Create string from broken hierarchy
-
Hi

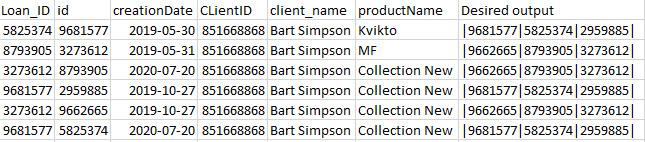
I have a broken hierarchy where I need, for each row, to create a string that contains all possibæe combination ordered by creationdate (id column)
So for the 1st row it would be:
|96811577|2959885|5825374|
as row 3 and 5 contains the same values then the result here should be the same as above.
I can loop and code my way around it, but I hope that someone out there has a simple way to do this 🙂
Thank you
Michael
-
Yeah... the rows you're talking about have a loop in them. We can probably identify the rows not only the way you want them but also mark any rows that are "cyclic", as well. The question is, out of the two columns (Loan_ID and ID), which is actually the "Parent" column in this parent/child (Adjacency List) hierarchy. If I had to make an educated guess, it would be the ID column because it has the least duplication but I have to ask.
I also see a "Parent_Key" column... is there another similar column used for "Child_key" or just some key to the child side of all this regardless of name?
Also, pictures are nice to explain with but they don't help us with testing code. Could you include some "Readily Consumable" data so we can help you better. Please see the article at the first link in my signature line below for one way to do such a thing. Thanks.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Hi Jeff
thanks for reaching out
I have added a script to load a temp table with a subset of my data.
Note that I have removed [PARENTKEY] as this just is the guid matching [id]. [id] will always be unique.
On each [id] the CAN be a reference to a "parent" loan, if this is not the case then that loan sits by itself.
each [id] can refer another loan as it's parent, problem is that it is also, system-wise, allowed to refer a loan ([id]) to multiple other loans.
This also means that [Loan_ID] will ALWAYS exist in [id] as well.
Does it make sense?
Thanks
Michael
CREATE TABLE #temp(
[Loan_ID] [nvarchar](2048) NULL,
[id] [nvarchar](128) NULL,
[creationDate] [datetime] NULL,
[CLientID] [nvarchar](128) NULL,
[client_name] [nvarchar](255) NULL,
[productName] [nvarchar](max) NULL
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
INSERT #temp ([Loan_ID], [id], [creationDate], [CLientID], [client_name], [productName]) VALUES (N'5825374', N'9681577', CAST(N'2019-05-30T23:30:45.000' AS DateTime), N'851668868', N'Bart Simpson', N'Kvikto')
GO
INSERT #temp ([Loan_ID], [id], [creationDate], [CLientID], [client_name], [productName]) VALUES (N'8793905', N'3273612', CAST(N'2019-05-31T02:30:50.000' AS DateTime), N'851668868', N'Bart Simpson', N'MF')
GO
INSERT #temp ([Loan_ID], [id], [creationDate], [CLientID], [client_name], [productName]) VALUES (N'3273612', N'8793905', CAST(N'2020-07-20T18:09:52.000' AS DateTime), N'851668868', N'Bart Simpson', N'Collection New')
GO
INSERT #temp ([Loan_ID], [id], [creationDate], [CLientID], [client_name], [productName]) VALUES (N'9681577', N'2959885', CAST(N'2019-10-27T21:15:14.000' AS DateTime), N'851668868', N'Bart Simpson', N'Collection New')
GO
INSERT #temp ([Loan_ID], [id], [creationDate], [CLientID], [client_name], [productName]) VALUES (N'3273612', N'9662665', CAST(N'2019-10-27T21:16:23.000' AS DateTime), N'851668868', N'Bart Simpson', N'Collection New')
GO
INSERT #temp ([Loan_ID], [id], [creationDate], [CLientID], [client_name], [productName]) VALUES (N'9681577', N'5825374', CAST(N'2020-07-20T18:09:23.000' AS DateTime), N'851668868', N'Bart Simpson', N'Collection New')
GO
-
Ok, try these out with the data you posted above. The "IsCyclic" column should be a big help for you. Like you said, the first one does a whole lot of "looping around" in the form of a Recursive CTE.
--===== This does as you asked with an indication as to where the "broken" parts are.
-- It should be good for as many levels of loans as you have.
WITH cteBuildPath AS
( --=== This is the "anchor" part of the recursive CTE.
-- The only thing it does is load the Root Nodes (treating each ID as a "Root of a separate forest".
SELECT Loan_ID = CONVERT(NVARCHAR(4000),Loan_ID) --Parent Loan#, not unique, always exists as a "child" (ID)
,ID --Child Loan#, is unique, can be a "parent".
,CyclicID = Loan_ID
,HLevel = 1
,IDSortPath = CONVERT(NVARCHAR(4000),CONCAT('|',ID,'|'))
,IsCyclic = 0
FROM #Temp
UNION ALL
--==== This is the "recursive" part of the CTE that adds 1 for each level
-- and concatenates each level of EmployeeID's to the SortPath column.
SELECT Loan_ID = CONVERT(NVARCHAR(4000),tbl.Loan_ID)
,tbl.ID
,CyclicID = cte.CyclicID
,HLevel = cte.HLevel + 1
,IDSortPath = CONVERT(NVARCHAR(4000),CONCAT(cte.IDSortPath,tbl.ID,'|'))
,IsCyclic = IIF(tbl.ID = CyclicID, 1, 0)
FROM #Temp AS tbl
JOIN cteBuildPath AS cte
ON cte.ID = tbl.Loan_ID
WHERE cte.IDSortPath NOT LIKE CONCAT('%|',cte.Loan_ID,'|%') --This stops infinite loops
)
SELECT * FROM cteBuildPath ORDER BY IDSortPath
OPTION (MAXRECURSION 0)
;
--===== This kind of does the same thing without all the duplication.
-- I'm not sure if it will be good for a whole lot of cascading loans.
SELECT tsID = ts.ID, tsLoan_id = ts.Loan_ID
,trID = tr.ID, trLoan_id = tr.Loan_ID
FROM #Temp ts
JOIN #Temp tr ON ts.ID = tr.Loan_ID
AND tr.ID = ts.Loan_ID
;--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Hi Jeff
thanks for replying, can't say how much I appreciate you taking an interest in this
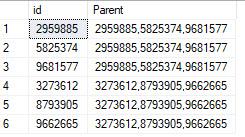
The proposed output correctly links the id's but (as in my own attempts) I get 12 records returned with a concatenation of max 2 id's.
The final output should be the same amount of records (6) with an identically sorted string for each id in the same "family"
I have 2 "families" in the above scenario
Will continue to work with this and update if I find a simple way to to it. In between, I appreciate any input 🙂
Thanks
Michael
-
Have you ever considered normalizing your table? Or following ISO 11179 naming rules? What you did post is a mess. First of all, a table has to have a key, which means you can have all your columns beNOT NULL. This is usually covered the first week of any course on RDBMS! There's no such thing as a generic ID and a valid relational model – an identifier must identify something in particular (remember the law of identity from a refreshmen logic course?).
I have never seen any legal document, such as a loan number, identified with a 2K string in Unicode. Really? You have no regular expression or industry-standard for it? You'll also find that most commercial identifiers are not variable length because it makes them too hard, put on printed forms and screens Let's go back to basics. What are the entities in your data model? Here's my guess:
CREATE TABLE Loans
(loan_nbr CHAR (128) NOT NULL PRIMARY KEY,
..);
CREATE TABLE Clients
(client_duns CHAR(9) NOT NULL PRIMARY KEY,
client_name NVARCHAR(255) NOT NULL,
..);
I'm making a guess that you should be using the DUNS as an identifier because it's very often required by law, has external validation and is an international standard
CREATE TABLE Products
(product_name NVARCHAR(255) NOT NULL PRIMARY KEY,
..);
We now need one or more tables to relate these three entities into a data model. Nobody can do that for you from what you've posted.
I also couldn't figure out what the creation date means. Is it when the client came into the data model? When the loan was issued? Or maybe something to do with the products?
Next, if this is supposed to be a hierarchy, you might've used a nested set model instead of mimicking pointer chains from the non-relational databases of decades ago? This will prevent broken hierarchies. You can Google it and find some articles which will help you and I have also written an entire book on hierarchies in SQL.
I think you've done everything wrong and you need to start over.
Please post DDL and follow ANSI/ISO standards when asking for help.
-
Hi jcelko212 32090
Thanks for the comments
- this is the data that is given to me, no control
- each loan has a key, just not showing it here for legibility, result is the same
- problem with the underlying system is that a user can set a link on loan-A to loan-B, but does not have to do it the other way
- it is also possible to link Loan-A AND Loan-B to Loan-C AND at the same time link Loan-C to Loan A
/M
-
SOLVED
this (unedited) sql gives the expected result
WITH CTE (id, parent) as
(
SELECT c.id, c.parent
from
(
SELECT DISTINCT(id), parent
FROM
(
select u.id, u.parent
FROM
(
SELECT a.id, a.Loan_ID
, COALESCE(b.id, a.id) AS id_b
, COALESCE(c.Loan_ID, a.id) AS loan_id_c
, d.Loan_ID AS loan_id_d
, e.Loan_ID AS loan_id_e
, f.id AS id_f
FROM #test a
LEFT OUTER JOIN #test b ON a.id = b.Loan_ID
LEFT OUTER JOIN #test c ON b.id = c.id
LEFT OUTER JOIN #test d ON a.id = d.id
LEFT OUTER JOIN #test e ON a.Loan_ID = e.id
LEFT OUTER JOIN #test f ON a.Loan_ID = f.Loan_ID
) a
unpivot
(
parent
for subject in ([Loan_ID], [id_b], [loan_id_c],loan_id_d, loan_id_e, id_f)
) u
) a
) c
)
SELECT DISTINCT ST2.id,
SUBSTRING(
(
SELECT ','+ST1.Parent AS [text()]
FROM cte ST1
WHERE ST1.id = ST2.id
ORDER BY ST1.id DESC
FOR XML PATH ('')
), 2, 1000) [Parent]
FROM cte ST2
ORDER BY parent, id

Viewing 8 posts - 1 through 8 (of 8 total)
You must be logged in to reply to this topic. Login to reply