Create Unique combination as Key out of N columns
-
And what if one or more of the column values change?
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:
And what if one or more of the column values change?
Like I said in the comments in the code...
-- You can use that same formula in an INSERT and UPDATE trigger to maintain
-- the table. I don't recommend using a PERSISTED computed column because
-- CONCAT is a system scalar function and Brent Ozar has proven that those
-- (or UDFs) will not allow queries against the table to go parallel if
-- such things are present even if they're not in the query.
--REFs: https://www.brentozar.com/archive/2020/10/using-triggers-to-replace-scalar-udfs-on-computed-columns/--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:ScottPletcher wrote:
And what if one or more of the column values change?
Like I said in the comments in the code...
-- You can use that same formula in an INSERT and UPDATE trigger to maintain
-- the table. I don't recommend using a PERSISTED computed column because
-- CONCAT is a system scalar function and Brent Ozar has proven that those
-- (or UDFs) will not allow queries against the table to go parallel if
-- such things are present even if they're not in the query.
--REFs: https://www.brentozar.com/archive/2020/10/using-triggers-to-replace-scalar-udfs-on-computed-columns/But presumably we're using the hash as some type of joining key (why else would we to go to the trouble to generate it?). How would we know how to accurately change the links in other tables?
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:Jeff Moden wrote:ScottPletcher wrote:
And what if one or more of the column values change?
Like I said in the comments in the code...
-- You can use that same formula in an INSERT and UPDATE trigger to maintain
-- the table. I don't recommend using a PERSISTED computed column because
-- CONCAT is a system scalar function and Brent Ozar has proven that those
-- (or UDFs) will not allow queries against the table to go parallel if
-- such things are present even if they're not in the query.
--REFs: https://www.brentozar.com/archive/2020/10/using-triggers-to-replace-scalar-udfs-on-computed-columns/But presumably we're using the hash as some type of joining key (why else would we to go to the trouble to generate it?). How would we know how to accurately change the links in other tables?
Ah... I see what you're getting at, and I agree. It all depends on what this table is going to be used for and how. Of course, the same would hold true with the 7 individual columns it they were being used as a PK. The OP didn't say that this would be used as a PK but as a UNIQUEfier for these 7 columns and I made the poor assumption that there would be other columns in this table. We definitely need clarification there, so let's ask the OP.
@KTFlash...
Scott is correct that this could become a bit of an "cascading update" nightmare if you use either the MD5 Hash column or even the original 7 columns as a Primary Key.
With that, we have have some concerns for you.
- Will this new column be a referential dependency of any other table? In other words, are you going to use this new column in any type of join in code?
- Will the values of these 7 columns ever be changed on existing rows of the table?
If the answer to question 1 is "YES" and the answer to question 2 is "NO", then most folks would believe that everything will fine without taking addition actions BUT...
I'm sure that Scott will join me in saying that people who plan on such things end up scurrying about in a most un-seaman like manner when the eventuality of change occurs.
With that, I'll suggest that if the answer to Question 1 is "YES", regardless of the answer to Question #2, that you use the ON UPDATE CASCADE option in your Foreign Keys and that you most definitely USE such foreign keys without fail.
As a bit of a sidebar, I have not, to date, ever used an ON DELETE CASCADE option on any FKs and probably never will. It's just t0o easy to make a mistake there.
Here are a couple of links concerning FKs and the CASCADE options.
Overview in MS documentation. Also be sure to read the section on "Indexes on Foreign Key Constraints"
A "drill down" from the article above on how to use the GUI or T-SQL to create FKs with the CASCADE option.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
I still prefer my single int as a metakey method. 16 bytes is a lot of overhead for a linking key. I don't see an advantage to it. And the generated value will be horribly difficult for people to work with.
In my method, I would never change the original metakey. Such keys are generally never changed. I would create a new metakey value for the updated set of values (assuming one didn't already exist for that specific set of values). The corresponding link key(s) could be programmatically updated to the new value.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:
I still prefer my single int as a metakey method. 16 bytes is a lot of overhead for a linking key. I don't see an advantage to it. And the generated value will be horribly difficult for people to work with.
In my method, I would never change the original metakey. Such keys are generally never changed. I would create a new metakey value for the updated set of values (assuming one didn't already exist for that specific set of values). The corresponding link key(s) could be programmatically updated to the new value.
Oh... there's absolutely no question about that. I'm with you there. But, sometimes you have to show the OP the difficulties of the method they want to use for them to understand that their original request may be, at best, an unnecessary complication depending on what they want to use it for and the OP has been holding back a bit on what the true reason for wanting to have a single column is.
Depending on the uses of the table and, in particular, the content and use of the 7 given columns, I'm actually mostly against creating a surrogate key for those 7 columns to begin with. Using them as a Clustered Index (in the absence of anything more reasonable) would be pretty tough on any Non-Clustered Indexes in the areas of disk and memory space but, even then, it's sometimes worth it.
To wit and with both our concerns of a possible truly non-static key column , the only place I can normally see such a column being of any good use is for the rapid determination of identical values during an import of external data for the purpose of merging data with existing data (which would STILL need a decent static key as I'm sure you would agree).
Now, let's hope the OP comes out with more information about the true nature and use of this table. 😉
@KTFlash... you listening to all of this?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:ScottPletcher wrote:
I still prefer my single int as a metakey method. 16 bytes is a lot of overhead for a linking key. I don't see an advantage to it. And the generated value will be horribly difficult for people to work with.
In my method, I would never change the original metakey. Such keys are generally never changed. I would create a new metakey value for the updated set of values (assuming one didn't already exist for that specific set of values). The corresponding link key(s) could be programmatically updated to the new value.
Oh... there's absolutely no question about that. I'm with you there. But, sometimes you have to show the OP the difficulties of the method they want to use for them to understand that their original request may be, at best, an unnecessary complication depending on what they want to use it for and the OP has been holding back a bit on what the true reason for wanting to have a single column is.
Depending on the uses of the table and, in particular, the content and use of the 7 given columns, I'm actually mostly against creating a surrogate key for those 7 columns to begin with. Using them as a Clustered Index (in the absence of anything more reasonable) would be pretty tough on any Non-Clustered Indexes in the areas of disk and memory space but, even then, it's sometimes worth it.
To wit and with both our concerns of a possible truly non-static key column , the only place I can normally see such a column being of any good use is for the rapid determination of identical values during an import of external data for the purpose of merging data with existing data (which would STILL need a decent static key as I'm sure you would agree).
Now, let's hope the OP comes out with more information about the true nature and use of this table. 😉
@KTFlash... you listening to all of this?
I would use a metakey here, I would just make it a single int with no risk ever of a duplicate metakey. Overall, I prefer natural keys when possible -- as I'm sure you know though others here may not -- but I would draw the line at 7(!) ints.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- Jeff Moden wrote:ScottPletcher wrote:
In SQL 2016, it's rarely a waste of disk space. Specifying ROW compression is standard procedure for all tables unless there's a specific reason not to.
"Standard Procedure for ALL Tables"???? Lordy... Be careful about that, Scott. I hope no one even thinks of calling it or using it as a "Standard Procedure". In fact, I would hope that the exact opposite would be true. If there were to be a "Standard Procedure" for this it should be to "AVOID ROW AND PAGE COMPRESSION unless you can PROVE that it will do no harm".
There is good reason not to use it willy-nilly (especially not as a "Standard Procedure" of some ill-conceived supposed "Best Practice" )... it actually DOES waste a huge amount of disk space (and Log File space) and seriously slows down inserts and wastes huge amounts of I/O and CPU time because of the massive number of page splits it causes when it expands to the "next size", which also causes seriously reduced page density not to mention the resulting serious fragmentation on indexes that would ordinarily not suffer from either. Never before has right-sizing been more important!
If you have a link where someone has recommended this practice as a "Standard Procedure" or a bloody "Best Practice", let me know so I can prove to them just how bad an idea it all is! Using it on WORM and totally STATIC tables is a great idea... just on on table that can suffer updates.
Don't take my word for it, though)... try it for yourself! Details are in the comments. (Replace dbo.fnTally with your favorite sequence generator of get the function for the article and the like-name link in my signature line below).
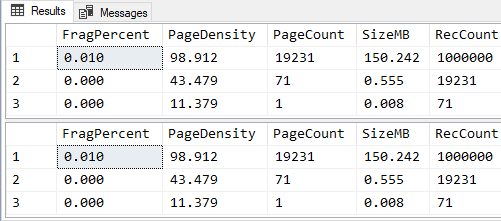
EXPANSIVE INTEGER UPDATES WITHOUT ROW COMPRESSION
/**********************************************************************************************************************
Purpose:
Demonstrate that updates to INT columns from a number that would fit in 1 byte to a number that cannot causes NO
fragmentation WHEN ROW COMPRESSION IS NOT ACTIVE.
This is because the INTs are fixed width when ROW Compression is NOT active.
Revision History:
Rev 00 - 15 Dec 2020 - Jeff Moden
- Initial creation and unit test.
**********************************************************************************************************************/
--===== If the test table exists, drop it to make reruns in SSMS easier.
DROP TABLE IF EXISTS dbo.JBM_RCTest
;
GO
--===== Create the test table with a Clustered PK.
-- Note that ALL of the columns are fixed width and this index should
-- NEVER fragment.
CREATE TABLE dbo.JBM_RCTest
(
JBM_RCTestID INT IDENTITY(1,1)
,IntCol01 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol02 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol03 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol04 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol05 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol06 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol07 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol08 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol09 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol10 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,OtherCols CHAR(100) NOT NULL
,CONSTRAINT PK_JBM_RCTest PRIMARY KEY CLUSTERED (JBM_RCTestID)
WITH (DATA_COMPRESSION = NONE)
)
;
--===== Populate the table
INSERT INTO dbo.JBM_RCTest
(OtherCols)
SELECT String01 = 'X'
FROM dbo.fnTally(1,1000000)
;
--===== Check the Logical Fragmentation and Page Density.
SELECT FragPercent = CONVERT(DECIMAL(6,3),avg_fragmentation_in_percent)
,PageDensity = CONVERT(DECIMAL(6,3),avg_page_space_used_in_percent)
,PageCount = page_count
,SizeMB = CONVERT(DECIMAL(9,3),page_count/128.0)
,RecCount = record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.JBM_RCTest'),NULL,NULL,'DETAILED')
;
--===== Update 4 columns with numbers that usually won't fit in 1 byte.
UPDATE tgt
SET IntCol04 = ABS(CHECKSUM(NEWID())%16777215)
,IntCol05 = ABS(CHECKSUM(NEWID())%16777215)
,IntCol06 = ABS(CHECKSUM(NEWID())%16777215)
,IntCol07 = ABS(CHECKSUM(NEWID())%16777215)
FROM dbo.JBM_RCTest tgt
WHERE JBM_RCTestID % 100 = 0 -- Only updating 1 out of 100 rows
;
--===== Check the Logical Fragmentation and Page Density, again.
SELECT FragPercent = CONVERT(DECIMAL(6,3),avg_fragmentation_in_percent)
,PageDensity = CONVERT(DECIMAL(6,3),avg_page_space_used_in_percent)
,PageCount = page_count
,SizeMB = CONVERT(DECIMAL(9,3),page_count/128.0)
,RecCount = record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.JBM_RCTest'),NULL,NULL,'DETAILED')
;
GORESULTS (absolutely no extra fragmentation caused):

@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
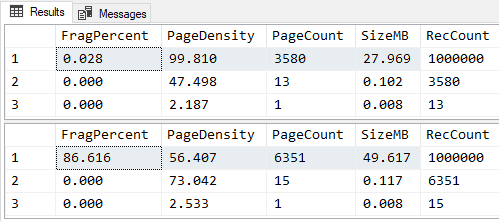
EXPANSIVE INTEGER UPDATES WITH ROW COMPRESSION
/**********************************************************************************************************************
Purpose:
Demonstrate that updates to INT columns from a number that would fit in 1 byte to a number that cannot causes MASSIVE
fragmentation WHEN ROW COMPRESSION IS ACTIVE.
This is because the INTs are NOT fixed width when ROW Compression is active.
Revision History:
Rev 00 - 15 Dec 2020 - Jeff Moden
- Initial creation and unit test.
**********************************************************************************************************************/
--===== If the test table exists, drop it to make reruns in SSMS easier.
DROP TABLE IF EXISTS dbo.JBM_RCTest
;
GO
--===== Create the test table with a Clustered PK.
-- Note that ALL of the columns are inherently variable width thanks to ROW Compression being turned on and
-- THIS INDEX IS SERIOUSLY PRONE TO FRAGMENTATION!
CREATE TABLE dbo.JBM_RCTest
(
JBM_RCTestID INT IDENTITY(1,1)
,IntCol01 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol02 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol03 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol04 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol05 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol06 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol07 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol08 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol09 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol10 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,OtherCols CHAR(100) NOT NULL
,CONSTRAINT PK_JBM_RCTest PRIMARY KEY CLUSTERED (JBM_RCTestID)
WITH (DATA_COMPRESSION = ROW) --THIS IS THE ONLY CODE CHANGE MADE FOR THIS TEST!
)
;
--===== Populate the table
INSERT INTO dbo.JBM_RCTest
(OtherCols)
SELECT String01 = 'X'
FROM dbo.fnTally(1,1000000)
;
--===== Check the Logical Fragmentation and Page Density.
SELECT FragPercent = CONVERT(DECIMAL(6,3),avg_fragmentation_in_percent)
,PageDensity = CONVERT(DECIMAL(6,3),avg_page_space_used_in_percent)
,PageCount = page_count
,SizeMB = CONVERT(DECIMAL(9,3),page_count/128.0)
,RecCount = record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.JBM_RCTest'),NULL,NULL,'DETAILED')
;
--===== Update 4 columns with numbers that usually won't fit in 1 byte.
UPDATE tgt
SET IntCol04 = ABS(CHECKSUM(NEWID())%16777215)
,IntCol05 = ABS(CHECKSUM(NEWID())%16777215)
,IntCol06 = ABS(CHECKSUM(NEWID())%16777215)
,IntCol07 = ABS(CHECKSUM(NEWID())%16777215)
FROM dbo.JBM_RCTest tgt
WHERE JBM_RCTestID % 100 = 0 -- Only updating 1 out of 100 rows
;
--===== Check the Logical Fragmentation and Page Density, again.
SELECT FragPercent = CONVERT(DECIMAL(6,3),avg_fragmentation_in_percent)
,PageDensity = CONVERT(DECIMAL(6,3),avg_page_space_used_in_percent)
,PageCount = page_count
,SizeMB = CONVERT(DECIMAL(9,3),page_count/128.0)
,RecCount = record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.JBM_RCTest'),NULL,NULL,'DETAILED')
;
GORESULTS (MASSIVE fragmentation and reduction in Page Density caused):
I've never seen an UPDATE pattern that bizarre in over 30 years in IT. From 6 to 16,000,000? I can't even imagine the business case that would cause 1 such UPDATE, let alone multiple ones.
But, if you expected such a thing to happen (how ith though??) I guess that would be "a specific reason not to" use row compression as I mentioned.
Varchar expansions are vastly more common, as we both know. I presume you don't use char(30) columns to avoid char columns from expanding beyond their original size.
Sadly there's only a fillfactor (i.e. rebuild factor) rather than a "loadfactor" which would leave the original page with nn% of free space as the page was initially being inserted.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:
I've never seen an UPDATE pattern that bizarre in over 30 years in IT. From 6 to 16,000,000? I can't even imagine the business case that would cause 1 such UPDATE, let alone multiple ones.
It's just an overt demonstration of the problem, Scott. A similar effect can be had simply by changing 255 to 256 across smaller parts of an index. When demonstrating the effects of dynamite, it's simply more fun to watch the larger explosion rather than demonstrating with a pack of lady-finger firecrackers.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - ScottPletcher wrote:
Sadly there's only a fillfactor (i.e. rebuild factor) rather than a "loadfactor" which would leave the original page with nn% of free space as the page was initially being inserted.
Padding?
_____________
Code for TallyGenerator - Jeff Moden wrote:ScottPletcher wrote:
I've never seen an UPDATE pattern that bizarre in over 30 years in IT. From 6 to 16,000,000? I can't even imagine the business case that would cause 1 such UPDATE, let alone multiple ones.
It's just an overt demonstration of the problem, Scott. A similar effect can be had simply by changing 255 to 256 across smaller parts of an index. When demonstrating the effects of dynamite, it's simply more fun to watch the larger explosion rather than demonstrating with a pack of lady-finger firecrackers.
But one byte on a row or two will not typically overflow a page. And it takes precise value changes -- from one byte size to the next -- for it to happen. I wish there were some way to direct SQL to always use 2 bytes instead of ever dropping down to 1, but of course that's not possible.
Overall, though, compression saves so much overhead and time that it's worth trying. Page compression in particular (although it then does take much longer to rebuild a large index.) One can undo the compression if needed. I'm on Enterprise Edition so I can do most of this ONLINE (space permitting, of course).
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
All true, especially since you've implied that "It Depends". And that's the point I'm trying to make. Row compression is not a panacea and it should not be a "Standard Practice" to just up and assign Row Compression to every index. You do have to have to know the data and what the Insert/Update patterns and related Fill Factors should be or you could end up with a heck of a lot of page splits and the blocking and log file usage and index maintenance (which also causes a serious amount of log file usage) that goes along with the page splits.
To do other wise will cause you some serious "morning after maintenance" woes.
With that being said, I will subscribe to the idea that it should definitely be a "Standard Practice" to evaluate indexes for possible Row compression, but not to blindly apply Row compression.
It's like the people that insist that you should "NEVER" used Random GUIDs as a clustered index. While I agree that there are some reasons why you might not want to, there are also some powerful reasons why you should but the naysayers insist that those reasons don't override the massive fragmentation caused by Random GUIDs. And it's all based on mis/disinformation by the people making those claims. It's actually super easy to design a Random GUID keyed clustered index that can go weeks and months with absolutely zero page splits... not even supposed "good ones". Those that think they know how to do that almost always screw it up because they blindly used supposed "Best Practice" methods for maintaining such indexes.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 12 posts - 16 through 27 (of 27 total)
You must be logged in to reply to this topic. Login to reply