmentation is bad (or "nasty", as Paul Randal calls them) page splits and by the time you've gotten to 10% fragmentation, most of the damage that bad page splits can cause has already happened. Just when you start to naturally get enough room for the page splits to taper of quite a bit, people make the mistake of using REORGANIZE, which actually removes all that free space and it becomes a self-perpetuating need to defrag along with a raft of bad page splits right after the REORGANIZE. If you have a 100% FILL FACTOR index (or even 80-90 FIll Factor but 100 is a guarantee of really bad) that isn't "append only" or that suffers widely distributed and the fragmentation gets to 30% or more on a daily or even weekly basis, then the bad page splits are actually crushing performance (and no one realizes it because it has become "the norm") and the REBUILDs (or REORGANIZES if you catch it before 30) that occur are perpetuating that problem in a massive way.But, getting back to your original question, there's usually no need to monitor B-Tree fragmentation nor react to it..
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
I'm really interested in this:
And let me know if those 3rd party apps are using GUIDs for PKs/Clustering Keys... I know how to fix those so that fragmentation is almost non-existent.... and, no, that's not a misprint or a mistake. I've tested the bejeebers out of how to do index maintenance on those that virtually eliminates all page splits during inserts.
Fed up with developers who think GUIDS are a handy way of creating unique keys as clustered indexes. Then after half a day the table is fragmented to hell and queries are taking forever because every 2nd read has to load a new extent from disk to get the data. And as with most clients, more memory isn't an option :angry: I'm aware that depending on how the GUID is being created it can effectively be incremental, but I've only seen this on a few environments.
Actually have a client that one of our consultants is working with at the moment with this issue.
I also did some investigation around the wasted space in memory and was surprised to see that a sequential, clustered index on a BIGINT column was 90%+ empty space. This needs some investigation to work out what's going on.
Leo
Nothing in life is ever so complex that with a little effort it can't be made more complexLeo
Nothing in life is ever so complicated that with a little work it can't be made more complicated. - Leo.Miller - Thursday, July 26, 2018 8:40 PM
Starting from the bottom up...
I also did some investigation around the wasted space in memory and was surprised to see that a sequential, clustered index on a BIGINT column was 90%+ empty space. This needs some investigation to work out what's going on.
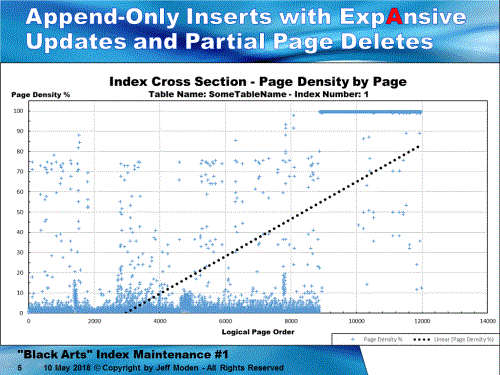
It's probably one of these...
This clustered index has an ever-increasing BIGINT Key. The Y axis on the chart above is "Page Density" or "% of page fullness". The X axis is the logical order of the pages so it also indicates time from left to right. Each Blue plus-sign represents how full a given page is.As you can see in the upper right, almost all of the pages are nearly 100% full. As you go back in time (to the left), you can see that the pages were first split by "ExpAnsive" updates and then there were a good number of deletes of "old rows" without deleting all rows from pages. This particular clustered index contains 11,980 pages (only 93MB) but most of that is wasted. The average percent of page fullness is only 28.287%. It's a real live "queue" table, which explains the deletes (in this case). Ironically, this also indicates a process problem because not all older rows are being removed which means the rows have been orphaned for some reason and will never be processed.
As for GUIDs, especially random GUIDs, except for the fact that they're 16 bytes long and a bitch to read and type, they're actually one of the "better" keys to us IF AND ONLY IF you understand how to defragment them and when.
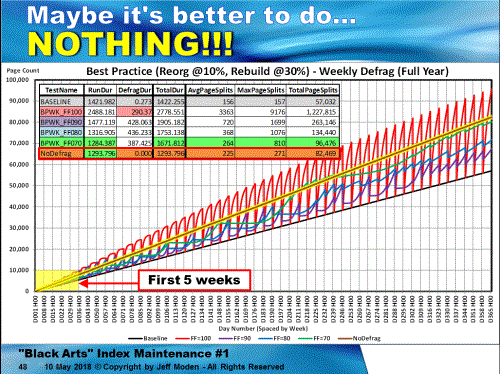
Here's what happens to your GUIDs as defragmentation happens each week as 1,000 rows per hour are added for 10 hours per day with the "Best Practice" recommendations of REORGANIZE between 10 and 30% fragmentation and REBUILD after 30% for various FILL FACTORs. Anything above the Black line (which is all good page splits for ever increasing GUIDs) is virtually ALL bad page splits and the steeper the increase, the worse the page splits are. Vertical downward lines are when defragging occurs. The Brown Line with the kind of Yellow halo is if you do no index maintenance! Although the page splits are present every hour, they're much more gentle than any Fill Factor index maintenance. The problem is, it "settles out" at a 68% Fill Factor.
Note that the axis on the following charts are different than on the one above.
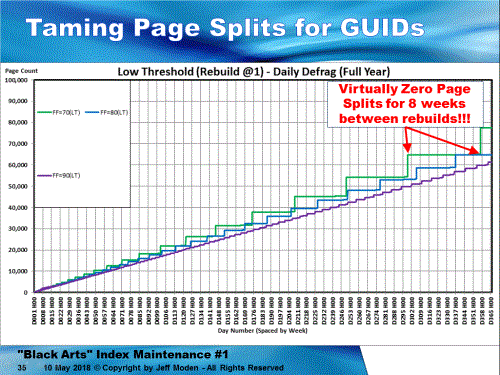
Of course, the problem with ALL of those scenarios, even the Black line with ever-increasing sequential GUIDs is that they're ALL riddled with page splits. If you check out the following, there are virtually NO PAGE SPLITs. The vertical jumps upwards are when index maintenance happens but the flat horizontal lines are proof that even though we're inserting 10,000 rows per day and the pages are getting fuller, there are virtually no page splits.
The keys to maintaining random GUID indexes are...
1. NEVER REORGANIZE!!!! Only do REBUILDs.
2. Check for fragmentation every day.
3. As soon as fragmentation hits or exceeds 1%, do a REBUILD right away!
Notice that after the index has grown for nearly a year, we go for 8 weeks without any page splits (no fragmentation because of that) at 70% FILL FACTOR and about 4.5 weeks at an 80% FILL FACTOR. Remember that the pages are, in fact, being filled by additional rows so page density is increasing. It's not like they're constantly wasting 20 or 30% free space!For the sake of all that is holy in SQL Server, NEVER use those bloody NewSequentialID's. Use only Random GUIDs so you can take advantage of zero page splits, which even an ever-increasing BIGINT can't do.
If you know someone that's using something like SharePoint, where everything is based on GUID keys, show them this post!
For the record, the rows in the two charts immediately above this are 123 bytes including the row header overhead. The duration between rebuilds will be affected depending on row size. The wider the rows, the less that duration will be but you'll still get the "flats" where pages splits aren't occurring until just before you defrag. Doing the defrag at such a low percentage keeps you from having a very steep upramp of page splits the day before you defrag (and it MUST be a REBUILD... REORGs actually remove the necessary freespace, which actually causes some pretty severe fragmentation to occur starting right after the REORG!)
And, to be sure, when I say "daily defrags", I don't mean that the index will be defragged on a daily basis. I mean that you have to execute the code (everyday) that checks for fragmentation and then only defrags when you hit 1% fragmentation.
And, finally, this table only has 3.65 million rows in it (4.489GB). As an added bonus to GUID keyed indexes. look at that last chart and see the "flats" and the time between actual REBUILDs where no fragmentation occurs gets longer and longer as more and more rows are added. And remember that the index (table if it's the Clustered Index) isn't sitting at only 70% full. During the long "flats", the pages ARE actually getting fuller and they're doing so quite evenly (which is great for memory, disk usage, and performance of SELECTs). They're just not splitting and so there's no increase in pages because there are no page splits (which is a great performance improvement for INSERTs) which means there's also no fragmentation (which is a great performance improvement where read aheads are concerned) which means you don't have to defrag very often! Last but not least, they totally eliminate INSERT "Hot Spots"! WIN! WIN! WIN! WIN! WIN!
Because of their randomness and number of GUIDs in the domain and contrary to popular belief, GUIDs may actually be the perfect clustering key when it comes to fragmentation IF YOU KNOW HOW TO DEFRAG THEM. 😀 And now you DO! 😉
Now all you have to do is worry about "Expansive" updates, especially if you have one of those bloody VARCHAR "Modified_BY" columns. :sick: I've got fixes for those, as well, but this post is already the length of a small article so I'm going to quit for now. 🙂
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
p.s. Am I suggesting that you should use GUIDs in all cases? NOT ON YOUR LIFE! If you truly have an APPEND ONLY INSERT index that suffers no "ExpAnsive" updates, then there will be no index maintenance requirements for the entire life of the index (although it WILL suffer the classic "End of Index HOT SPOT"). As with all else in SQL Server and T-SQL, "IT DEPENDS!" 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 10 posts - 1 through 10 (of 10 total)
You must be logged in to reply to this topic. Login to reply