Can we do the Group by with Like + % in the SQL Query?
-
I use SQL-2012 version.
I have an issue when writing the SQL statement. Need some help from here. Enclosed is the data sample. We have a lot of layers and this is just a part of it.

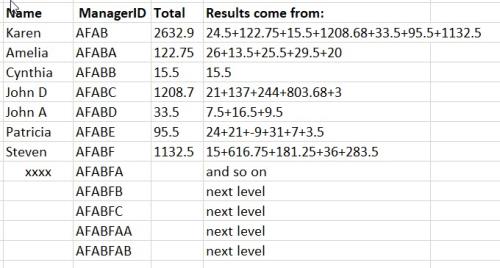
Need the SQL Statement that will sum by hierarchal groupings with ManagerID. For example,
Karen is on the top and her ID is AFAB. We need all numbers to be totaled, that start with AFAB%, in the EmployeeID column.
Then, we have Amelia, with the ID of AFABA. We need all total for AFABA% in the EmployeeID column. John D, with the ID of AFABC should have the total for everyone with the AFABC%.
Steven, ID of AFABF, has a few managers reporting to him. For example: Paul (AFABFD). Paul also supervises three more employees in his team. (I did not list them from the example, but their ID will start with AFABFDA, AFABFDB and AFABFDC, consecutively.)
The real data might contain more than seven (7) management layers.
If we need the total for Steven, we will sum up everyone with the EmployeeID starting with AFABF.
In this example, can you come up with a query that will sum up the allocations for management? I am thinking of using the group by like ManagerID +’%’. However, I am still struggling on this.
ManagerID at each level will be added one character to the right/
For example, AAAA reports to AAA; AAA reports to AA and AA reports to A (top layer).
I am not sure whether I need to union the query. I tried to experiment quite a bit of this and it did not work.
--------------------------
This is the result that we would like to see from the queryPlease reply if you need further information. Thank you.
-------------------
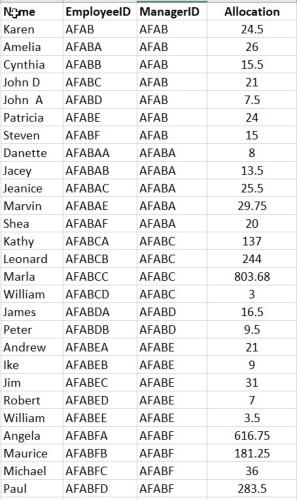
This is the raw data, if you want to test it:
Name,EmployeeID,ManagerID,Allocation
Karen ,AFAB,AFAB,24.5
Amelia ,AFABA,AFAB,26
Cynthia ,AFABB,AFAB,15.5
John D,AFABC,AFAB,21
John A,AFABD,AFAB,7.5
Patricia ,AFABE,AFAB,24
Steven ,AFABF,AFAB,15
Danette ,AFABAA,AFABA,8
Jacey ,AFABAB,AFABA,13.5
Jeanice ,AFABAC,AFABA,25.5
Marvin ,AFABAE,AFABA,29.75
Shea ,AFABAF,AFABA,20
Kathy ,AFABCA,AFABC,137
Leonard ,AFABCB,AFABC,244
Marla ,AFABCC,AFABC,803.68
William,AFABCD,AFABC,3
James,AFABDA,AFABD,16.5
Peter ,AFABDB,AFABD,9.5
Andrew,AFABEA,AFABE,21
Ike ,AFABEB,AFABE,9
Jim ,AFABEC,AFABE,31
Robert ,AFABED,AFABE,7
William ,AFABEE,AFABE,3.5
Angela ,AFABFA,AFABF,616.75
Maurice,AFABFB,AFABF,181.25
Michael ,AFABFC,AFABF,36
Paul ,AFABFD,AFABF,283.5 -
I have not tested this, but I'm thinking in this direction:
WITH ManagerSubList
AS (
SELECT e.Name AS SubName
,e.EmployeeID AS SubID
,m.Name AS ManagerName
,m.EmployeeID AS ManagerID
FROM dbo.Employees AS m
FULL JOIN dbo.Employees AS e
ON e.EmployeeID LIKE CONCAT(m.EmployeeID,'%')
)
SELECT ManagerID
,ManagerName
,COUNT(e.Name) AS teamSize
FROM ManagerSubList
GROUP BY ManagerID
,ManagerName;However, I'll add that I'd rather seen incrementing integers for the EmployeeIDs, and then the ManagerID is the EmployeeID of each person's manager
I'm thinking.. someday Michael might be promoted to be Cynthia's manager, and then LOTS of EmployeeIDs would have to change.. I'd rather have each person's EmployeeID be permanent. -
Thank you for your response, C.Lockhart. I will use your query to test the result.
I made a mistake on posting question. The group like should be ManagerID not EmployeeID. I do apologize on this. We need the total allocation by manager, not by employees.
Thanks.
-
The next thing they'll ask for is to....
- Calculate the total number of nodes in each person's downline including that person.
- Calculate the total number of nodes for each relative level in each person's downline including that person's level.
- Calculate the total amount of sales in each person's downline including that person's sales .
- Calculate the total amount of sales for each relative level in each person's downline including that person's level.
- Calculate the relative level number for each relative level in each person's downline including that person's level. Each person would have a relative level of 1.
- Calculate the total number of levels in each person's downline including that person.
- Calculate the totals at each level.
You have the perfect "Adjacency List" to pull this off and it can be done on a million hierarchical nodes in 54 seconds. Please see the following article for a deep understanding of how to do all of this in a fairly simple manner and still maintain the easy maintenance benefits of maintaining only the "Adjacency List".
http://www.sqlservercentral.com/articles/T-SQL/94570/--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 4 posts - 1 through 4 (of 4 total)
You must be logged in to reply to this topic. Login to reply