Alternative to LAG(SUM) - Can a Column Reference The Sum of the Values Above It
-
Hi Everyone,
I'm trying to do something that seems pretty simple, but SQL Server doesn't seem to allow it.
For a given column - let's call it col C - I want to use the SUM of all values in col C in rows above the current row to determine the value of col C in the current row. The value in the current row is determined by comparing that SUM of all values above it to the value of a couple of other cols in the current row. The value for column C in the first row is determined only by looking at other values in that row. It doesn't need to look at the SUM of values above it - there are no values above it. This is a little bit of a simplification. In reality, there are groups in the data, so when I say first row, I mean the first row in each partition.
I tried using Lag(SUM) to accomplish this and it didn't work. I got an error saying something like "You can't use a windowed function as the argument of another windowed or aggregate function."
I guess the crux of the issue is that I'm trying to build a column whose value depends on that same column's values in all the previous rows. It's kind of like recursion and the base case for the recursion is the first row of each partition. In other words, SQL Server would have to calculate the value of the column for the first row in each partition first. That would be easy, because for the first row, the value only depends on other columns in that row. Only after calculating the value for the first row, could it continue and calculate the value of the column for the second row, and only after calculating the value for the second row, could it continue and calculate the value for the third row, and so on. Maybe that's just not how SQL Server works and it's not possible.
I thought this description of the problem might be simpler than including all the gory details, but if it would be better to post the actual table with all of the relevant columns, please let me know and I'll do that.
If anyone has any ideas, it would be very much appreciated. I've been working on this for a while and I'm getting ready to give up and use a cursor 🙂
Thanks.
-
Maybe someone else understood what you want, i myself am totally lost at what ur problem is or even what ur trying to achieve.
Always provide sample code, because text descriptions can be interpreted differently or missunderstood.
With these temporary tables in examples we can give a concrete solution to your problem isntead of just theories, because the results can be compared to the wanted results you have given.
Also allows users to test their theories, doesnt need to be as complex as the original just to get the idea across.
I want to be the very best
https://www.sqlservercentral.com/articles/forum-etiquette-how-to-post-datacode-on-a-forum-to-get-the-best-help
Like no one ever was -
It sounds very much like a running total calculation that you want to do therefore I am guessing you need to use SUM with an OVER clause.
-
-- *** Test Data which you should have provided. ***
SET ANSI_NULLS, QUOTED_IDENTIFIER, ANSI_PADDING ON
GO
CREATE TABLE #t
(
PartitionNo int NOT NULL
,PartitionOrder int NOT NULL
,ColA int NOT NULL
,ColB int NOT NULL
,PRIMARY KEY (PartitionNo, PartitionOrder)
);
GO
INSERT INTO #t
VALUES (1, 1, 1, 1)
,(1, 2, 1, 2)
,(1, 3, 1, 3)
,(6, 1, 6, 1)
,(6, 4, 6, 4)
,(6, 7, 6, 7)
,(6, 8, 6, 8);
GO
-- *** End Test Data ***
SELECT PartitionNo, PartitionOrder, ColA, ColB
,SUM(ColA + ColB) OVER (PARTITION BY PartitionNo ORDER BY PartitionOrder) AS ColC
FROM #t
ORDER BY PartitionNo, PartitionOrder; -
Thanks for the response ktflash. I agree, code will make it easier. The details are below.
triplAxe, thanks for the response. I tried a running total, but that didn't work. Hopefully the details below will
illustrate why.
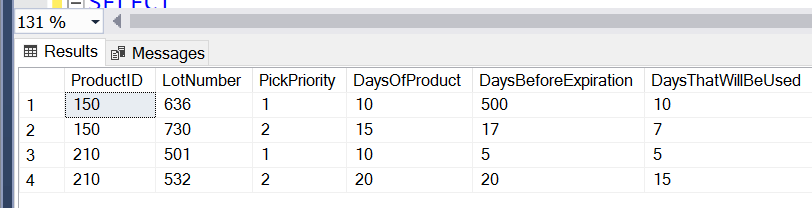
OK, so here's an example of how I want the data in the table to look when I'm done:

Here's the scenario. We have a bunch of different products in a warehouse and for each product we have multiple lots of that product. Each lot has a separate expiration date that applies to the whole lot. We measure the amount of product we have in each lot by the number of days it will take us to sell the whole lot. So if we typically sell 10 pounds of apples per day and we have 100 pounds of apples in a lot, then we say we have 10 days worth of apples in that lot. The column DaysOfProduct above captures that value.
Each row above represents one lot of one product sitting in a warehouse. What I'm trying to figure out is how much of the quantity(in Days) in each lot will actually get used before that lot expires and we have to throw the remaining product in that lot out. PickPriority tells us which lot of a product will be picked from first. So in the example above, let's say Product ID 150 is apples. When we need to sell more apples, we'll keep pulling from lot 636 until we deplete the whole lot or the lot expires, because lot 636 has PickPriority 1. Only after we're done with that lot(we deplete the whole lot or it expires) will we move on to lot 730.
Since we have 10 days worth of apples in lot 636, we won't start pulling from lot 730 until 10 days from now. UNLESS lot 636 expires before that 10 days is up. In the example above, it doesn't expire. We have 500 days until lot 636 expires so we'll get to use all 10 days worth of apples in lot 636. That's why the value in the column DaysThatWillBeUsed is 10.
If we look at the second line above, lot 730, at first glance it looks like we might get to use all of that lot too. It has 15 days worth of apples and we have 17 days until expiration. Looks good. Except we won't start picking from lot 730 until we're done with lot 636. So we'll be waiting for 10 days. After 10 days has elapsed, we'll only have 7 days left until lot 730 expires. That's why DaysThatWillBeUsed is 7 for lot 730.
Let's look at one more row before I get to my question. Let's say Product 210 is oranges. If we look at row 4 above(lot 532), it looks like we'll only get to use 10 days worth of the 20 days in that lot because there are 10 days worth of oranges in lot 501, in row 3, and lot 501 will get picked from before lot 532(because lot 501 has a lower numbered PickPriority, and therefore higher priority). But we won't actually have to wait 10 days to start picking from lot 532 because lot 501 will expire in 5 days. So instead of only getting to use 10 days of the product in lot 532, we'll get to use 15 days.
Ok, hopefully some of you are still with me. Here's the issue. All of the columns above are known and given to me except DaysThatWillBeUsed . That's what I'm trying to calculate. When trying to calculate that value for a lot that has PickPriority 1, it's very simple. Just take the lesser of DaysOfProduct and DaysBeforeExpiration. If I have 10 days worth of product and I have 12 days before expiration, I'll get to use all 10 days. But if DaysBeforeExpiration is lower than DaysOfProduct, let's say 3 days before expiration, then I'll only get to use 3 days worth of product and I'll have to throw the other 7 days worth out. This is simple because we don't have to account for any lots that might be ahead of us. There are no lots ahead of us since we're PickPriority 1.
For all other PickPriorities it's more complicated. In these scenarios, if we want to know that we'll have enough time to sell an entire lot of a product, we have to make sure that the sum of the DaysOfProduct for the lot in question plus the combined DaysThatWillBeUsed of all lots above the lot in question will be less than the DaysBeforeExpiration for the lot in question. The sum I'm talking about is the combination of 2 things:
1. the amount of time we'll have to sit and wait while other lots are being picked from.
2. the amount of time it will take to get through our entire lot once we actually get started picking from it.
These 2 things combined represent the amount of time, starting from today, that it will take to get through the entire lot in question. If that number is <= the days until expiration, we'll get to use the whole lot. If it's greater, then we'll only get to use DaysBeforeExpiration - (the amount of time we'll have to sit and wait until other lots are being picked from) .
This number, "the amount of time we'll have to sit and wait until other lots are being picked from" is the sum of all of the DaysThatWillBeUsed of the lots above the lot in question. It makes sense to use the sum of all DaysThatWillBeUsed instead of the sum of all DaysOfProduct because we won't always be waiting the full DaysOfProduct for each lot to be consumed. This is why a running total of DaysOfProduct doesn't work.
OK, now, finally, my question:
If you've followed all of that, you can see that the formula for DaysThatWillBeUsed for a lot with PickPriority <> 1 will have to use 3 values:
- Its own row's DaysOfProduct
- Its own row's DaysBeforeExpiration
- The sum of all the previous rows' DaysThatWillBeUsed
Number 3 is where it gets complicated. I'm trying to calculate the value of the column DaysThatWillBeUsed for the current row, but it depends on all of the values in that column for previous rows. In Excel this is trivial. Not the case in SQL Server. We currently have it working in Excel, but the business group wants to move the logic somewhere that is more easily accessible by other groups.
I thought the following would give me the sum of all previous values in the DaysThatWillBeUsed column for a given ProductID:
LAG(SUM(DaysThatWillBeUsed) OVER (PARTITION BY ProductID ORDER BY PickPriority), 1,0) OVER(PARTITION BY ProductID ORDER BY PickPriority)
but you can't use one windowed function as an argument of another.
Another problem I ran into when doing this was that I had to use a calculated column. I had the table above, but without the last column(DaysThatWillBeUsed). I tried doing the following to add the DaysThatWillBeUsed column:
Select
CASE
....
END As DaysThatWillBeUsed
,*
From #TestSumWithoutDaysThatWillBeUsed
but inside that Case statement I have to self-reference the column that I'm building. Since it doesn't exist yet, I definitely can't do that even if SQL Server would allow a column to reference itself. So instead, I tried doing it through the graphical interface in Management studio. I created a column named DaysThatWillBeUsed and tried putting the code for calculating its value in the Computed Column Specification section of the properties of the column. It didn't work and gave me no error messages.
Anyway, if anyone has followed all of that I appreciate it very much and I would be very grateful for any ideas.
Here's the code for creating and populating my sample table. My sample table has values in the DaysThatWillBeUsed column for all rows. I put them in there to show what they should be, but obviously my whole problem is that I know how to calculate DaysThatWillBeUsed for PickPriority 1 rows, but not for the others.
--DROP TABLE #TestSUM
CREATE TABLE #TestSUM (
ProductID INT,
LotNumber INT,
PickPriority Int,
DaysOfProduct INT,
DaysBeforeExpiration INT,
DaysThatWillBeUsed INT
)
INSERT INTO #TestSUM (ProductID,LotNumber,PickPriority, DaysOfProduct, DaysBeforeExpiration,
DaysThatWillBeUsed) VALUES(150,636,1,10,500,10)
INSERT INTO #TestSUM (ProductID,LotNumber,PickPriority, DaysOfProduct, DaysBeforeExpiration,
DaysThatWillBeUsed) VALUES(150,730,2,15,17,7)
INSERT INTO #TestSUM (ProductID,LotNumber,PickPriority, DaysOfProduct, DaysBeforeExpiration,
DaysThatWillBeUsed) VALUES(210,501,1,10,5,5)
INSERT INTO #TestSUM (ProductID,LotNumber,PickPriority, DaysOfProduct, DaysBeforeExpiration,
DaysThatWillBeUsed) VALUES(210,532,2,20,20,15)
SELECT * FROM #TestSUM
-
I suspect your test data is missing some edge conditions but the following should get you started:
WITH ProdDays
AS
(
SELECT ProductID, LotNumber, PickPriority, DaysOfProduct, DaysBeforeExpiration
,CASE
WHEN DaysBeforeExpiration < DaysOfProduct
THEN DaysBeforeExpiration
ELSE DaysOfProduct
END AS ProductDays
FROM #TestSUM T
)
,PreviousDays
AS
(
SELECT ProductID, LotNumber, PickPriority, DaysOfProduct, DaysBeforeExpiration
,COALESCE
(
SUM(ProductDays)
OVER
(
PARTITION BY ProductID
ORDER BY PickPriority
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING
)
, 0
) AS DaysPicked
FROM ProdDays
)
SELECT ProductID, LotNumber, PickPriority, DaysOfProduct, DaysBeforeExpiration
,CASE
WHEN DaysBeforeExpiration - DaysPicked < DaysOfProduct
THEN DaysBeforeExpiration - DaysPicked
ELSE DaysOfProduct
END AS DaysThatWillBeUsed
FROM PreviousDays; -
Good start, Ken.
In case others are interested in refining his, here is some sample data which trips up the solution:
INSERT #TestSUM
(
ProductID
,LotNumber
,PickPriority
,DaysOfProduct
,DaysBeforeExpiration
,DaysThatWillBeUsed
)
VALUES
(150, 636, 1, 10, 500, 10)
,(150, 730, 2, 15, 17, 7)
,(210, 501, 1, 10, 5, 5)
,(210, 532, 2, 20, 20, 15)
,(210, 533, 3, 40, 50, 25)
,(210, 534, 4, 40, 60, 15); -
That data will certainly break my first effort. The safe, albeit slow, use of recursion produces slightly different results to you but maybe my understanding of the problem is wrong.
WITH DaysUsed
AS
(
SELECT S.ProductID, S.LotNumber, S.PickPriority, S.DaysOfProduct, S.DaysBeforeExpiration
,X.DaysThatWillBeUsed
,X.DaysThatWillBeUsed AS CumlativeDays
FROM #TestSUM S
CROSS APPLY
(
VALUES
(
CASE
WHEN S.DaysBeforeExpiration < S.DaysOfProduct
THEN S.DaysBeforeExpiration
ELSE S.DaysOfProduct
END
)
) X (DaysThatWillBeUsed)
WHERE S.PickPriority = 1
UNION ALL
SELECT S.ProductID, S.LotNumber, S.PickPriority, S.DaysOfProduct, S.DaysBeforeExpiration
,X.DaysThatWillBeUsed
,D.CumlativeDays + X.DaysThatWillBeUsed AS CumlativeDays
FROM #TestSUM S
JOIN DaysUsed D
ON S.ProductID = D.ProductID
CROSS APPLY
(
VALUES
(
CASE
WHEN S.DaysBeforeExpiration - D.CumlativeDays < 0
THEN 0
WHEN S.DaysBeforeExpiration - D.CumlativeDays < S.DaysOfProduct
THEN S.DaysBeforeExpiration - D.CumlativeDays
ELSE S.DaysOfProduct
END
)
) X (DaysThatWillBeUsed)
WHERE S.PickPriority = D.PickPriority + 1
)
SELECT ProductID, LotNumber, PickPriority, DaysOfProduct, DaysBeforeExpiration, DaysThatWillBeUsed, CumlativeDays
FROM DaysUsed
ORDER BY ProductID, PickPriority; -
That is looking good to me – my sample data was incorrect. I was also thinking that a recursive solution was required, good stuff.
-
If this is really a picking algorithm it looks somewhat simplistic to me. In my limited expericence picking algorithms tend to be a lot more complex and are best done in the middle tier.
-
Ken and Phil,
Thank you very much for looking at this. I really appreciate it. I've been in meetings all day and just started looking at your responses. I wanted to say thank you before the day ended.
This is great. I was ready to give up and use a cursor. I tried it last night and it took around an hour and a half to loop through 90,000 records, and that was after I took everything out of the loop, like update statements. All I left in was the fetch next. So all I was doing was loading the variables from the next row into the cursor and it took .06 seconds per row. I knew cursors were slow, but I didn't think they were that slow.
Anyway, I'm going to start looking at incorporating your second solution now, Ken, but I might not fully digest it until tomorrow. I'll let you know how it goes.
Thanks again.
John
-
Ken, your second solution works!
Unbelievable. I still only understand about half of what you're doing, but I tested it on some more test data and it works.
Thank you very much.
-
I am glad the solution works.
If you find recursion to be too slow you might also want to consider the Quirky Update:
This does have the overhead of having to create a temp table. Also, it is non-relational and relies on the internals of SQL Server so could, in theory, be broken by a patch. You should read all the comments to get a feel for the pros and cons. It seems to work on SQL2019 CU11.
DROP TABLE IF EXISTS #t;
CREATE TABLE #t
(
ProductID int NOT NULL
,PickPriority int NOT NULL
,DaysOfProduct int NOT NULL
,DaysBeforeExpiration int NOT NULL
,CumlativeDays int NOT NULL
,Boundary bit NOT NULL
,PRIMARY KEY (ProductID, PickPriority)
);
INSERT INTO #t
SELECT ProductID, PickPriority, DaysOfProduct, DaysBeforeExpiration, 0
,CASE
WHEN ProductID = LAG(ProductID) OVER (PARTITION BY ProductID ORDER BY PickPriority)
THEN 0
ELSE 1
END AS Boundary
FROM #TestSUM
ORDER BY ProductID, PickPriority;
DECLARE @CumlativeDays int = 0
,@ProductID int = 0;
UPDATE T
SET @CumlativeDays =
CASE Boundary
WHEN 1
THEN
CASE
WHEN DaysBeforeExpiration < 0
THEN 0
WHEN DaysBeforeExpiration < DaysOfProduct
THEN DaysBeforeExpiration
ELSE DaysOfProduct
END
ELSE
CASE
WHEN DaysBeforeExpiration - @CumlativeDays < 0
THEN 0
WHEN DaysBeforeExpiration - @CumlativeDays < DaysOfProduct
THEN DaysBeforeExpiration - @CumlativeDays
ELSE DaysOfProduct
END
+ @CumlativeDays
END
,CumlativeDays = @CumlativeDays
,@ProductID = ProductID
FROM #t T WITH (TABLOCKX)
OPTION (MAXDOP 1);
WITH PrevCumlativeDays
AS
(
SELECT ProductID, PickPriority
,COALESCE
(
LAG(CumlativeDays)
OVER
(
PARTITION BY ProductID
ORDER BY PickPriority
)
, 0
) AS CumlativeDays
FROM #t
)
SELECT S.ProductID, S.LotNumber, S.PickPriority, S.DaysOfProduct, S.DaysBeforeExpiration
,CASE
WHEN S.DaysBeforeExpiration - P.CumlativeDays < 0
THEN 0
WHEN S.DaysBeforeExpiration - P.CumlativeDays < S.DaysOfProduct
THEN S.DaysBeforeExpiration - P.CumlativeDays
ELSE S.DaysOfProduct
END
FROM #TestSUM S
JOIN PrevCumlativeDays P
ON S.ProductID = P.ProductID
AND S.PickPriority = P.PickPriority
ORDER BY ProductID, PickPriority;
Viewing 13 posts - 1 through 13 (of 13 total)
You must be logged in to reply to this topic. Login to reply