Deduplicate records based on more than one field with different field values
-
I am currently trying to dedupe a customer table based on both the email and phoneno fields. I can identify where they both have duplicates or where each one has duplicates using code similar to the below.
SELECT *, DENSE_RANK() OVER (ORDER BY Email) EmailRank
FROM Customer
WHERE EMail IN
(
SELECT Email
FROM Customer
GROUP BY EMail
HAVING COUNT(*) > 1
)
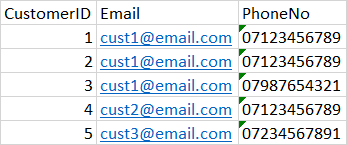
However i have records like below where if i do the above on email, rows 1 through 3 are identified as the same or if i do so on phoneno, rows 1,2 and 4 are the same. What i want to do is identify where rows 1 through 4 are the same because email and/or phoneno are the same. Once i have this information I have a date field that i can then use to identify the most current record to keep and delete the older ones.

-
Here's a long-winded way - nothing better comes to mind right now.
Please provide set-up data in future - you'll find that people are more willing to help if you do so.
DROP TABLE IF EXISTS #customer;
CREATE TABLE #customer
(
CustomerId INT IDENTITY(1, 1) PRIMARY KEY CLUSTERED
,Email VARCHAR(100) NOT NULL
,PhoneNo VARCHAR(50) NOT NULL
);
INSERT #customer
(
Email
,PhoneNo
)
VALUES
('cust1@email.com', '1234')
,('cust1@email.com', '1234')
,('cust1@email.com', '5678')
,('cust2@email.com', '1234')
,('cust3@email.com', '9876');
WITH DupeEmails
AS (SELECT cq.Email
FROM #customer cq
GROUP BY cq.Email
HAVING COUNT(cq.Email) > 1)
,DupePhone
AS (SELECT cq.PhoneNo
FROM #customer cq
GROUP BY cq.PhoneNo
HAVING COUNT(cq.PhoneNo) > 1)
SELECT c.*
FROM #customer c
JOIN DupeEmails
ON c.Email = DupeEmails.Email
UNION
SELECT c.*
FROM #customer c
JOIN DupePhone
ON c.PhoneNo = DupePhone.PhoneNo; -
Or this, given that I think you want either/or rather than both. But Phil's right - table DDL in the form of CREATE TABLE statements, sample data in the form of INSERT statements and expected results make it easier to understand your requirements and test any solution we may come up with.
WITH IdentifyDuplicates AS (
SELECT
Email,
, PhoneNo
, COUNT(*) OVER (PARTITION BY Email) AS NoofEmails
, COUNT(*) OVER (PARTITION BY PhoneNo) AS NoofPhones
FROM Customer
)
SELECT
Email
, PhoneNo
FROM IdentifyDuplicates
WHERE NoofEmails > 1
OR NoofPhones > 1;John
-
That's a much better solution, thanks John. <Phil heads for coffee break>
-
Thanks guys and appologies for not giving DDL stuff to assist. First post and missed that one.
Those weren't quite what i was looking for but may have actually helped me solve the issue (although maybe not in the best way!) My solution below for reference. I do need to go away and test this on my actual data source to make sure it isn't doing anything wrong but it appears to work for all intents and purposes.
CREATE TABLE #Customer
(
CustomerId INT IDENTITY(1, 1) PRIMARY KEY CLUSTERED
,Email VARCHAR(100) NOT NULL
,PhoneNo VARCHAR(50) NOT NULL
,EmailDupID INT NULL
,PhoneDupID INT NULL
,UniqueID INT NULL
);
INSERT #Customer
(
Email
,PhoneNo
)
VALUES
('cust1@email.com', '1234')
,('cust1@email.com', '1234')
,('cust1@email.com', '5678')
,('cust2@email.com', '1234')
,('cust3@email.com', '9876');
UPDATE c
SET EmailDupID = EmailRank
FROM
#Customer c
INNER JOIN
(
SELECT *, DENSE_RANK() OVER (ORDER BY Email) EmailRank
FROM #Customer
WHERE EMail IN
(
SELECT Email
FROM #Customer
GROUP BY EMail
HAVING COUNT(*) > 1
)
) e
ON c.CustomerID = e.CustomerID
UPDATE c
SET PhoneDupID = m.MobileRank
FROM #Customer c
INNER JOIN
(
SELECT *, DENSE_RANK() OVER (ORDER BY PhoneNo) MobileRank
FROM #Customer
WHERE PhoneNo IN
(
SELECT PhoneNo
FROM #Customer
WHERE PhoneNo NOT IN ('','07000000000','07123456789')
GROUP BY PhoneNo
HAVING COUNT(*) > 1
)
) m
ON c.CustomerId = m.CustomerId
SELECT * FROM #Customer
SELECT c.EmailDupID, c.PhoneDupID, DENSE_RANK() OVER (ORDER BY a.EmailDupID) DupeID
INTO #DupeID
FROM #Customer a
INNER JOIN
#Customer b
ON a.EmailDupID = b.EmailDupID
INNER JOIN
#Customer c
ON a.PhoneDupID = c.PhoneDupID
GROUP BY a.EmailDupID, c.EmailDupID, c.PhoneDupID
UNION
SELECT c.EmailDupID, c.PhoneDupID, DENSE_RANK() OVER (ORDER BY a.PhoneDupID) DupeID
FROM #Customer a
INNER JOIN
#Customer b
ON a.PhoneDupID = b.PhoneDupID
INNER JOIN
#Customer c
ON a.EmailDupID = c.EmailDupID
GROUP BY a.PhoneDupID, c.EmailDupID, c.PhoneDupID
SELECT * FROM #DupeID
UPDATE c
SET UniqueID = d.DupeID
FROM
#Customer c
INNER JOIN
#DupeID d
ON ISNULL(c.EmailDupID,0) = ISNULL(d.EmailDupID,0)
AND ISNULL(c.PhoneDupID,0) = ISNULL(d.PhoneDupID,0)
SELECT * FROM #Customer
DROP TABLE #Customer
DROP TABLE #DupeID
Viewing 5 posts - 1 through 5 (of 5 total)
You must be logged in to reply to this topic. Login to reply