Are Indexes Actually Changes to the System?
- xsevensinzx - Friday, October 5, 2018 6:55 AM
It's quite true that what works for one system may not work for another and you have to adjust your design accordingly.
LinkedIn: https://www.linkedin.com/in/sqlrv
Website: https://www.sqlrv.com - Aaron N. Cutshall - Friday, October 5, 2018 9:28 AM
Wow I did not know that SQL Server's btree's didn't handle random keys well. What would be a good server for random keys? Any idea what SQL Server's defect is in that area?
- patrickmcginnis59 10839 - Friday, October 5, 2018 9:59 AM
The issue isn't because of the btree implementation, but how data is distributed. In an SMP system like SQL Server (or Oracle, Postgres, MySQL, etc.) all data is stored on a single node. MMP systems (like Azure, Teradata, Netezza, Redshift, etc.) store data across multiple nodes. SMP systems handle sequential data better than MMP systems and conversely MMP systems handle random data better because the data is distributed across the nodes. Again, it's all in how the underlying system works and how you implement you data design.
LinkedIn: https://www.linkedin.com/in/sqlrv
Website: https://www.sqlrv.com - Aaron N. Cutshall - Friday, October 5, 2018 10:10 AM
I studied up on btree's for a bit and other than bigger keys needing bigger storage, it was pretty much expected that splitting and merging were expected costs of the implementation.
- patrickmcginnis59 10839 - Friday, October 5, 2018 10:28 AM
That is true. Of course, if the data is consecutive then the effects of splitting and merging are significantly reduced. Near random data like GUIDs cause much more overhead due to splitting and merging. When data is distributed across nodes, then the work is equally distributed to each node. To paraphrase a popular idiom: many nodes makes the work light!
LinkedIn: https://www.linkedin.com/in/sqlrv
Website: https://www.sqlrv.com - Aaron N. Cutshall - Friday, October 5, 2018 10:37 AM
uote]
Heh I can't say I agree with that, many nodes seem to really complicate everything. Sure, maybe its easy enough when you can absolutely guarantee that all transactions will take place on the one node that has all the data local to that node. Once that assumption is invalid then theres more work to do!
Ok now you have thousands of nodes for your database. Of course, they're 100 percent reliable and there are always network connections between them that never fail. Thank goodness too, imagine if hardware failed in an installation like that right? Well maybe not, but certainly two generals can surely coordinate their attacks simply by using messengers that may or may not get through right????
https://en.wikipedia.org/wiki/Two_Generals%27_Problem
Yeah sorry, I love ruminating about distributed systems, fascinating to me, but off topic for indexes!
edit: not blaming anybody but myself for digressing!
-
Does any one have a repeatable test to demonstrate that a non-random INT PK is better than a random GUID PK? Say, for a join search of 100K out of 1M rows?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - patrickmcginnis59 10839 - Friday, October 5, 2018 11:37 AM
I think there is still ranges on the values for each node to sort of tackle the issue of not having even distributions.
- Aaron N. Cutshall - Friday, October 5, 2018 10:10 AM
Well someone correct me here if I'm wrong, from my understanding it's mostly because it's storing the non-sequential key in sequential order on disk. As new random keys come in, data can be reorganized to fit in order on the write and this is where the performance can tank. The same is true on the MPP system if you have a lot of data movement on a query. This is where the query forces the system to reorganize the data (copy data from one node to another) to ensure you have even distributions when querying. Thus, to me, data movement is happening on both. Just one on writes where the other on reads.
That's why I think when you get into larger data sets like with mine where you have like 4TB or more of GUID's, inserts tank hard when you randomly cluster on the GUID key. You push in 10 GB of unique GUID's into that table and all hell breaks lose on the clustered index.
- xsevensinzx - Saturday, October 6, 2018 7:29 AM
It depends on many things.
1. Width of the rows
2. Fill Factor
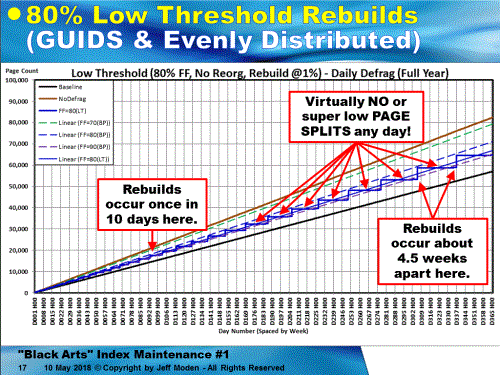
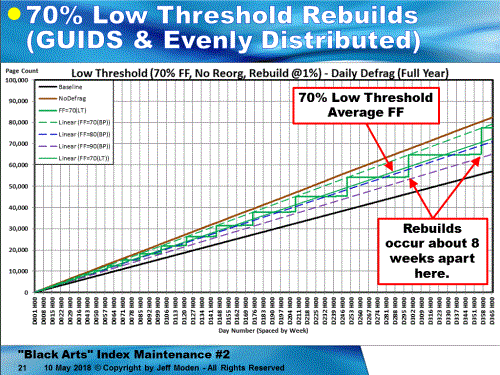
3. Current condition of the pages in the table.In the testing I've done at a smaller scale than yours, adding 10K rows of random GUIDs per day to a 3.6 million row table causes no page splits (not even supposedly good ones) for 4.5 weeks after a REBUILD at 80% and no page splits for about 8 weeks after a REBUILD of 70%. In the following charts, "Daily Defrag" means that the defrag code was run daily but didn't actually do a defrag until the logical fragmentation exceeded 1% (not a typo... 1%, not 10%)
.
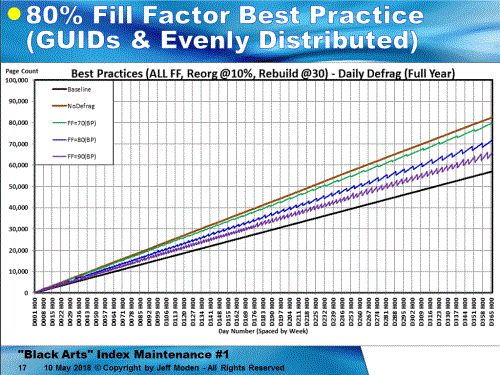
Of course, that's using ONLY rebuilds. If you use REORGANIZE, game over... Here's the chart for 70, 80, and 90% fill factors using standard "Best Practices", which lock in on the use of REORGANIZE because of the low percentage that 10K rows represents compared to 3.6 Million rows. The Black line is the "Baseline" where the GUIDs were inserted in ever-increasing order (like a NEWSEQUENTIAL ID). Any line segment steeper than that line contains not only the "good" page splits, but also the "bad" page splits where there's data movement. The Brown line is where no defragmentation was done for random inserts. It measures out at a 68% natural Fill Factor, in this case. While it still has "bad" page splits, there are not concentrated by REORGANIZE removing free space as indicated by the vertical drops in the 70, 80, and 90% lines. You can see that the REORGs occur quite often (once per week near the end o f the test for 80%). It is REORGANIZE that makes GUIDs look so bad because it removes the ability of a Fill Factor to prevent page splits by not adding free space above the Fill Factor. (And forgive the mislabeling of the title of the slide)
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Jeff - can you explain this comment you made please: "NEVER USE REORGANIZE!!!! IT DOESN'T WORK THE WAY YOU THINK IT DOES AND IS A LEADING CAUSE OF PAGE SPLITS!!!"
As the author of that code, I'd like to know why you think it causes page splits. I can only guess that you're thinking of the case where fragmentation is happening, and fill factor is set to 100%, and someone continually reorganizes. As reorganize doesn't set the fill factor, only adheres to the one that is set (documented), it fills the pages back up again, so random inserts cause page splits, if someone doesn't set the fill factor correctly.
Is that what you're talking about? If so, saying to never use it, instead of 'set fill factor then use it' is very, very poor advice.
Thanks
Paul Randal
CEO, SQLskills.com: Check out SQLskills online training!
Blog:www.SQLskills.com/blogs/paul Twitter: @PaulRandal
SQL MVP, Microsoft RD, Contributing Editor of TechNet Magazine
Author of DBCC CHECKDB/repair (and other Storage Engine) code of SQL Server 2005 - Paul Randal - Wednesday, October 10, 2018 10:30 AM
I hope you will engage with Jeff when he replies, but I think one of the drawbacks as explained to me is that reorg never expands free space within each leaf page whereas rebuild (effectively) will, by simply writing out brand new index pages with the free space specified by the fill factor.
In other words, if there is a particular page that is too full (above the level specified by fill factor), this page will not be split or otherwise have rows redistributed to generate additional free space within that page to try to get back to the free space specified by the fill factor, whereas a page that is too empty will be given rows (ie., merged with other too empty pages or otherwise gain rows through shuffling) or something to that effect.
-
Correct. Reorg (and anything else) can't move rows to the right in the index structure (freeing up space), only to the left (taking up space). That's always been the design. There are absolutely special cases where reorganize is not the best solution. But that absolutely isn't a reason to NOT use it EVER. It depends on the insert pattern into the pages, the delete/update pattern, the fill factor that's been set, the usage pattern, and so on. There are pros and cons to both - see https://www.sqlskills.com/blogs/paul/sqlskills-sql101-rebuild-vs-reorganize/.
What about for a 1TB clustered index, with three years of sales data, and fragmentation happens in the current month. Rebuild to get rid of that? No, of course not. It all depends on the scenario at hand.
A blanket 'never use reorganize' is a poor generalization IMHO.
Paul Randal
CEO, SQLskills.com: Check out SQLskills online training!
Blog:www.SQLskills.com/blogs/paul Twitter: @PaulRandal
SQL MVP, Microsoft RD, Contributing Editor of TechNet Magazine
Author of DBCC CHECKDB/repair (and other Storage Engine) code of SQL Server 2005 - Paul Randal - Wednesday, October 10, 2018 10:30 AM
I'm at work right now but, yes, I can support my claim and I can do it with more than simple rhetoric. The charts above are the tip of the ice berg there. I'll build a proper reply when I get home tonight. Thanks for your interest, Paul. And, just to be sure, I know you wrote the code and I also know that MS kind of held you at gunpoint to come up with some general guidelines on the subject of defragging/rebuilding indexes but this in no way is meant as a slam on Paul Randal. I'll also be sure to include a copy of the sp_IndexDNA proc I built to really examine what goes on inside of indexes at the page level. I've got to thank you there as well because, without DBCC IND, DBCC PAGE (both of which you also wrote), and your good instructions on how to use them, I'd have no such proof.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Paul Randal - Wednesday, October 10, 2018 2:42 PM
Yes. Absolutely. You don't even want to think of using REORGANZE on that bad boy. But, again, that's rhetorical on my part. I'll put my money where my mouth is when I answer your other post tonight. I don't have a 1TB table but I have a 146GB table that I tested against. I'll share the results there.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 15 posts - 46 through 60 (of 72 total)
You must be logged in to reply to this topic. Login to reply