Are Indexes Actually Changes to the System?
-
Thanks, Jeff - great points.
In particular, given the vagaries of index effects that might be different in production vs non-production, I think this process modification (i.e. added to the end of the one that Andrew Gothard listed above) would be the most important for any index changes, even when the index passed QA with flying colors:With all that being understood, when you deploy indexes, someone has to know what the baseline of performance looks like and monitor it carefully when the index is deployed. They also have to monitor its effect when batch runs occur
That's really the only way to keep tabs on the index from the moment it hits the real world and allows the relevant people to see if some unexpected performance issues arise that would allow them to disable or remove the index quickly if they see a bad deviation from the baseline of performance.
I'm an "accidental DBA," so it's amazing to me how hard it is to baseline performance and gauge the impact that indexes have. I naively started off thinking that somehow it would have been possible to test indexes with more confidence.Thanks again,
webrunner-------------------
A SQL query walks into a bar and sees two tables. He walks up to them and asks, "Can I join you?"
Ref.: http://tkyte.blogspot.com/2009/02/sql-joke.html - Aaron N. Cutshall - Wednesday, October 3, 2018 9:26 AM
Heh... it DID come out loud, didn't it? 😀
I gave a two hour presentation at the Pittsburgh SQL Saturday this past weekend. It's actually a shame that I "only" had two hours... it could be an all day precon and still not touch on everything that I've discovered about indexes and, in particular, index maintenance since starting the "great experiment" way back in Jan of 2016. I've got about 350 hours of testing an observation into it since Nov 2016 alone.
For those of you in Michigan, I'm giving the same presentation as the "GLASS" (Greater Lansing SQL Server) user group on Tuesday, October 9th and a followup with the "SPID" (SQL PASS In Detroit) user group on Thursday, November the 8th.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Wednesday, October 3, 2018 10:40 AM
This would make a good book, you know. Seriously! It would be something that I could seek to get great info about indexes and scan for general knowledge! That way you'd be able to pour all of your research and results into this and reach lots of folks.
LinkedIn: https://www.linkedin.com/in/sqlrv
Website: https://www.sqlrv.com - Aaron N. Cutshall - Wednesday, October 3, 2018 10:59 AM
Ya know...that's not a bad idea, Aaron. Thank you for the idea and the confidence.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Wednesday, October 3, 2018 11:07 AM
Sure thing, let me know if I can be of assistance!
LinkedIn: https://www.linkedin.com/in/sqlrv
Website: https://www.sqlrv.com - Aaron N. Cutshall - Wednesday, October 3, 2018 10:59 AM
I'll 2nd that...

-
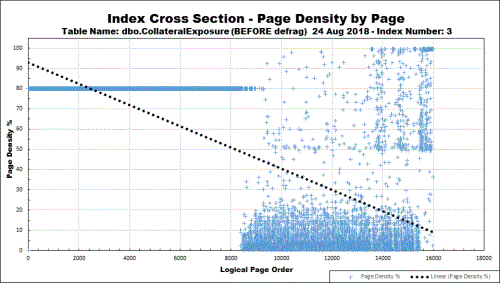
As a teaser, here's what happens to a supposedly "Append Only" index that is made to suffer "ExpAnsive" updates. Just imagine how low the page density and percent of logical fragmentation is at the active portion of the index (the right-hand side). This is a 5GB non-clustered index.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Wednesday, October 3, 2018 7:47 PM
Great stuff Jeff. I look forward to seeing (and playing with) a full test harness.
Would I be safe to assume that this represents a worst case scenario where there are a bunch of NULLable (N)VARCHAR colulms that were inserted with NULL values and then updated with high character count character strings?
Based on the left-hand side of the chart, I assume that the test started with a 80% fill factor index rebuild... Would I be correct to assume that a 100% fillfactor starts falling apart faster but doesn't fall apart worse?
Also, please correct me if I'm wrong, but this seems to made a good case for not allowing NULLable columns and using default values that are close to median length of the expected values.For example: If we assume the average email address is 25 characters (some shorter some longer), my thought is that email_3 is going to be far less susceptable to the effects that you're demonstrating.
CREATE TABLE dbo.TestTable (
email_id INT NOT NULL
CONSTRAINT pk_TestTable PRIMARY KEY CLUSTERED
WITH (FILLFACTOR = 100, DATA_COMPRESSION = PAGE) ON [PRIMARY],
email_1 VARCHAR(125) NULL,
email_2 VARCHAR(125) NOT NULL
CONSTRAINT df_TestTable_email2 DEFAULT ('') -- the standard default value for strings,
email_3 VARCHAR(125) NOT NULL
CONSTRAINT df_TestTable_email3 DEFAULT (REPLICATE('', 25)) -- a smarter default perhaps?
) ON [PRIMARY];CREATE NONCLUSTERED INDEX ix_TestTable_email1
ON dbo.TestTable (email_1)
WITH (FILLFACTOR = 100, DATA_COMPRESSION = PAGE, ONLINE = ON) ON [PRIMARY];CREATE NONCLUSTERED INDEX ix_TestTable_email2
ON dbo.TestTable (email_2)
WITH (FILLFACTOR = 100, DATA_COMPRESSION = PAGE, ONLINE = ON) ON [PRIMARY];CREATE NONCLUSTERED INDEX ix_TestTable_email3
ON dbo.TestTable (email_3)
WITH (FILLFACTOR = 100, DATA_COMPRESSION = PAGE, ONLINE = ON) ON [PRIMARY];WITH
cte_n1 (n) AS (SELECT 1 FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) n (n)),
cte_n2 (n) AS (SELECT 1 FROM cte_n1 a CROSS JOIN cte_n1 b),
cte_n3 (n) AS (SELECT 1 FROM cte_n2 a CROSS JOIN cte_n2 b),
cte_Tally (n) AS (
SELECT TOP (1000000)
ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM
cte_n3 a CROSS JOIN cte_n3 b == 100,000,000
)
INSERT dbo.TestTable (email_id)
SELECT t.n FROM cte_Tally t; - Jason A. Long - Wednesday, October 3, 2018 8:59 PM
It's amazing what a simple picture will do for understanding. You're absolutely correct on most counts. There is a major except that, like me at the beginning, you've missed and will do a head slap to yourself when you make the realization.
Would I be safe to assume that this represents a worst case scenario where there are a bunch of NULLable (N)VARCHAR colulms that were inserted with NULL values and then updated with high character count character strings?
Correct except that it's not the worst case scenario for "Append Only". On this index, only the latest data was updated. Its far worse when older data is updated, as well. And, yes... it was due to multiple NULLable columns starting off as NULL (Modified_By is one of my "favorites"). Because of the relatively large expansion caused by the update of just a couple of columns in the index (and it doesn't matter if they're keys or INCLUDEs), one than one page split occurred on the original data in one page leaving most of the pages at 20% full or less. Since that section of the data is also the most read data, we're wasting roughly 80% of the necessary memory when we read this index not to mention how bad the logical fragmentation actually is. So, it's a 4 pronged performance problem... massive blocking page splits on the updates (which blocks reads from concurrent selects), massive extra log file usage from the blocking splits, much slower updates due to the splits, and wasting 80% of the RAM when we read this index during (mostly) SELECTs and other UPDATEs.
And, yes, setting defaults is the way to go unless you're at some low width (say, 10 or less), in which case converting to CHAR or NCHAR would solve a whole lot of the problem with little cost depending on the average width of the data that will come. I have a couple of "Proof-of-Principle" tools (they're really simple... anyone could make them) to help 1) find all variable width columns and their defaults (if any) and 2) a simple tool to evaluate what the biggest bank for the buck may be for adding (usually, spaces) for defaults to prevent "ExpAnsive" updates.
Based on the left-hand side of the chart, I assume that the test started with a 80% fill factor index rebuild... Would I be correct to assume that a 100% fillfactor starts falling apart faster but doesn't fall apart worse?
In this case, mostly not correct. Inserts do NOT obey the Fill Factor if the pages don't exist yet, which is the case for "Append Only" indexes. Inserts will always try to fill pages to 100% (even if the pages do exist) and so the idea that a Fill Factor of less than 100% will delay the splits that occur when "Expansive" updates occur in "INSERT/Immediately Process with Updates" scenarios just isn't true. You are correct. I intentionally rebuilt this index at 80% to show that and to clearly demonstrate that all the 80% Fill Factor is doing is wasting 20% of the page space (and, therefore, memory and disk space) for most of the data, which will never change after the initial round of updates.
In other words, a 100% Fill Factor will not cause the index to start falling apart faster UNLESS you rebuild the index immediately after a large number of inserts, which is impractical and, as previously stated, will waste 20% of the memory for most of the pages which have already been updated. The only thing that could be done to save this index from the "Exploded Broom Tip" would be to solve the "ExpAnsive" update problem. Partitioning would help solve the problem of wasted memory for the static portion of the index but it won't solve the problem of the "Exploded Broom Tip" and the massive pages splits that occur.
Also, please correct me if I'm wrong, but this seems to made a good case for not allowing NULLable columns and using default values that are close to median length of the expected values.
Very close and definitely the right idea but the "median" will only account for about half the expansion (which IS better than not accounting for it at all but with caveates). I will admit that I'm still playing with this part (how wide the default should be) because, as is the nature of median, there are places where you will end up assigning way to large a default based on super wide exceptions. The other problem is for widely varying columns, the median will only account for 50% of the expansion and a wider default may be necessary. The cool part about the wider defaults is that they'll really help when it comes to preventing page splits and that "wasted free space" will be recovered when an index rebuild is done. The bad part of it is that it does waste memory on the most active part of the index. There's a tradeoff in there somewhere but it's totally data dependent including characteristics such as min, average, and max row sizes and the estimated number of rows per page. There's also the problem of sparsely populated columns that might only ever be filled in half the time or less.It's a complex problem to "automate"...
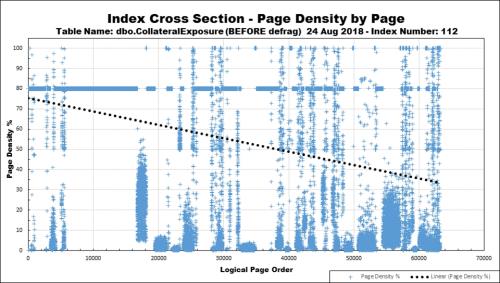
And that's just for "Append Only" with "ExpAnsive" updates. There are "Random Silos" (with many variations as to cause), "Sequential" silos, and "Key Order Changing non-ExpAnsive" updates that throw a monkey wrench into what people think they know about index maintenance, as well. Here's a great example of an actual in-production NCI that demonstrates some of those traits. It's also why I call the stored procedure that collects the data for the charts "sp_IndexDNA" (the "sp_" is because I do use it as a system proc in the master database) because it looks like a DNA smear.Finally, it turns out that, when it comes to index maintenance and page splits, GUIDs are actually the absolute BEST! Not only do they require very little maintenance (when done properly), but they virtually eliminate even good page splits (which are still relatively costly) for WEEKS and MONTHS.
Here's a chart of a GUID keyed clustered index (123 bytes wide) that has gone 4.5 weeks with the addition of 10,000 rows per day without any page splits and has just gotten to the point of needing what I call a "Low Threshold Rebuild".
Of course, "ExpAnsive" updates throw all of that on the ground.--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Thursday, October 4, 2018 7:03 AM
Jeff,
I have to question your statement about GUIDs used in a clustered index. As GUID generation is near random (or random-like), how can that be an effective clustered index? In my past experience, replacing GUID values with consecutive values (such as an IDENTITY column) allow for far greater INSERT performance and excellent SEEK performance due to the consecutive nature. Can you perhaps explain that?
Aaron
LinkedIn: https://www.linkedin.com/in/sqlrv
Website: https://www.sqlrv.com - Aaron N. Cutshall - Thursday, October 4, 2018 7:21 AM
Not only is GUID generation near random (it's actually pseudo-random but close enough), it's totally evenly distributed and that's the ONLY type of index that will totally take advantage of a Fill Factor.
The chart above is of a 3.65 million row GUID keyed clustered index just before it reaches 1% fragmentation (and I rebuild these at 1%, which is where the term "Low Threshold Rebuilds" comes from).
Each page (contrary to popular belief) contains 8096 bytes of free space (most folks say 8060 to account for average size row headers and the slot array). The data in the rows, including the row header and slot array, occupies 123 bytes. That means that there's room for 65 rows per page, in this instance. Setting the Fill Factor to 80% means that each page contains 52 rows right after a rebuild leaving room for 13 more rows per page. There are 70,193 pages in this index. Because of the near totally evenly distributed nature of GUID inserts, that means that I can add 13 more rows per page without any page splits (not even supposedly "Good" page splits) for a total of 70,193*13 or 912,509 rows can be added with virtually no page splits. Adding just 10,000 rows per day means that I can go a theoretical 91 days without having any page splits. In reality and owing to the random nature of GUIDs (even though very well evenly distributed over time), page splits do occur before then (as shown in the chart at the 50% page fullness). Instead of waiting for 10% to REORGANIZE (NEVER USE REORGANIZE!!!! IT DOESN'T WORK THE WAY YOU THINK IT DOES AND IS A LEADING CAUSE OF PAGE SPLITS!!!) or 30% to REBUILD, which means we've waiting for most all the damage to be done, I REBUILD when the damage (page splits) first begins... and on this size row (123 bytes including the row header) and inserting 10,000 rows per day, it takes 4.5 weeks for any page splits to occur.
For a 24 byte wide NCI, you can go nearly 2 months at a 80% fill factor and nearly 3 months at 70% with virtually no page splits (not even "good" ones) which also means you can go that long without the index needing any index maintenance (provided that you DON'T make the mistake of using REORGANIZE).
The other cool part is that, unlike "Append Only" indexes, there are NO hotspots during INSERTs. Between that and no page splits whatsoever, inserts are very fast and have virtually no contentious behavior. The bad part is that most pages will be touched and will be in memory. The pages will load very quickly because there's virtually no logical fragmentation but they'll still need to be in memory (as with any INSERT).
As for SEEKs, "It Depends". If the predominate usage is a GUI, then even an "Append Only" index will read just one page at a time. The SEEK will be the same except that GUIDs are so random that you may have to have more pages loaded in memory than "Append Only" indexes to cover the most recent (supposedly most currently used) data but, if the data is historical in usage (meaning any period of the index could be hit), then there's no difference between an IDENTITY key and a GUID key.
If, however, the usage of the table is predominately for batch processing, then I agree. The IDENTITY keyed index will contain the most recent rows in a much more contiguous set of pages and won't require as many pages to be in memory to do the processing on the most recent rows. However, once the data is in memory, the idea of randomness making things slow is pretty much a myth. It's the same reason why SSDs are effective. Memory is built to handle randomness quite nicely which is why they name memory "RAM".
Knowing that GUIDs are so very effective for preventing page splits and, if you don't make the mistake of using REORGANIZE, can go weeks or months without any page splits or the need for index maintenance (they are the BEST in that category), I've been asked many times if I would intentionally build a system that used GUIDs as Keys. My answer is not only "No" but "HELL NO". They're 4 times longer than an INT (which get's added to every NCI even if the NCI isn't GUID keyed) and, as previously stated, will require more of the index to be loaded into memory because of their extreme and totally even distribution. Just remember that once in memory, performance isn't affected as much a most people would think especially for single row lookups but also for batch jobs.
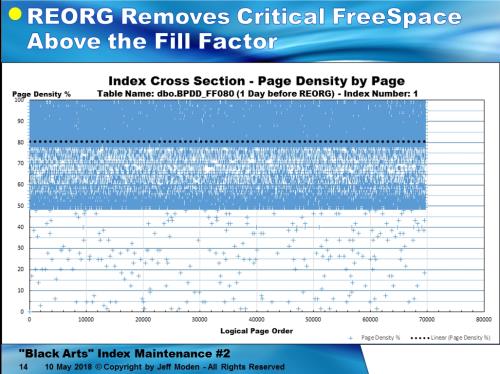
The key here is that if you're stuck with random GUID keys (SharePoint, for example?), there's no need to beat yourself to death with index maintenance and no need to suffer from the massive page splits that will occur if you use the current "Best Practice" of REORGANIZEing at 10% and REBUILDing at 30%. Use only REBUILD and do it as soon as logical fragmentation hits 1% instead of waiting for all the damage to be done.
BTW... here's the same data (I mean EXACTLY the same data... I copied the GUIDs during the tests) once index maintenance gets stuck on REORGANIZE because of the size of the table. Like I said, REORGANIZE does NOT work the way you may think and you need to stop using it for anything and everything NOW!. It's like a really bad drug habit... The more you use it, the more you need to use it.
I'll also tell you that the chart for "1 Day AFTER the Reorg" looks exactly the same. What you can't see is the couple of thousand pages that were consolidated to live above the Fill Factor, which is the most critical space for preventing page splits. In other words, REORGANIZE actually perpetuates the need for index maintenance rather than preventing the need and, in the process, causes a whole lot of page splits EVERY DAY instead of being able to go weeks with no page splits.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Thursday, October 4, 2018 7:03 AM
Wow! Thank you for the detailed reply. This is great info.
I think I worded my supposition poorly, I'm aware that fill factor is completely ignored outside of rebuilds and reorgs. My assumption, was that you had completed any & all inserts before doing the 80% rebuild and then did the updates to generate those results... Based your follow up, I think I got the first two operations reversed... Assuming I've got it straight now, it was, 1) rebuild the existing index at 80% and then 2) insert new "new" data rows (at 100%) and then update the just the "new" data rows.In other words, a 100% Fill Factor will not cause the index to start falling apart faster UNLESS you rebuild the index immediately after a large number of inserts, which is impractical
Actually, this is a fairly common scenario for large ETL data loads where it's easier to disable all indexes on a table, load the data (without being encumbered by said indexes) and then rebuilding them once the load is complete. The work you've done here is likely to be especially relevant in this scenario, given that the common wisdom seems to be, "The disable > load > rebuild process happens so frequently that that page splits from updates are a non-issue".It's a complex problem to "automate"...
If you have a reliable method of determining which specific columns are most responsible for the page splits on a given index, it should be a simple matter write a bit of dynamic sql that 1) looks at the current defaults, 2) looks at average & max values of the existing data & 3) drops and recreates the default constraints based on the values captured in step 2.GUIDs are actually the absolute BEST! Not only do they require very little maintenance (when done properly), but they virtually eliminate even good page splits (which are still relatively costly) for WEEKS and MONTHS.
This makes my brain hurt... On one hand, I've been reading your posts for years, you're a brilliant guy who's fed me my fair share of crow (and maybe a pork chop or two) over the years... on the other hand, this flies in the face of all, current, conventional wisdom... Especially since MS has effectively dealt with the "Ascending Key Problem" (not related... but... related). At this point, all I can say is that, because it's you, I'll keep an open mind... My gut says that the "NOT NULL / wide default" solution will be more effective at maintaining high page densities while, at the same time, reducing bad page splits... but... experience also tells me that you're smarter than my gut... Either way, I look forward to seeing more.I'm sure you have no shortage of volunteers, but if there's anything I can do to help, let me know.
- Jeff Moden - Thursday, October 4, 2018 8:39 AM
Thanks for the clarification Jeff. When I switched out GUIDs (that the original developers put in) for Identity values, I got a HUGE performance gain especially for joins. I do understand your GUID use case better now.
LinkedIn: https://www.linkedin.com/in/sqlrv
Website: https://www.sqlrv.com -
If you have a reliable method of determining which specific columns are most responsible for the page splits on a given index, it should be a simple matter write a bit of dynamic sql that 1) looks at the current defaults, 2) looks at average & max values of the existing data & 3) drops and recreates the default constraints based on the values captured in step 2.
That could kind of work on NCIs because they usually only have 1 or 2 expansive columns in keys but then you have the likes of INCLUDEs and bloody LOBs that end up in the CIs because they just happen to fit "in row". I actually have an "extras" section in my presentation that tells you how to move existing LOBs out of row and how to guarantee that they'll never go "in row".
This makes my brain hurt... On one hand, I've been reading your posts for years, you're a brilliant guy who's fed me my fair share of crow (and maybe a pork chop or two) over the years... on the other hand, this flies in the face of all, current, conventional wisdom... Especially since MS has effectively dealt with the "Ascending Key Problem" (not related... but... related). At this point, all I can say is that, because it's you, I'll keep an open mind... My gut says that the "NOT NULL / wide default" solution will be more effective at maintaining high page densities while, at the same time, reducing bad page splits... but... experience also tells me that you're smarter than my gut... Either way, I look forward to seeing more.
Ah... I was talking mostly about keeping them from splitting and how to properly do index maintenance on them. In other words, they are, in fact, third only to totally static indexes and truly "Append Only" indexes (neither of which would require any maintenance) and they have fewer page splits than the constant barrage of "good" page splits in an "Append Only" index and they have no "hot spots" if they're unique, but they pretty much suck at everything else. See my latest post just above this one for more info on that. Search for "Hell No" to jump to the section of that post that I'm talking about.
So, as so often happens with you and me (you're a lot smarter on many things than I am), I actually do agree with your gut (and mine). I wouldn't jump to the bad conclusion of designing tables that use GUIDs as the keys. They're just the "Best" when it comes to index maintenance and concurrency even though they suck in a whole lot of other areas.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Aaron N. Cutshall - Thursday, October 4, 2018 9:24 AM
A part of your gain may actually be because of the way you were maintaining the GUID indexes. You did use REORGANIZE, right? 😀 Everyone does. :sick:
Still, I totally agree with your move away from GUIDs especially with performance in mind. After all, it's not index maintenance that pays the bills. 😉
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)


Viewing 15 posts - 16 through 30 (of 72 total)
You must be logged in to reply to this topic. Login to reply