Calculating Prime Numbers With One Query
-
These are great comparisons. The so-far winning code was jointly arrived at. Interesting in a straight comparison GENERATE_SERIES appears faster than fnTally
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
- Steve Collins wrote:
These are great comparisons. The so-far winning code was jointly arrived at. Interesting in a straight comparison GENERATE_SERIES appears faster than fnTally
According to some testing that I saw (IIRC) in one of Erik Darling's posts, it was a bit of a dog during the first public release and they've done a good job in "getting it up to speed". It should be faster... it operates closer to the machine language level. I'm pretty happy with it except when being used as a row source to create large test tables... It has the nasty habit of breaking "Minimal Logging".
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
That's the article which had shaped my low expectations. Good to know it's been improved. It's also interesting Jonathan used GENERATE_SERIES in place of the non-itvf method of TOP and CROSS JOINs. Is GENERATE_SERIES better than no itvf?
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
- Steve Collins wrote:
That's the article which had shaped my low expectations. Good to know it's been improved. It's also interesting Jonathan used GENERATE_SERIES in place of the non-itvf method of TOP and CROSS JOINs. Is GENERATE_SERIES better than no itvf?
As with most other ideas or claims of performance, there's only one way to find out. 😉
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:Steve Collins wrote:
That's the article which had shaped my low expectations. Good to know it's been improved. It's also interesting Jonathan used GENERATE_SERIES in place of the non-itvf method of TOP and CROSS JOINs. Is GENERATE_SERIES better than no itvf?
As with most other ideas or claims of performance, there's only one way to find out. 😉
From my testing SQL Server's GENERATE_SERIES is efficient and well-optimized. It's not surprising it performers better than user defined functions as it is implemented in the native code of the DBMS. This will be is compiled and optimized for performance, taking advantage of low-level optimizations and hardware-specific features, which can result in faster execution compared to user-defined functions that may be implemented in a higher-level language like SQL or procedural languages.
Shifting gears, there's a slight enhancement to Steve's algorithm that reduces the execution time from 2 seconds to 1.8 seconds. This improvement involves testing whether the prime candidate is 3 or if it leaves a remainder of 1 or 5 when divided by 6.
DROP TABLE IF EXISTS #SCollinsGENERATE_SERIES;
GO
DECLARE @Max int = 1000000;
SET STATISTICS TIME ON;
SELECT value
INTO #SCollinsGENERATE_SERIES
FROM (values (2),(3)) t(value)
WHERE t.value <= @Max
UNION all
SELECT value
FROM GENERATE_SERIES(3, @Max, 2) p
WHERE NOT EXISTS(SELECT 1
FROM GENERATE_SERIES(3, CAST(SQRT(p.value) AS int), 2) f
WHERE p.value%f.value=0)
AND p.value%6 IN(1, 5)
;
SET STATISTICS TIME OFF; - Jonathan AC Roberts wrote:
From my testing SQL Server's GENERATE_SERIES is efficient and well-optimized. It's not surprising it performers better than user defined functions as it is implemented in the native code of the DBMS. This will be is compiled and optimized for performance, taking advantage of low-level optimizations and hardware-specific features, which can result in faster execution compared to user-defined functions that may be implemented in a higher-level language like SQL or procedural languages.
I did a lot of testing, as well. The reason is because I've found that Microsoft frequently can't hit the floor with a hat. 😉 A grand example of that is the FORMAT function. And, the way the test results from other people's test were shaping up in the early days, I didn't have much hope.
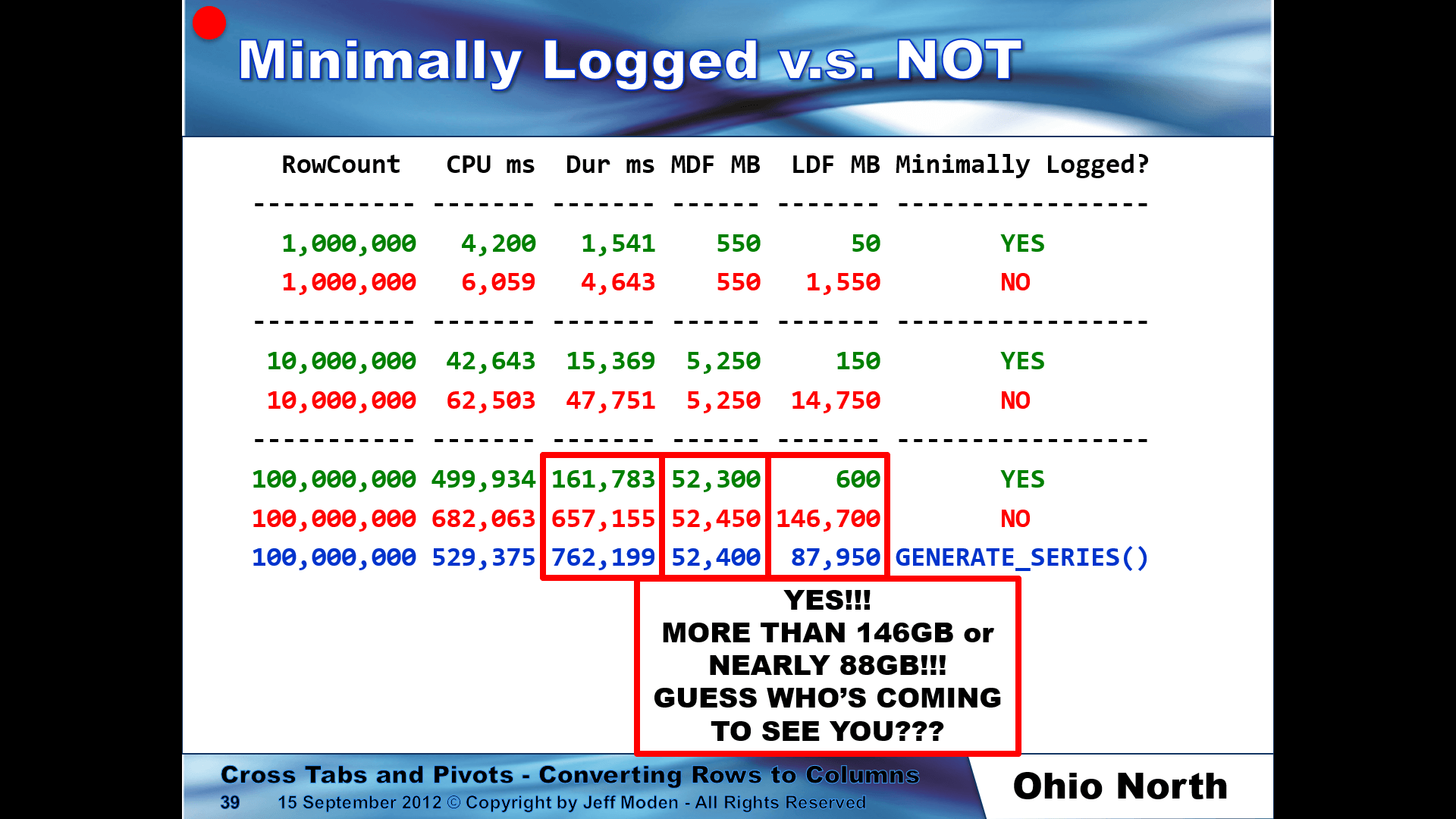
Still, when used as a rowsource for something like creating test data in a minimally logged fashion, it's a major failure because it will not be minimally logged. My test was to do such a thing using my version of fnTally. Only replacing fnTally with the equivalent call to GENERATE_SERIES(), well... here are the results from a presentation I recently gave... I didn't do GENERATE_SERIES() for the lesser tests... just the big one.

Here's the code from the presentation (and I'm hating the damned double spacing this forum does more and more)...
/**********************************************************************************************************************
Purpose:
This script unconditionally drops the dbo.BigTable if it exists and then creates/recreates it.
This script includes a Clustered Index. Please change it to suit your needs.
-----------------------------------------------------------------------------------------------------------------------
Run Stats (On my laptop. Times will vary from machine to machine.):
RowCount CPU ms Dur ms MDF MB LDF MB Minimally Logged?
----------- ------- ------- ------ ------- -----------------
1,000,000 4,200 1,541 550 50 YES
1,000,000 6,059 4,643 550 1,550 NO
----------- ------- ------- ------ ------- -----------------
10,000,000 42,643 15,369 5,250 150 YES
10,000,000 62,503 47,751 5,250 14,750 NO
----------- ------- ------- ------ ------- -----------------
100,000,000 499,934 161,783 52,300 600 YES
100,000,000 682,063 657,155 52,450 146,700 NO
-----------------------------------------------------------------------------------------------------------------------
RowCount CPU ms Dur ms MDF MB LDF MB Minimally Logged?
----------- ------- ------- ------ ------- -----------------
100,000,000 529,375 762,199 52,400 87,950 NO Used GENERATE_SERIES(). Don't use for this.
-----------------------------------------------------------------------------------------------------------------------
Revision History:
Rev 00 - 19 Jul 2008 - Jeff Moden
- Initial creation and unit test.
Rev 01 - 08 Apr 2023 - Jeff Moden
- Move the table creation/population code to this script.
- Add the display of file sizes.
**********************************************************************************************************************/--===== Do this in the correct database
USE CrossTab
;
--===== Create the test table.
DROP VIEW IF EXISTS dbo.BigTableByDayProductID;
DROP TABLE IF EXISTS dbo.BigTable;
--===== Identify the section to the operator.
RAISERROR('Display the starting file sizes...',0,0) WITH NOWAIT --Commented out for performance testing
;
CHECKPOINT;
SELECT StartMdfSizeMB = SUM(CASE WHEN type_desc = 'ROWS' THEN size/128 ELSE 0 END)
,StartLdfSizeMB = SUM(CASE WHEN type_desc = 'LOG' THEN size/128 ELSE 0 END)
FROM sys.database_files
;
GO
--=====================================================================================================================
-- Populate the test table with "Minimal Logging".
--=====================================================================================================================
--===== Identify the section to the operator.
RAISERROR('Creating the BigTable using "Minimal Logging"...',0,0) WITH NOWAIT
;
--===== Create the test table.
--(Slide 34)
CREATE TABLE dbo.BigTable
(
RowNum INT IDENTITY(1,1), --Not necessary but simulating what people do.
ProductID CHAR(3) NOT NULL --AAA thru BBB (8 different values)
,Amount DECIMAL(9,2) NOT NULL --0.00 to 100.00
,Quantity SMALLINT NOT NULL --1 to 50 non-unique numbers
,TransDT DATETIME NOT NULL --Dates/Times year >= 2010 & < 2020 (10 years)
,OtherCols CHAR(500) NOT NULL DEFAULT 'X' --Simulates "bulk" in the table.
)
;
--===== Add a temporally based Clustered Index to support reporting.
CREATE CLUSTERED INDEX CI_ByTransDTProductID
ON dbo.BigTable (TransDT,ProductID)
;
--=====================================================================================================================
-- Populate the test table with "Minimal Logging".
--=====================================================================================================================
--===== Populate the test table using "Minimal Logging".
SET STATISTICS TIME,IO ON --Not required for "Minimal Logging". We're just measuring things here.
;
--(Slide 36)
--===== Variables to control dates and number of rows in the test table.
DECLARE @StartDT DATETIME = '2010' --Resolves to 2010-01-01 (Inclusive)
,@EndDT DATETIME = '2020' --Resolves to 2020-01-01 (Exclusive)
,@Rows INT = 10000000; --TODO: Change this number to suit your test requirements
DECLARE @Days INT = DATEDIFF(dd,@StartDT,@EndDT)
;
--===== Populate the test table using "Minimal Logging".
INSERT INTO dbo.BigTable WITH (TABLOCK) -- TABLOCK required for minimal loggimg
(ProductID, Amount, Quantity, TransDT)
SELECT ProductID = CHAR(ABS(CHECKSUM(NEWID())%2)+65) --ASCII 65 is "A",ASCII 66 is "B"
+ CHAR(ABS(CHECKSUM(NEWID())%2)+65)
+ CHAR(ABS(CHECKSUM(NEWID())%2)+65)
,Amount = RAND(CHECKSUM(NEWID()))*100
,Quantity = ABS(CHECKSUM(NEWID())%50)+1
,TransDT = RAND(CHECKSUM(NEWID()))*@Days+@StartDT
--FROM GENERATE_SERIES(1,@Rows) -- DO NOT USE!!! Took 00:12:42 :( and Logfile exploded to 87.950 GB :(
FROM dbo.fnTally(1,@Rows) -- Function included in the ZIP file.
ORDER BY TransDT,ProductID -- Inserts must be in same order as Clustered Index.
OPTION (RECOMPILE) --Undocumented but essential for minimal logging when variables are used.
;
SET STATISTICS TIME,IO OFF --Not required for "Minimal Logging". We're just disabling meauring here.
;
GO
--=====================================================================================================================
-- Display the file sizes.
--=====================================================================================================================
--===== Identify the section to the operator.
RAISERROR('Display the final file sizes...',0,0) WITH NOWAIT --Commented out for performance testing
;
CHECKPOINT;
SELECT FinalMdfSizeMB = SUM(CASE WHEN type_desc = 'ROWS' THEN size/128 ELSE 0 END)
,FinalLdfSizeMB = SUM(CASE WHEN type_desc = 'LOG' THEN size/128 ELSE 0 END)
FROM sys.database_files
;
--===== Identify the end of run to the operator.
RAISERROR('RUN COMPLETE. Check the "Messages" tab for run stats...',0,0) WITH NOWAIT
;
GO--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:Jonathan AC Roberts wrote:
From my testing SQL Server's GENERATE_SERIES is efficient and well-optimized. It's not surprising it performers better than user defined functions as it is implemented in the native code of the DBMS. This will be is compiled and optimized for performance, taking advantage of low-level optimizations and hardware-specific features, which can result in faster execution compared to user-defined functions that may be implemented in a higher-level language like SQL or procedural languages.
I did a lot of testing, as well. The reason is because I've found that Microsoft frequently can't hit the floor with a hat. 😉 A grand example of that is the FORMAT function. And, the way the test results from other people's test were shaping up in the early days, I didn't have much hope.
Still, when used as a rowsource for something like creating test data in a minimally logged fashion, it's a major failure because it will not be minimally logged. My test was to do such a thing using my version of fnTally. Only replacing fnTally with the equivalent call to GENERATE_SERIES(), well... here are the results from a presentation I recently gave... I didn't do GENERATE_SERIES() for the lesser tests... just the big one.
Here's the code from the presentation (and I'm hating the damned double spacing this forum does more and more)...
/**********************************************************************************************************************
Purpose:
This script unconditionally drops the dbo.BigTable if it exists and then creates/recreates it.
This script includes a Clustered Index. Please change it to suit your needs.
-----------------------------------------------------------------------------------------------------------------------
Run Stats (On my laptop. Times will vary from machine to machine.):
RowCount CPU ms Dur ms MDF MB LDF MB Minimally Logged?
----------- ------- ------- ------ ------- -----------------
1,000,000 4,200 1,541 550 50 YES
1,000,000 6,059 4,643 550 1,550 NO
----------- ------- ------- ------ ------- -----------------
10,000,000 42,643 15,369 5,250 150 YES
10,000,000 62,503 47,751 5,250 14,750 NO
----------- ------- ------- ------ ------- -----------------
100,000,000 499,934 161,783 52,300 600 YES
100,000,000 682,063 657,155 52,450 146,700 NO
-----------------------------------------------------------------------------------------------------------------------
RowCount CPU ms Dur ms MDF MB LDF MB Minimally Logged?
----------- ------- ------- ------ ------- -----------------
100,000,000 529,375 762,199 52,400 87,950 NO Used GENERATE_SERIES(). Don't use for this.
-----------------------------------------------------------------------------------------------------------------------
Revision History:
Rev 00 - 19 Jul 2008 - Jeff Moden
- Initial creation and unit test.
Rev 01 - 08 Apr 2023 - Jeff Moden
- Move the table creation/population code to this script.
- Add the display of file sizes.
**********************************************************************************************************************/--===== Do this in the correct database
USE CrossTab
;
--===== Create the test table.
DROP VIEW IF EXISTS dbo.BigTableByDayProductID;
DROP TABLE IF EXISTS dbo.BigTable;
--===== Identify the section to the operator.
RAISERROR('Display the starting file sizes...',0,0) WITH NOWAIT --Commented out for performance testing
;
CHECKPOINT;
SELECT StartMdfSizeMB = SUM(CASE WHEN type_desc = 'ROWS' THEN size/128 ELSE 0 END)
,StartLdfSizeMB = SUM(CASE WHEN type_desc = 'LOG' THEN size/128 ELSE 0 END)
FROM sys.database_files
;
GO
--=====================================================================================================================
-- Populate the test table with "Minimal Logging".
--=====================================================================================================================
--===== Identify the section to the operator.
RAISERROR('Creating the BigTable using "Minimal Logging"...',0,0) WITH NOWAIT
;
--===== Create the test table.
--(Slide 34)
CREATE TABLE dbo.BigTable
(
RowNum INT IDENTITY(1,1), --Not necessary but simulating what people do.
ProductID CHAR(3) NOT NULL --AAA thru BBB (8 different values)
,Amount DECIMAL(9,2) NOT NULL --0.00 to 100.00
,Quantity SMALLINT NOT NULL --1 to 50 non-unique numbers
,TransDT DATETIME NOT NULL --Dates/Times year >= 2010 & < 2020 (10 years)
,OtherCols CHAR(500) NOT NULL DEFAULT 'X' --Simulates "bulk" in the table.
)
;
--===== Add a temporally based Clustered Index to support reporting.
CREATE CLUSTERED INDEX CI_ByTransDTProductID
ON dbo.BigTable (TransDT,ProductID)
;
--=====================================================================================================================
-- Populate the test table with "Minimal Logging".
--=====================================================================================================================
--===== Populate the test table using "Minimal Logging".
SET STATISTICS TIME,IO ON --Not required for "Minimal Logging". We're just measuring things here.
;
--(Slide 36)
--===== Variables to control dates and number of rows in the test table.
DECLARE @StartDT DATETIME = '2010' --Resolves to 2010-01-01 (Inclusive)
,@EndDT DATETIME = '2020' --Resolves to 2020-01-01 (Exclusive)
,@Rows INT = 10000000; --TODO: Change this number to suit your test requirements
DECLARE @Days INT = DATEDIFF(dd,@StartDT,@EndDT)
;
--===== Populate the test table using "Minimal Logging".
INSERT INTO dbo.BigTable WITH (TABLOCK) -- TABLOCK required for minimal loggimg
(ProductID, Amount, Quantity, TransDT)
SELECT ProductID = CHAR(ABS(CHECKSUM(NEWID())%2)+65) --ASCII 65 is "A",ASCII 66 is "B"
+ CHAR(ABS(CHECKSUM(NEWID())%2)+65)
+ CHAR(ABS(CHECKSUM(NEWID())%2)+65)
,Amount = RAND(CHECKSUM(NEWID()))*100
,Quantity = ABS(CHECKSUM(NEWID())%50)+1
,TransDT = RAND(CHECKSUM(NEWID()))*@Days+@StartDT
--FROM GENERATE_SERIES(1,@Rows) -- DO NOT USE!!! Took 00:12:42 :( and Logfile exploded to 87.950 GB :(
FROM dbo.fnTally(1,@Rows) -- Function included in the ZIP file.
ORDER BY TransDT,ProductID -- Inserts must be in same order as Clustered Index.
OPTION (RECOMPILE) --Undocumented but essential for minimal logging when variables are used.
;
SET STATISTICS TIME,IO OFF --Not required for "Minimal Logging". We're just disabling meauring here.
;
GO
--=====================================================================================================================
-- Display the file sizes.
--=====================================================================================================================
--===== Identify the section to the operator.
RAISERROR('Display the final file sizes...',0,0) WITH NOWAIT --Commented out for performance testing
;
CHECKPOINT;
SELECT FinalMdfSizeMB = SUM(CASE WHEN type_desc = 'ROWS' THEN size/128 ELSE 0 END)
,FinalLdfSizeMB = SUM(CASE WHEN type_desc = 'LOG' THEN size/128 ELSE 0 END)
FROM sys.database_files
;
--===== Identify the end of run to the operator.
RAISERROR('RUN COMPLETE. Check the "Messages" tab for run stats...',0,0) WITH NOWAIT
;
GOI tried your script with 10 million rows and it took 25 seconds with dbo.fnTally using 126 MB log file. With GENERATE_SERIES it took it took 126 seconds using 8,800 MB log file. It seems odd that it should stop minimal logging. I wonder if Microsoft will try to fix it.
- Jonathan AC Roberts wrote:
I tried your script with 10 million rows and it took 25 seconds with dbo.fnTally using 126 MB log file. With GENERATE_SERIES it took it took 126 seconds using 8,800 MB log file. It seems odd that it should stop minimal logging. I wonder if Microsoft will try to fix it.
You're talking about the company that couldn't understand why anyone would even need such a thing way back when Erland Sommarskog opened his original "ticket" on the old CONNECT site. You're also talking about the company that just couldn't understand why anyone would need to know the ordinal of each element in a text splitter function and the company that took decades to figure out that someone might actually want to import CSV files. They still haven't figured out why someone might want to do a BULK EXPORT using T-SQL instead of (ugh!) SSIS nor do they understand that importing from and exporting to things like Excel might be important. AND, you're talking about the company that doesn't understand why anyone would want to calculate durations between start and end dates/times and built a DATEDIFF_BIG to try to make up for that but neglected to create a DATEADD_BIG.
You're also talking about the company that came out with the FORMAT function years ago yet doesn't seem to have their ear to the rail to understand what a performance pig it is.
I am glad that they finally came out with DATETRUNC() to make up for the mistake they made with the rounding that occurs if you change the scale of things like TIME() and DATETIME2(). To the best of my knowledge, though, they still haven't been able to fix DATEDIFF(WW), though.
We won't even start to talk about the 2 absolute travesties known as ALTER INDEX REBUILD and ALTER INDEX REORGANIZE nor the ability to create/work with scratch/staging tables that do absolutely no logging even in a separate database nor the long standing problem of doing a full table sort in TEMPDB instead of minimal logging when SET IDENTITY INSERT is ON . 🙁 🙁 🙁
They also haven't figured out why anyone might want to generate a series of Date/Time slots like that really good iTVF you wrote nor why anyone in their right mind might need to restore just a single table or shrink a database file in a timely manner nor why one of the worst moves they ever made was to default LOBs to "in-Row".
So, my answer to your question is, "Probably NOT". 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jonathan AC Roberts wrote:
Shifting gears, there's a slight enhancement to Steve's algorithm that reduces the execution time from 2 seconds to 1.8 seconds. This improvement involves testing whether the prime candidate is 3 or if it leaves a remainder of 1 or 5 when divided by 6.
DROP TABLE IF EXISTS #SCollinsGENERATE_SERIES;
DECLARE @Max int = 1000000;
SELECT 2 value
INTO #SCollinsGENERATE_SERIES
WHERE 2 <= @Max
UNION all
SELECT value
FROM GENERATE_SERIES(3, @Max, 2) p
WHERE NOT EXISTS(SELECT 1
FROM GENERATE_SERIES(3, CAST(SQRT(p.value) AS int), 2) f
WHERE p.value%f.value=0)
AND (p.value%6 IN(1, 5)
OR p.value=3)
;Hmmm imo the issue of mathematical appropriateness of n = 6q + r is debatable. I found this link which describes it a little. Without complete analysis it seems to be not a sufficiently conclusive proof. Is it appropriate? Idk I'm inclined to deny. But for this topic it's interesting I guess
The WHERE clause above the UNION ALL is quite unnecessary. Have you been chatting with an LLM?
On my computer adding additional criteria which notionally reduce the number of comparisons seems to not have a predictable effect on runtimes. When the max int of the search is 1,000,000 the results with/without are within the variance range (based on visual inspection and I'm still using fnTally because no SQL 2022 yet). I have to admit by this conversation and others I'm getting more motivated to upgrade. Why is it not automatically faster? SQL is an interpreted language. We have no visibility into how the DB Engine exits looping due to WHERE clause conditions afaik.
What about 5's? Any number ending in 5 above 5 cannot be prime. That seems like it should be a gain because it would allow the DB Engine to early exit making comparisons. Not a net gain on my laptop tho. On 4 million search (just adding a zero crushes my pc) adding the 5's take 4 seconds longer to execute vs just 2 tally method.
If more is less then maybe something like this?
declare @n int=1000000;
SET STATISTICS TIME,IO ON
select v.n
from (values (2), (3), (5)) v(n)
union all
select fn.N*2+1
from dbo.fnTally(6, @n/2-1) fn
where not exists(select 1
from dbo.fnTally(1, sqrt(fn.N/2)) ffn
where (fn.N*2+1)%(ffn.N*2+1)=0
and (fn.n*2+1)<>(ffn.n*2+1))
and (fn.N*2+1)%6 in(1, 5)
and not (fn.N*2+1)%10=5;
SET STATISTICS TIME,IO OFFRegarding naming attribution I follow the china shop rule. You broke it you bought it. Ha, any tiny change and now it's yours
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
- Steve Collins wrote:
Hmmm imo the issue of mathematical appropriateness of n = 6q + r is debatable. I found this link which describes it a little. Without complete analysis it seems to be not a sufficiently conclusive proof. Is it appropriate? Idk I'm inclined to deny. But for this topic it's interesting I guess
including
p.N%6 IN(1, 2)It does increase the performance a bit, so I would argue it is appropriate. It changes the number of prime candidates from n/2 (odd numbers) to n/3 (n%6 in(1,5)).Steve Collins wrote:The WHERE clause above the UNION ALL is quite unnecessary. Have you been chatting with an LLM?
It is necessary if you want the function to work correctly. Just say someone asks for prime number up to a maximum of 1, without the WHERE clause it would return 2, which is incorrect. It does not add anything measurable to the runtime so is included.
Steve Collins wrote:On my computer adding additional criteria which notionally reduce the number of comparisons seems to not have a predictable effect on runtimes. When the max int of the search is 1,000,000 the results with/without are within the variance range (based on visual inspection and I'm still using fnTally because no SQL 2022 yet). I have to admit by this conversation and others I'm getting more motivated to upgrade. Why is it not automatically faster? SQL is an interpreted language. We have no visibility into how the DB Engine exits looping due to WHERE clause conditions afaik.
A lot of the time in your algorithm is taken up calculating the
*2+1. The code with the GENERATE_SEQUENCE does not have this so is more sensitive to minor improvements.Steve Collins wrote:What about 5's? Any odd number ending in 5 above 5 cannot be prime. That seems like it should be a gain because it would allow the DB Engine to early exit making comparisons. Not a net gain on my laptop tho. On 4 million search (just adding a zero crushes my pc) adding the 5's take 4 seconds longer to execute vs just 2 tally method.
Yes, any number ending with either 0 or 5 is divisible by 5, but 5 is one of the first numbers tested in the not exists series.
-
The amount of computation could be reduced by restricting the list of divisors to just the prime numbers already found that are <= SQRT(candidate). The problem is that the IO used to store and read these would almost certainly exceed any saving in computation.
- Chris Wooding wrote:
The amount of computation could be reduced by restricting the list of divisors to just the prime numbers already found that are <= SQRT(candidate). The problem is that the IO used to store and read these would almost certainly exceed any saving in computation.
Yes, ideally you would only test by dividing by the prime numbers already found up to the square root of the candidate, but how can you do that in a SQL statement?
- Jonathan AC Roberts wrote:
including
p.N%6 IN(1, 2)It does increase the performance a bit, so I would argue it is appropriate. It changes the number of prime candidates from n/2 (odd numbers) to n/3 (n%6 in(1,5)).QED? It seems to produce the correct output but where is the proof?
Jonathan AC Roberts wrote:It is necessary if you want the function to work correctly. Just say someone asks for prime number up to a maximum of 1, without the WHERE clause it would return 2, which is incorrect. It does not add anything measurable to the runtime so is included.
In the name of speed I completely threw away the number 2 as well
Jonathan AC Roberts wrote:A lot of the time in your algorithm is taken up calculating the
*2+1. The code with the GENERATE_SEQUENCE does not have this so is more sensitive to minor improvements.CROSS APPLY doesn't seem to help. I get no improvement from
declare @n int=1000000;
SET STATISTICS TIME,IO ON
--select count(*)
select v.n
from (values (2), (3), (5)) v(n)
union all
select i.odd
from dbo.fnTally(6, @n/2-1) fn
cross apply (values (fn.N*2+1)) i(odd)
where not exists(select 1
from dbo.fnTally(1, sqrt(fn.N/2)) ffn
cross apply (values (ffn.N*2+1)) o(odd)
where i.odd%o.odd=0
and i.odd<>o.odd)
and i.odd%6 in(1, 5)
and not i.odd%10=5
;
SET STATISTICS TIME,IO OFFJonathan AC Roberts wrote:Yes, any number ending with either 0 or 5 is divisible by 5, but 5 is one of the first numbers tested in the not exists series.
It tests 5 and and it seemingly keeps on testing
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
- Steve Collins wrote:Jonathan AC Roberts wrote:
including
p.N%6 IN(1, 2)It does increase the performance a bit, so I would argue it is appropriate. It changes the number of prime candidates from n/2 (odd numbers) to n/3 (n%6 in(1,5)).QED? It seems to produce the correct output but where is the proof?
Steve Collins wrote:Jonathan AC Roberts wrote:It is necessary if you want the function to work correctly. Just say someone asks for prime number up to a maximum of 1, without the WHERE clause it would return 2, which is incorrect. It does not add anything measurable to the runtime so is included.
In the name of speed I completely threw away the number 2 as well
Keeping 2 in there doesn't really change the speed.
Steve Collins wrote:Jonathan AC Roberts wrote:A lot of the time in your algorithm is taken up calculating the
*2+1. The code with the GENERATE_SEQUENCE does not have this so is more sensitive to minor improvements.CROSS APPLY doesn't seem to help. I get no improvement from
declare @n int=1000000;
SET STATISTICS TIME,IO ON
--select count(*)
select v.n
from (values (2), (3), (5)) v(n)
union all
select i.odd
from dbo.fnTally(6, @n/2-1) fn
cross apply (values (fn.N*2+1)) i(odd)
where not exists(select 1
from dbo.fnTally(1, sqrt(fn.N/2)) ffn
cross apply (values (ffn.N*2+1)) o(odd)
where i.odd%o.odd=0
and i.odd<>o.odd)
and i.odd%6 in(1, 5)
and not i.odd%10=5
;
SET STATISTICS TIME,IO OFFIf you install SQL 2022 you can use GENERATE_SERIES and try it with no "*2+1" and with "*2+1" and see the difference.
CROSS APPLY expands out the calculation so it will also do it twice if you put it in a CROSS APPLY.
Steve Collins wrote:Jonathan AC Roberts wrote:Yes, any number ending with either 0 or 5 is divisible by 5, but 5 is one of the first numbers tested in the not exists series.
It tests 5 and and it seemingly keeps on testing
What evidence do you have for that?
-
Ok the proof by induction is acceptable
If 2 doesn't add or subtract from what's being measured that's a good reason to get rid of it imo
For my projects the upgrade to SQL 2022 is not currently scheduled. I'm going to look into again
What evidence? Seemingly = none but the lack of performance change
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
Viewing 15 posts - 31 through 45 (of 77 total)
You must be logged in to reply to this topic. Login to reply