Can find the issue for join that does not work
-
I am trying to join these two tables using Left Join (POSTGRES, believe TSQL is the same principle).
Problem is, i'm not getting the 5 million in complete matched. Dimension table contain lookup/master data of about 40 columns. When i do a left join i can see the joined columns if i limit it to maybe 20 or 30, but when want to see * i get nulls for those columns.
-- Table: dim.IMETA_Source_Description_Mapping
-- DROP TABLE IF EXISTS dim."IMETA_Source_Description_Mapping";
CREATE TABLE IF NOT EXISTS dim."IMETA_Source_Description_Mapping"
(
"BRACS_Key" integer NOT NULL DEFAULT nextval('dim."IMETA_Source_Description_Mapping_BRACS_Key_seq"'::regclass),
"BRACSFA" character varying(255) COLLATE pg_catalog."default" NOT NULL,
"Function" character varying(255) COLLATE pg_catalog."default" NOT NULL,
CONSTRAINT "IMETA_Source_Description_Mapping_pkey" PRIMARY KEY ("BRACS_Key")
)
TABLESPACE pg_default;
ALTER TABLE IF EXISTS dim."IMETA_Source_Description_Mapping"
OWNER to AND
-- Table: system.IMETA_ZTRB_MP$F_ZTBR_TA_BW
-- DROP TABLE IF EXISTS system."IMETA_ZTRB_MP$F_ZTBR_TA_BW";
CREATE TABLE IF NOT EXISTS system."IMETA_ZTRB_MP$F_ZTBR_TA_BW"
(
"Company_Code" character varying(4) COLLATE pg_catalog."default",
"Posting_Period" character varying(7) COLLATE pg_catalog."default",
"Fiscal_Year" character varying(4) COLLATE pg_catalog."default",
"Profit_Center" character varying(255) COLLATE pg_catalog."default",
"Account_Number" character varying(255) COLLATE pg_catalog."default",
"Business_Process" character varying(255) COLLATE pg_catalog."default",
"Cost_Center" character varying(10) COLLATE pg_catalog."default",
"Internal_Order" character varying(255) COLLATE pg_catalog."default",
"Trading_Partner" character varying(255) COLLATE pg_catalog."default",
"Amount_in_company_code_currency" numeric(17,2),
"Company_code_currency" character varying(5) COLLATE pg_catalog."default",
"BRACS_FA" character varying(255) COLLATE pg_catalog."default",
"Expense_Type" character varying(255) COLLATE pg_catalog."default",
"BRACS_ACCT_Key" character varying(255) COLLATE pg_catalog."default",
"CC_Direct" character varying(255) COLLATE pg_catalog."default",
"Segment_PC" character varying(255) COLLATE pg_catalog."default",
"CC_Master_FA" character varying(255) COLLATE pg_catalog."default",
"RowInsertedTimestamp" date DEFAULT CURRENT_DATE,
"RowUpdatedTimestamp" timestamp without time zone DEFAULT CURRENT_TIMESTAMP,
"IMETA_ZTBR_BRACS_Primary_Key" integer NOT NULL DEFAULT nextval('system."IMETA_ZTBR_BRACS_Primary_Key_seq"'::regclass),
"Entity_Secondary_Key" integer DEFAULT nextval('system."Entity_Secondary_Key_seq"'::regclass),
CONSTRAINT "IMETA_ZTRB_MP$F_ZTBR_TA_BW_pkey" PRIMARY KEY ("IMETA_ZTBR_BRACS_Primary_Key"),
CONSTRAINT "Entity_Secondary_Key_unique" UNIQUE ("Entity_Secondary_Key")
)
TABLESPACE pg_default;
ALTER TABLE IF EXISTS system."IMETA_ZTRB_MP$F_ZTBR_TA_BW"
OWNER to -
You seem to have a lot of Postgres problems ... why not find a Postgres forum?
There is a button that says 'Code' in your icon bar. With >3,000 points, you must know about it. So why not use it? Your SQL code may as well be encrypted, presenting it like that.
-
and you have been advised before that if a join does not return the rows you expect you either
1 - don't have the correct data
2 - don't have the correct joins.
either way not much we can do without the full sql joining the tables, sample data and expected output - as well as the actual (wrong) output.
-
The issue is, all of these tables dont have primary/secondary keys, which i brought in with sl code.
Because these keys dont correspond to one another it gives me these errors. If Primary key start at 1, so must Secondary Key. What's the best way to do that?
- yrstruly wrote:
The issue is, all of these tables dont have primary/secondary keys, which i brought in with sl code.
Because these keys dont correspond to one another it gives me these errors. If Primary key start at 1, so must Secondary Key. What's the best way to do that?
I see zero errors, so please explain.
Best way to do what?
-
Not an error, but no data for joined columns.
-
You could make it easier for us by pasting in the query rather than the table DDL.
Are you saying that when you specify 30 columns in your SQL you see data but when you select * the same columns are showing as NULL?
-
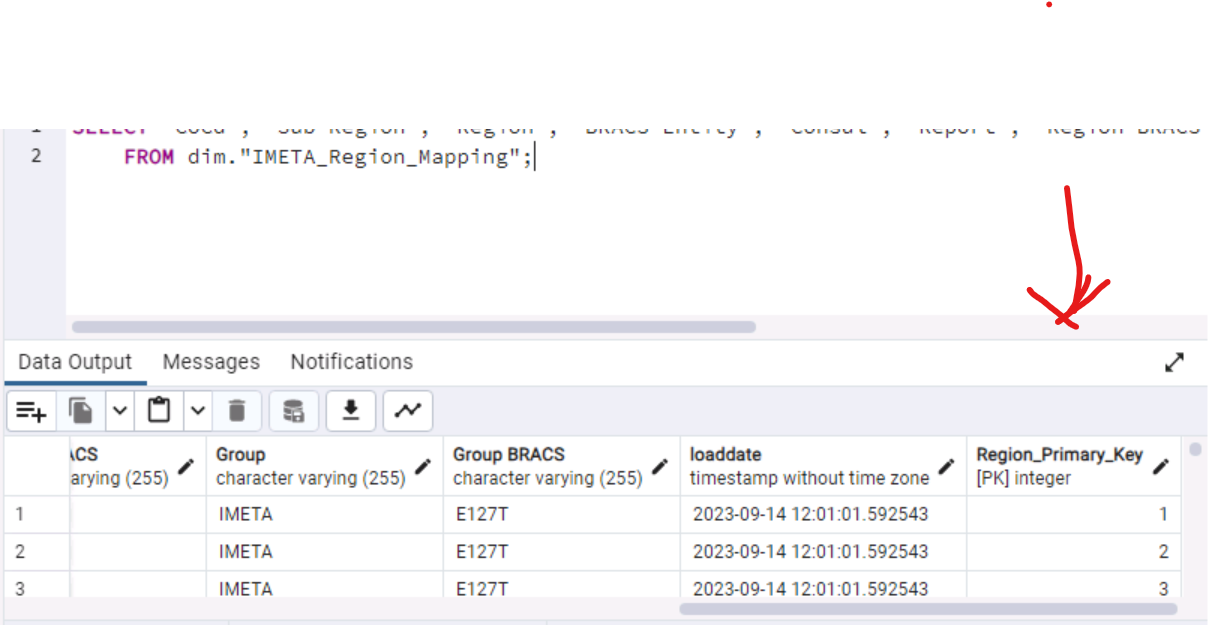
SELECT
S.*, -- Select all columns from the system.IMETA_ZTRB_MP$F_ZTBR_TA_BW table
D."CoCd" AS "Dim_CoCd", -- Alias the CoCd from dim table
D."Region" AS "Dim_Region", -- Alias the Region column from dim table
D."Sub Region" AS "Dim_Sub_Region", -- Alias the Sub Region column from dim table
D."Region_Primary_Key" AS "Dim_Region_Primary_Key" -- Alias the Region_Primary_Key column from dim table
FROM
system."IMETA_ZTRB_MP$F_ZTBR_TA_BW" AS S
LEFT JOIN
dim."IMETA_Region_Mapping" AS D
ON
S."Entity_Secondary_Key" = D."Region_Primary_Key";I believe it is because the values in Primary and Secondary Key don't correspond:
-
Presumably, your question is not this:
"Why are no results returned when I join on two columns containing values which do not match?"
What is your real question?
-
You are doing a left join so you must be expecting to find rows that do not have a match in dim."IMETA_Region_Mapping", otherwise you would be using an inner join.
-- Rows that do not have matching data in "IMETA_Region_Mapping"
SELECT *
FROM system."IMETA_ZTRB_MP$F_ZTBR_TA_BW" AS S
WHERE NOT EXISTS(SELECT *
FROM dim."IMETA_Region_Mapping" AS D
WHERE S."Entity_Secondary_Key" = D."Region_Primary_Key")
;
-- Rows that have matching data in "IMETA_Region_Mapping"
SELECT *
FROM system."IMETA_ZTRB_MP$F_ZTBR_TA_BW" AS S
WHERE EXISTS(SELECT *
FROM dim."IMETA_Region_Mapping" AS D
WHERE S."Entity_Secondary_Key" = D."Region_Primary_Key")
; -
Thank you for trying to assist. I did a left join and the data appeared, I filtered it out with NOT NULL, and then it gave me all the rows where no null exists.
As I said before, I brought in the Primary/Secondary/Foreign keys because it does not exist in the Fact/Dimension tables.
The Fact tables contain 6 million records and the dimension tables are tiny. Because some columns don't exist in the Fact and Dimension table I can not update the Foreign Keys in the Fact table to ensure relationship integrity.
e.g Say I have a Fact table containing Apple's Sales; one of the Dimension tables is Apple Type. Since the two tables don't contain an Apple Type column in both I won't be able to enforce referention integrity. If my Apple Sales table contains 6 million + sales, I won't be able to break it down Apple sales by Type.
That is the problem I am sitting with. My fact Table is not able to give me unique Foreign Key columns. I read about a Mapping table.
I would like to join IMETA_ZTRB_MP$F with Dimensions. I have brought in these mapping tables as dimensions(see code and tables attached). I created Primary and Foreign/Secondary keys to join these tables. Currently, I don’t have a unique column within the SAP table and Dimension tables. To be sure that the data align I needed column(s) like that.
a process in achieving this?
I have brought in table key constraints, but because matching columns are missing I am not getting unique foreign keys for these. An example is using this code to update the foreign key values in the Fact/SAP table
” UPDATE system."IMETA_ZTRB_MP$F_ZTBR_TA_BW" AS A
SET "Master_BRACS_Secondary_Key" = B."Primary_ZTBR_TransactionCode"
FROM dim."IMETA_Master_BRACS_to_SAP_Data_TA_BR_" AS B
WHERE A."ZTBR_TransactionCode" = B."Primary_ZTBR_TransactionCode";”
It is supposed to take primary key values from:

And insert it into
:
The problem is those values in the Foreign/Secondary keys are not unique.
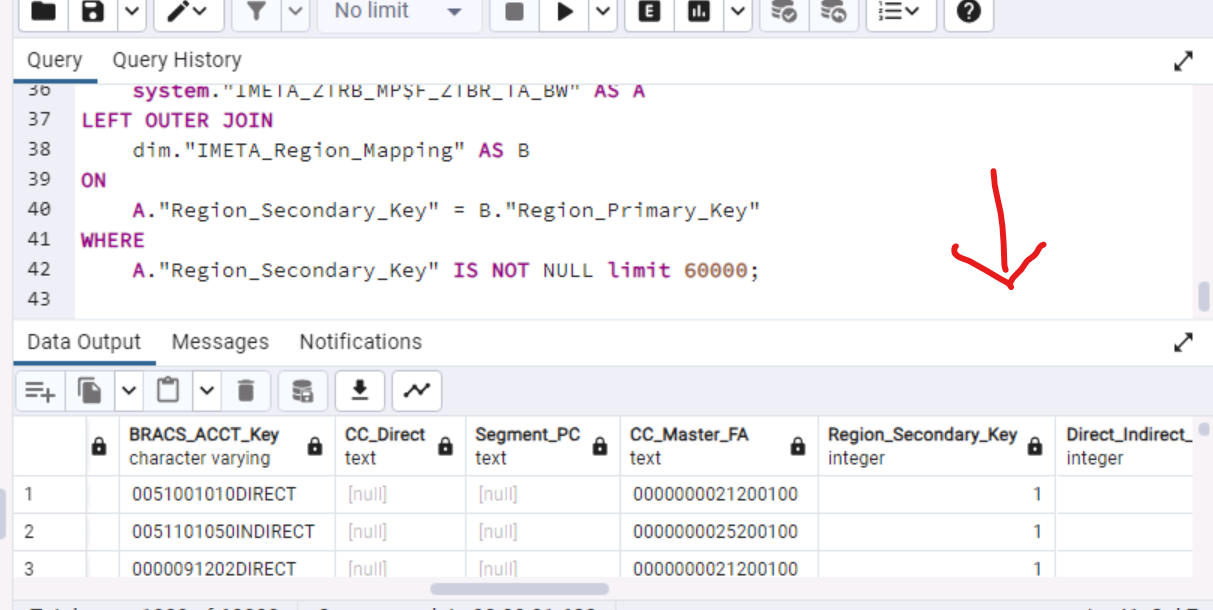
Here is the SQL:
-- Table: system.IMETA_ZTRB_MP$F_ZTBR_TA_BW
-- DROP TABLE IF EXISTS system."IMETA_ZTRB_MP$F_ZTBR_TA_BW";
CREATE TABLE IF NOT EXISTS system."IMETA_ZTRB_MP$F_ZTBR_TA_BW"
(
"ZTBR_TransactionCode" integer NOT NULL DEFAULT nextval('system."IMETA_ZTBR_TransactionCode_Seq"'::regclass),
"Company_Code" character varying COLLATE pg_catalog."default",
"Posting_Period" integer,
"Fiscal_Year" integer,
"Profit_Center" text COLLATE pg_catalog."default",
"Account_Number" integer,
"Business_Process" character varying COLLATE pg_catalog."default",
"Internal_Order" integer,
"Trading_Partner" text COLLATE pg_catalog."default",
"Amount_in_Company_Code_Currency" numeric,
"Company_Code_Currency" text COLLATE pg_catalog."default",
"BRACS_FA" character varying COLLATE pg_catalog."default",
"Expense_Type" text COLLATE pg_catalog."default",
"BRACS_ACCT_Key" character varying COLLATE pg_catalog."default",
"CC_Direct" text COLLATE pg_catalog."default",
"Segment_PC" integer,
"CC_Master_FA" text COLLATE pg_catalog."default",
"Region_Secondary_Key" integer,
"Direct_Indirect_Secondary_Key" integer,
"Source_Description_Secondary_Key" integer,
"Entity_Secondary_Key" integer,
"Master_BRACS_Secondary_Key" integer,
"Loaddate" date,
CONSTRAINT "IMETA_ZTRB_MP$F_ZTBR_TA_BW_pkey" PRIMARY KEY ("ZTBR_TransactionCode"),
CONSTRAINT "IMETA_ZTBR_TransactionCode_unique" UNIQUE ("ZTBR_TransactionCode"),
CONSTRAINT "IMETA_ZTRB_MP$F_ZTBR_TA_BW_Master_BRACS_Secondary_Key_fkey" FOREIGN KEY ("Master_BRACS_Secondary_Key")
REFERENCES dim."IMETA_Master_BRACS_to_SAP_Data_TA_BR_" ("Primary_ZTBR_TransactionCode") MATCH SIMPLE
ON UPDATE CASCADE
ON DELETE NO ACTION,
CONSTRAINT fk_entity FOREIGN KEY ("Entity_Secondary_Key")
REFERENCES dim."IMETA_Entity_Mapping" ("Entity_ID") MATCH SIMPLE
ON UPDATE NO ACTION
ON DELETE NO ACTION
)
TABLESPACE pg_default;
ALTER TABLE IF EXISTS system."IMETA_ZTRB_MP$F_ZTBR_TA_BW"
OWNER to apollia;
---
-- Table: dim.IMETA_Master_BRACS_to_SAP_Data_TA_BR_
-- DROP TABLE IF EXISTS dim."IMETA_Master_BRACS_to_SAP_Data_TA_BR_";
CREATE TABLE IF NOT EXISTS dim."IMETA_Master_BRACS_to_SAP_Data_TA_BR_"
(
"Primary_ZTBR_TransactionCode" integer NOT NULL,
"Level 1" character varying(255) COLLATE pg_catalog."default",
"Level 2" character varying(255) COLLATE pg_catalog."default",
"Level 3" character varying(255) COLLATE pg_catalog."default",
"Acct Type" character varying(255) COLLATE pg_catalog."default",
"Account Desc" character varying(255) COLLATE pg_catalog."default",
"EXPENSE FLAG" character varying(255) COLLATE pg_catalog."default",
"BRACS" character varying(255) COLLATE pg_catalog."default",
"BRACS_DESC"" " character varying(50) COLLATE pg_catalog."default",
"BRACS_DESC" character varying(255) COLLATE pg_catalog."default",
"Loaddate" date,
CONSTRAINT "Primary Key" PRIMARY KEY ("Primary_ZTBR_TransactionCode")
)
TABLESPACE pg_default;
ALTER TABLE IF EXISTS dim."IMETA_Master_BRACS_to_SAP_Data_TA_BR_"
OWNER to apollia;
ZTBR n IMETA_Master_BRACS_to_SAP_Data_TA_BR_.txt
Displaying ZTBR n IMETA_Master_BRACS_to_SAP_Data_TA_BR_.txt. -
If you follow the Kimball methodology for dimension tables you will include rows with keys with negative values in the dimension table, then you have values in the FK columns of the fact table that will always point to a row on the dimension table. You should also make all the FK keys in the fact table not null.
For example:
-1: Not Applicable or Unknown: Often, -1 is used to represent situations where there is no applicable or known value for a particular dimension. For example, in a customer dimension table, -1 might represent an unknown or not applicable gender or marital status.
-2: Missing or Undefined: -2 is typically used to signify missing or undefined values. It can indicate that data for a particular dimension attribute is not available or has not been provided.
-3: Reserved for Other Special Values: The meaning of -3 can vary widely and is often reserved for other special values that don't fit the -1 or -2 categories. This key might be used for specific business scenarios or exceptional cases that require unique handling.
These negative keys are a way to handle exceptional or missing data gracefully in a data warehouse. They ensure that even when data is incomplete or certain values are not applicable, there is still a valid representation in the dimension table. Data analysts and reporting tools can then use these keys to filter, categorize, or aggregate data as needed.
So you should never need to use a left join when joining fact tables to dimension tables.
-
Does Jonathan's (excellent) response solve your problem?
-
This is what i have to work with.
-
Well is says in the spec you should do a UNION of selects.
So I would think you can just have several select statements with inner joins and UNION ALL them together. You might need to include some NOT EXISTS to ensure that the data doesn't exist in one of the previous selects. If you provide the queries you have so far maybe we can sort them out. It's very difficult to read the pictures and would involve us doing a lot of typing from scratch to give you an answer so can you provide what you have in text form.
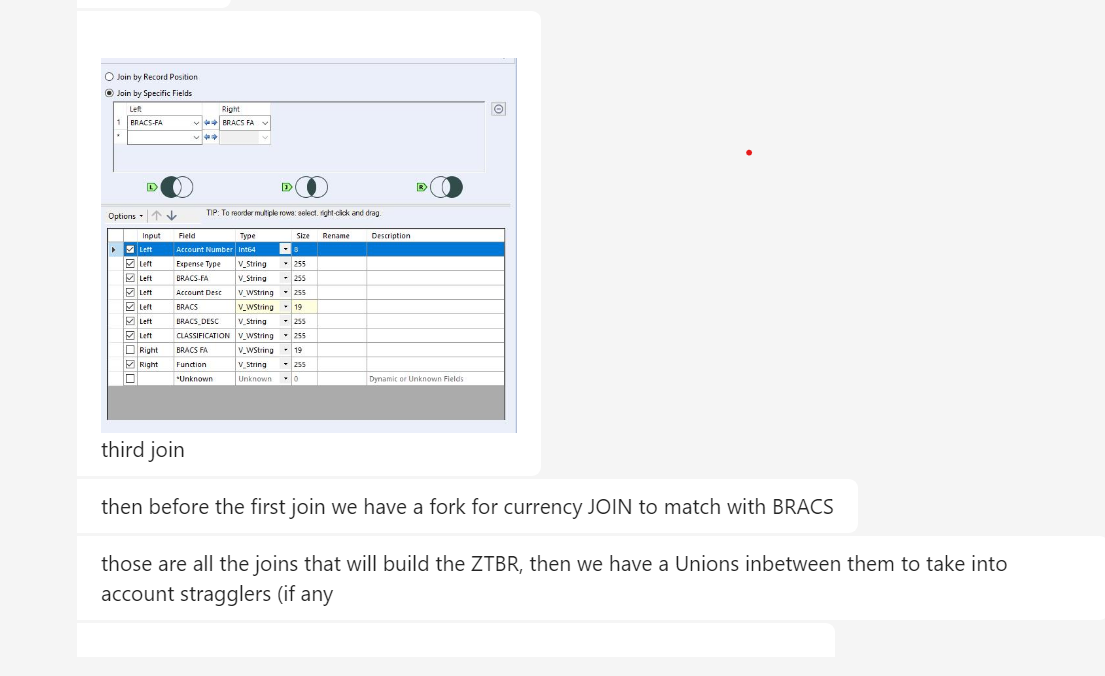
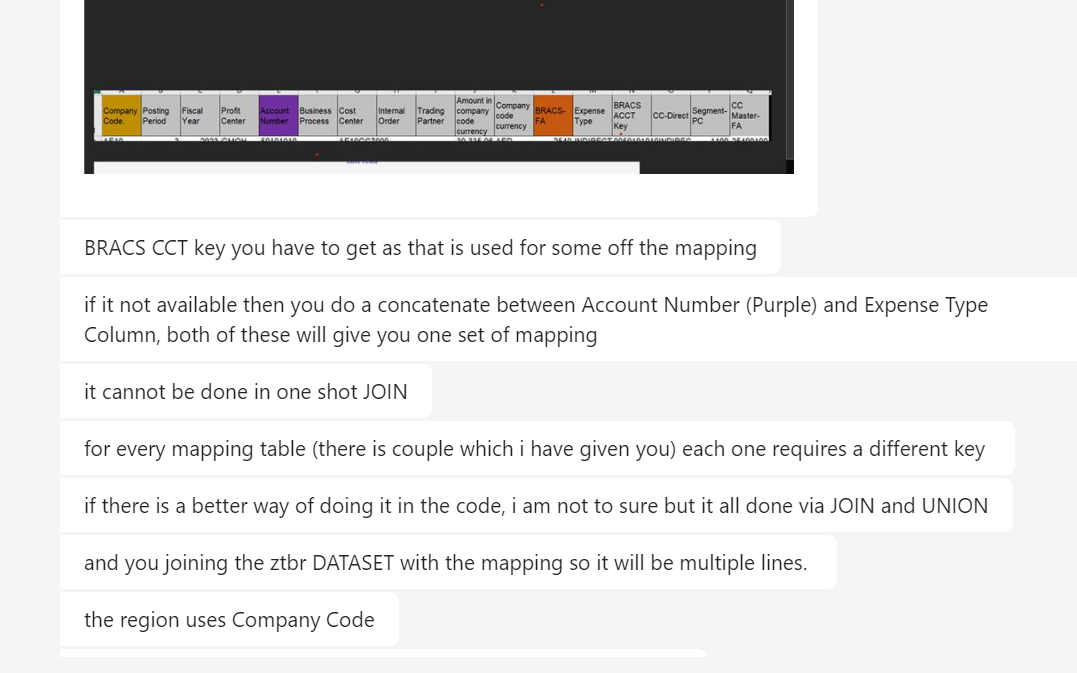
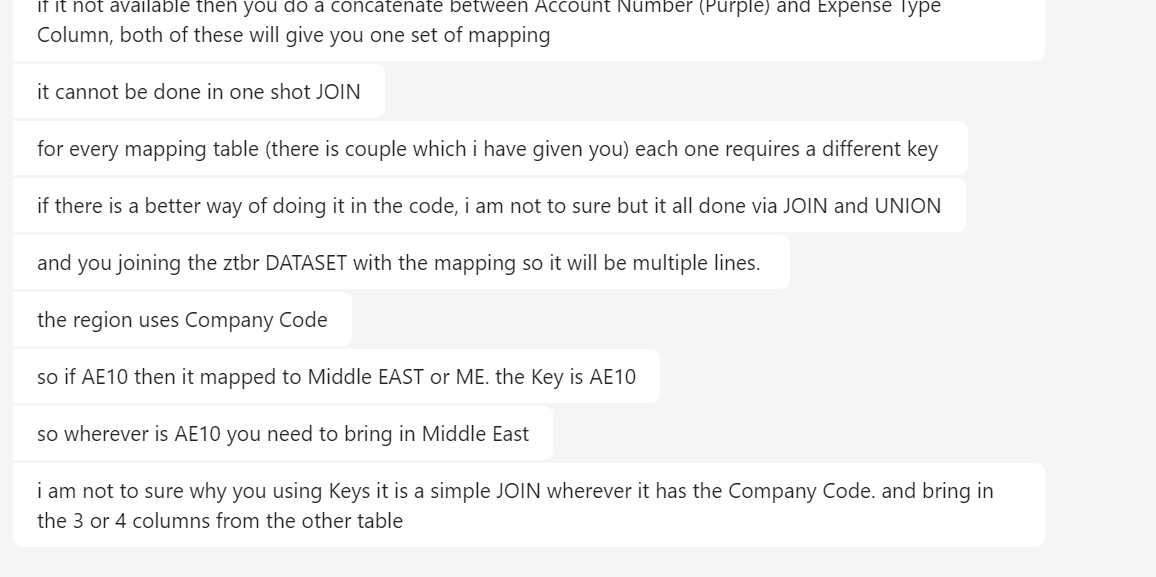
Viewing 15 posts - 1 through 15 (of 28 total)
You must be logged in to reply to this topic. Login to reply