Are the data types I've chosen the best choices?
-
A newbie here. I have these columns, here are the samples and the data types I've chosen:

I'd just like to ask if the choices I've made for the data types are the best choices?.
Thank you in advance
-
Datatypes look OK, except for one. Remember to size your VARCHARs to be the maximum expected length of the data they will hold.
You're probably better off using CHAR(3) for CPZ Code.
And save yourself typing a load of square brackets when writing queries by removing the spaces from the column names.
-
Thanks for the help Phil. I'll be sure to do that. Does putting a lower varchar length equate to lower storage size and vice versa?. Just curious.
Also I'd kindly like to ask what the difference is between VACRCHAR limit 3 and CHAR(3)?
-
This link gives a few reasons for choosing shorter varchar lengths.
In terms of storage, CHAR(n) columns are always n characters long.
VARCHAR(n) columns are anything between 2 and (n + 2) characters, in storage terms (as varchar columns include two characters for length information).
As your data items are always 1, 2 or 3 in length, CHAR(3) will store the data more efficiently than VARCHAR(3) overall.
-
Understood. Thank you very much for the clarification and your help.
- Phil Parkin wrote:
This link gives a few reasons for choosing shorter varchar lengths.
In terms of storage, CHAR(n) columns are always n characters long.
VARCHAR(n) columns are anything between 2 and (n + 2) characters, in storage terms (as varchar columns include two characters for length information).
As your data items are always 1, 2 or 3 in length, CHAR(3) will store the data more efficiently than VARCHAR(3) overall.
That also depends on whether you are using data compression or not. Typically for large amounts of data you will be, which means even char(n) columns will not store blanks after the actual value.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- Mr_X wrote:
A newbie here. I have these columns, here are the samples and the data types I've chosen:
I'd just like to ask if the choices I've made for the data types are the best choices?.
Thank you in advance
- I wonder why it's apparently not important to know the time of day when something was actually received especially when it seems important to have one for the Response On column.
- There is no way that I'd ever create column names with spaces in them. It relegates you to always have to use brackets around every column name that has them and that can make for some pretty ugly code that's a bit difficult to read. Save the spaces for the "presentation layer".
- I agree on the CHAR(3) recommendation for CPZ code.
- Columns like "Type", "Action Taken", Cancellation Group", and "Cancellation Reason" should be INT, SMALLINTs, or TINYINTs that point to reference tables. The "Serviceable" column may fall into the same category but I don't know your data.
- "Response By" also falls into the same category as those in number 4 but it's even more important here UNLESS the column is populated by the initial insert and is never updated. Going from a NULL to some name is an absolute killer on this class of "ModifiedBy" columns when it come to page splits and the fragmentation and excessive log file usage columns cause.
- Unless this is a history table, CPZ Name shouldn't even be in this table. CPZ Name should be in a separate table by CPZ Code.
In fact, a lot of what I said seriously depends on what kind of table this actually is... which you've not stated.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thank you for your reply Jeff and help. I'll be sure to implement these. I'd kindly like to ask what the differences are between SMALLINTs and TINYINTs are?.
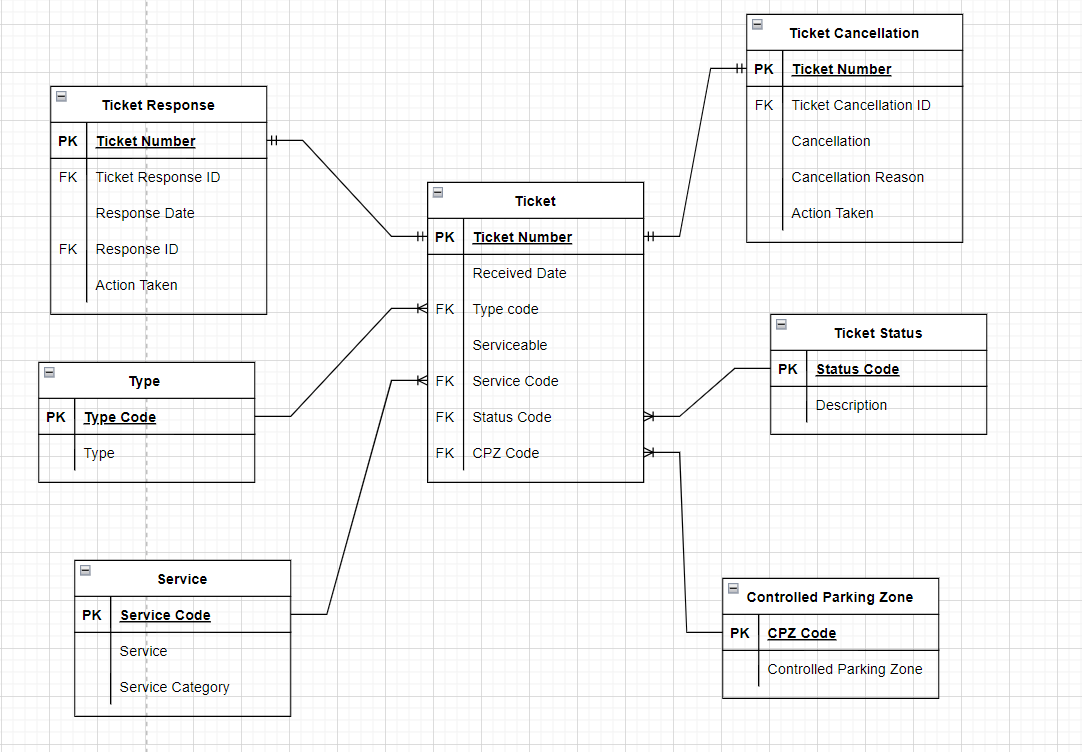
So far we've come up with the following model:
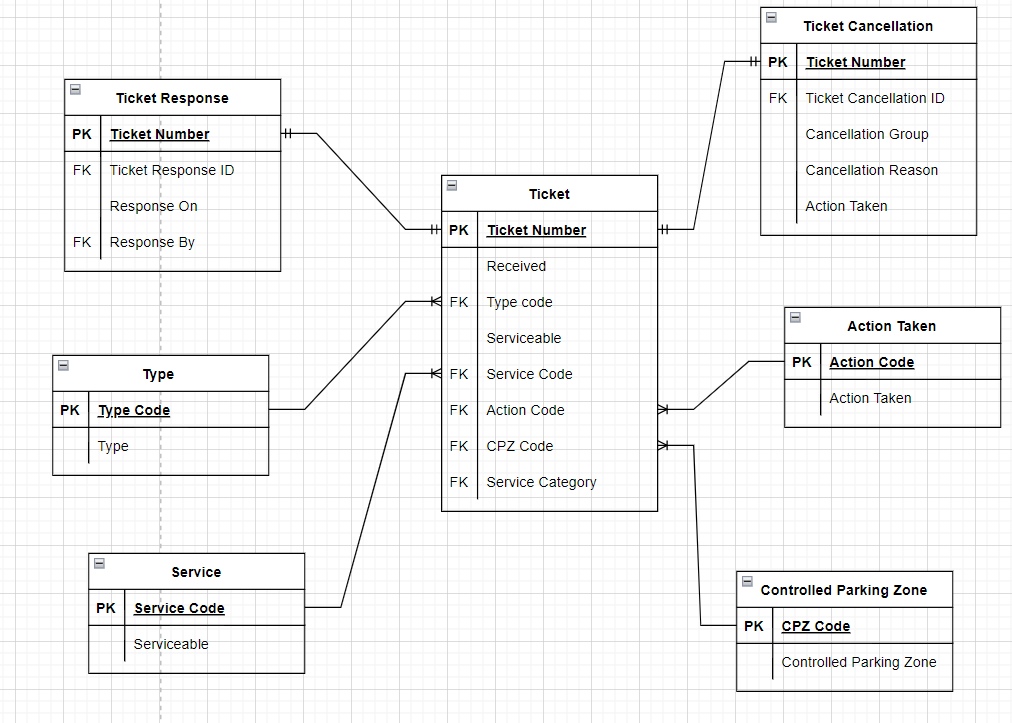
I made some modifications:
Here is a link to the thread: https://www.sqlservercentral.com/forums/topic/i-am-trying-to-normalize-this-table-but-i-am-not-sure-if-im-on-the-write-track
Here is the .drawio file if you would like to have a look: https://www.mediafire.com/file/1iqlvsnsbdsng6v/draft.drawio/file
I think I was unfair on you all because I didn't share the actual table with you. I've now masked any compromising data. Here is a link to the Excel file which contains the actual table (before normalization):
https://www.mediafire.com/file/v7appzbia4y6ooj/Correspondence.xls/file
-
I took a look at your spreadsheet and immediately found a pretty nasty issue... about 2/3rds of the rows have duplicated Ticket Numbers.
As for being new to the game, you might as well learn early that your favorite search engine is the key to finding the MS Documentation. Of course, like all documentation, you have to know enough to know what questions to ask.
Of course, you already know what is meant by a "Data Type". You proved that in your first post. So I recommend you run the following search for the differences between Int, SmallInt, and TinyInt and the follow your nose. I could tell you a lot of the same things but I might miss somethings.
data types in T-SQL
Of course, the disadvantage of some documentation is that they can't tell it all to you under a single link nor even in a single topic. For example, your question about the differences between Int, Smallint, and Tinyint aren't actually fully covered on the most obvious MS link in the search suggestion I provided above. For example, what are the actual advantages concerning resource usage and performance? How are they affected by compression/decompression and what affect is to be had in indexes when a compressed column that contains any of those data types are updated from NULL to some number?
Getting back to your data, it also looks like I may have been correct about the Serviceable column needing its own lookup table. Look at the dupes in that column on the spreadsheet that you provided and I believe you'll agree. Either that or, because of the changes you made, should be dropped from the Ticket table, altogether.
Another issue is that you have no "CancelledOn" or "CancelledBy" column in your "Ticket Cancellation" table.
And, just to say it again, you have dupes in the TicketNumber column in the spreadsheet you provided.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
based on the tables above and their relations I have the following comments/questions
- Ticket
- Serviceable needs to be removed as you moved it to table Service
- Service Category - you have it as a FK - to what table? and could it be that it should be a attribute of Service instead of another table?
- Ticket response - can you have more than one response per ticket?
- If No then this table is not required and Response On/By should be attributes of Ticket.
- If Yes then its PK should be TicketResponseID and the Ticket Number should be a FK to Ticket
- You have Response By as a FK - you didn't gave us the related table.
Ticket Cancellation - Same as for Ticket Response.
I do wonder how is your Ticket actions process. This is what should drive part of the definition of tables Ticket Response/Cancellation.
if process flow is
Open ticket
Add response
Add response
Close ticket or Cancel ticket
then likely you only need one table "TicketActions" which has the flow of interaction with the ticket with following
- TicketActionID (PK)
- ResponseTypeID (link to ResponseType table)
- Ticket Number (FK to Ticket)
- ResponseOn
- ResponseBy
- CancellationGroup
- CancellationReason (Should this be free text or a FK to a Cancellation Type table?)
- ActionTaken
- Ticket
- Jeff Moden wrote:
- There is no way that I'd ever create column names with spaces in them. It relegates you to always have to use brackets around every column name that has them and that can make for some pretty ugly code that's a bit difficult to read. Save the spaces for the "presentation layer".
- Columns like "Type", "Action Taken", Cancellation Group", and "Cancellation Reason" should be INT, SMALLINTs, or TINYINTs that point to reference tables. The "Serviceable" column may fall into the same category but I don't know your data.
Remember, this is logical data modeling. Spaces in names are fine in the logical model. It's a horrible mistake to skip logical modeling and go straight to physical tables, although sadly most people do it all the time.
Remember, too, that the logical data model should be easily understood and use by business people. In fact, if possible, keep all developers out of the first one or two logical design meetings.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- frederico_fonseca wrote:
Ticket response - can you have more than one response per ticket?
If Yes then its PK should be TicketResponseID and the Ticket Number should be a FK to Ticket
No, the PK should be ( Ticket Number, Ticket Reponse Id ), that is, ticket number first.
And you should be consistent with naming. That is, if you use spaces between words, do that throughout the model. If you don't use spaces, do that throughout the model. Thank heavens MS doesn't use any form of camel case in their system tables ... what a nightmare that would be.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Thank you for your reply.
Jeff Moden wrote:I took a look at your spreadsheet and immediately found a pretty nasty issue... about 2/3rds of the rows have duplicated Ticket Numbers.
Scott suggested putting a 'Ticket Response ID' column I imagine this was the reason. Please correct me if I'm wrong.
Jeff Moden wrote:Of course, you already know what is meant by a "Data Type". You proved that in your first post. So I recommend you run the following search for the differences between Int, SmallInt, and TinyInt and the follow your nose. I could tell you a lot of the same things but I might miss somethings.
I had a look at SmallInt and TinyInt (I came across MediumInt and BigInt). As I understand it they they cover different number ranges, amounts of digits and sizes. SmallInt covers a large number range than TinyInt, can handle more digits and therefore takes up more storage.
Jeff Moden wrote:Getting back to your data, it also looks like I may have been correct about the Serviceable column needing its own lookup table. Look at the dupes in that column on the spreadsheet that you provided and I believe you'll agree.
frederico_fonseca wrote:Serviceable needs to be removed as you moved it to table Service
Yes I definitely agree with you here. I actually moved it to the table 'Service' but I just forgot to move it from the 'Ticket' table.
frederico_fonseca wrote:Service Category - you have it as a FK - to what table? and could it be that it should be a attribute of Service instead of another table?
For all the FKs I put down they were sort of left over from a previous draft. However recalling what Scott said:
ScottPletcher wrote:No, the PK should be ( Ticket Number, Ticket Reponse Id ), that is, ticket number first.
I need to actually include the composite keys to reflect this. I'll share the refined version soon to reflect all the changes suggested here.
- ScottPletcher wrote:Jeff Moden wrote:
- There is no way that I'd ever create column names with spaces in them. It relegates you to always have to use brackets around every column name that has them and that can make for some pretty ugly code that's a bit difficult to read. Save the spaces for the "presentation layer".
- Columns like "Type", "Action Taken", Cancellation Group", and "Cancellation Reason" should be INT, SMALLINTs, or TINYINTs that point to reference tables. The "Serviceable" column may fall into the same category but I don't know your data.
Remember, this is logical data modeling. Spaces in names are fine in the logical model. It's a horrible mistake to skip logical modeling and go straight to physical tables, although sadly most people do it all the time.
Remember, too, that the logical data model should be easily understood and use by business people. In fact, if possible, keep all developers out of the first one or two logical design meetings.
The key here is that a whole lot of people convert their logical models to physical models using the exactly the same names.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - ScottPletcher wrote:
Remember, too, that the logical data model should be easily understood and use by business people. In fact, if possible, keep all developers out of the first one or two logical design meetings.
Done correctly, I absolutely agree. I rarely see it done correctly, though.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)

Viewing 15 posts - 1 through 15 (of 38 total)
You must be logged in to reply to this topic. Login to reply