aggregate value by group
-
Hi,
I have the following table:
create TABLE test (
[Claim ID] int NOT NULL,
[Damage ID] int NOT NULL,
[Location ID] int NOT NULL,
[Seq Num] int NOT NULL,
[Reserve Date] datetime NOT NULL,
[Reserve amt] Decimal(18,2) NOT NULL
)
insert into test
select 668835, 631560, 36225627, 1, '06-09-2014', 20000
UNION ALL
select 668835, 631560, 36225627, 2, '06-19-2014', 20000
UNION ALL
select 668835, 631558, 36225627, 1, '08-28-2014', 16000

What I need to do is create a new column called Reserve Accuracy Amt for each row that will sum the Reserve Amt for the max reserve date for each Claim ID, Damage ID, and Location ID that is <= the date for that row ( I think i'm saying that right).
so in the example above, the first row has a reserve date of 6-09-2014 and there were no other rows for that group before that date so the new field should just contain 20,000. The second row has the same Claim ID, Damage ID, and Location ID and a reserve date of 6-19-2014. Since this is the max row for that group it should also just have 20,000. Now the third row has a new damage code, but same claim ID and location id with a reserve date of 8-28-2014. So this row should sum the Max row of the 2 damage codes for that claim id and location id. So this row should add the 20,000 from 6-19-2020 (since this is the max row for damage code 631560) and also the 16,000 which is 36,000.
I'm not sure if this can be done using set based logic or maybe a cursor of some sort. The table has many more rows, but I would need this result:
thanks
Scott
-
Scott,
You didn't say why the max row for the first group was not summing the two rows... you just say it's the max row so it maintains the value from the previous row. This leaves things open to interpretation, in that what if the amount on this 2nd row was not the same as the previous row? Or, what if there had been more than 2 rows in the group? I ask because your initial statement says to sum the rows in the group with a date less than or equal to the current row's date. Thus I would expect to see 40,000 as the new value for the 2nd row, and additionally, because your grouping was based on the 3 columns, I'd start fresh at 16,000 for the 3rd row.
However, as I'm somewhat familiar with the nature of claim data for insurance, it might make more sense to group based on the claim id and not necessarily any lower than that, especially if you're trying to compute a reserve amount to date... But as I don't know your data structure, I'd have to guess, and that's almost always a bad idea where financial data is concerned. Can you please clarify?
Steve (aka sgmunson) 🙂 🙂 🙂
Rent Servers for Income (picks and shovels strategy) -
It appears this query meets the requirements, or maybe it's close? Something like this
drop table if exists #test;
go
create TABLE #test (
ClaimID int NOT NULL,
DamageID int NOT NULL,
LocationID int NOT NULL,
SeqNum int NOT NULL,
ReserveDate datetime NOT NULL,
ReserveAmt Decimal(18,2) NOT NULL);
insert into #test
select 668835, 631560, 36225627, 1, '06-09-2014', 20000
UNION ALL
select 668835, 631560, 36225627, 2, '06-18-2014', 27000
UNION ALL
select 668835, 631560, 36225627, 3, '06-19-2014', 25000
UNION ALL
select 668835, 631558, 36225627, 1, '08-28-2014', 16000;
with
max_cte as (
select *, max(ReserveAmt) over (partition by ClaimID, DamageID, LocationID order by ReserveDate) max_Amt
from #test),
row_cte as (
select *, row_number() over (partition by ClaimID, DamageID, LocationID order by max_Amt desc) sum_rn
from max_cte)
select *, iif(sum(case when sum_rn=1 then ReserveAmt else 0 end) over (partition by ClaimID, LocationID order by ReserveDate)=0, max_Amt,
sum(case when sum_rn=1 then ReserveAmt else 0 end) over (partition by ClaimID, LocationID order by ReserveDate)) ReserveAccuracyAmt
from row_cte
order by ReserveDate;Output
ClaimIDDamageIDLocationIDSeqNumReserveDate ReserveAmtmax_Amt sum_rnReserveAccuracyAmt
668835631560 3622562712014-06-09 00:00:00.00020000.0020000.00320000.00
668835631560 3622562722014-06-18 00:00:00.00027000.0027000.00127000.00
668835631560 3622562732014-06-19 00:00:00.00025000.0027000.00227000.00
668835631558 3622562712014-08-28 00:00:00.00016000.0016000.00143000.00Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
Hi,
sorry, it's hard to put in words. So if the claim id, damage id and location id are the same, then I need to sum the reserve amt only for the max reserve date row for that group but only for the rows that are <= the reserve date of that row. I'm not sure i am explaining it correctly but it's easier for me to go row by row and explain what is need for each row. So if i change the table a bit to make it different amounts like this:
drop table test
create TABLE test (
[Claim ID] int NOT NULL,
[Damage ID] int NOT NULL,
[Location ID] int NOT NULL,
[Seq Num] int NOT NULL,
[Reserve Date] datetime NOT NULL,
[Reserve amt] Decimal(18,2) NOT NULL
)
insert into test
select 668835, 631560, 36225627, 1, '06-09-2014', 20000
UNION ALL
select 668835, 631560, 36225627, 2, '06-19-2014', 30000
UNION ALL
select 668835, 631558, 36225627, 1, '08-28-2014', 16000
UNION ALL
select 668835, 631558, 36225627, 2, '08-31-2014', 10000
Now there are 2 different groups for this claim. 1 group has Damage ID 631560 and the other has Damage ID 631558. they both have the same location so that is fine. now I need to go through each record in order by reserve date and get the max reserve date for each group at that date. So on 6-9-2014 (the earliest date) there was only 1 group and 1 row at that time and no other rows since all other rows have a reserve date later that 6-9-2014 so the new field should just have 20,000. Now the next date is 6-19-2020 and that is the max row for the 1st group and since it's the only group that was available at that time it should only show 30,000. Now for the 8-24-2014 row we now bring in another group, but still have the previous group. So i need to get the max reserve date of each group on 8-28-2014 which is the 16,000 for the new group but need to also add the 30,000 from the max row of the old group which gives me 46,000. And finally on 8-31-2014 we have another row for the 2nd group so i need to get the max reserve date for both groups which is the 10,000 for group 2 and 30,000 for group 1 which gives me 40,000. I'm not sure if there is a better way to explain it.
-
Hi All,
so i met with business users and it seems i had the requirements a bit mixed up. I think it might even be a bit simpler now. So i made the test data a bit more simple:
create TABLE test (
[Claim ID] int NOT NULL,
[Damage ID] int NOT NULL,
[Location ID] int NOT NULL,
[Seq Num] int NOT NULL,
[Reserve Date] datetime NOT NULL,
[Reserve amt] Decimal(18,2) NOT NULL
)
insert into test
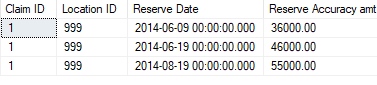
select 1, 234, 999, 1, '06-09-2014', 20000
UNION ALL
select 1, 234, 999, 2, '06-19-2014', 30000
UNION ALL
select 1, 567, 999, 1, '06-09-2014', 16000
UNION ALL
select 1, 567, 999, 2, '08-19-2014', 25000
what I need is to get the distinct list of Claim ID, Location ID and Reserve Date from the test table which is simple. Once I have that list I need to then create a new Reserve Accuracy Amt column and for each row in the new list and find the max row for each grouping of the Claim ID, Damage ID and Location ID from the original test table where the Reserve Date is <= the Reserve Date for each row of the new list.
so I would need this result in the new table based off the original test table above:
so in the original table, there are 3 distinct reserve dates for the claim. For 6-9-2014 the original test table only had 2 rows for each Claim ID, Damage ID and Location ID group where the reserve date was <= 6-9-2014 so the amount is the the sum of the 20,000 and 16,000 to get the 36,000. For the 6-19-2014 row, the max for each group would be the 6-19-2014 row from damage 234 and also the 6-9-2014 row for damage 567, since they both are <= 6-19-2014. So the total is 46,000. for the 8-19-2014 row, the max for each group would be the 6-19-2014 row for damage 234 and the 8-19-2014 row for damage 567 so the total would be 55,000.
i was think maybe an outer apply would work here but can't get it working correclty.
sorry for the confusion.
thanks
-
[Edit] Ok, there were 2 updates above and this post was after the first without having read the second. So I'm wiping it out. To be updated if possible
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
There are different ways to accomplish this. Here's one. In order to use the ROW_NUMBER function in the OUTER APPLY I created a table valued function called dbo.func_reserve_accuracy_amount. When OUTER APPLIED to the distinct ReserveDate, ClaimID, and LocationID triplets it returns (afaik) the correct ReserveAccuracyAmt. In order to the create the function the table had to be made into a physical table.
DDL and data
drop table if exists dbo.tTest;
go
create TABLE dbo.tTest (
ClaimID int NOT NULL,
DamageID int NOT NULL,
LocationID int NOT NULL,
SeqNum int NOT NULL,
ReserveDate date NOT NULL,
ReserveAmt Decimal(18,2) NOT NULL);
go
insert into dbo.tTest
select 1, 234, 999, 1, '2014-06-09', 20000
UNION ALL
select 1, 234, 999, 2, '2014-06-19', 30000
UNION ALL
select 1, 567, 999, 1, '2014-06-09', 16000
UNION ALL
select 1, 567, 999, 2, '2014-08-19', 25000;tvf
drop function if exists dbo.func_reserve_accuracy_amount;
go
set nocount on;
create function dbo.func_reserve_accuracy_amount(
@ReserveDate date,
@ClaimID int,
@LocationID int)
returns table
as
return
with
max_cte(ReserveAmt, max_rn) as (
select ReserveAmt, row_number() over (partition by ClaimID, DamageID, LocationID order by ReserveDate desc)
from dbo.tTest
where ReserveDate<=@ReserveDate
and ClaimID=@ClaimID
and LocationID=@LocationID)
select sum(ReserveAmt) ReserveAccuracyAmt
from max_cte
where max_rn=1;
goQuery
;with unq_cte(ClaimID, LocationID, ReserveDate) as (
select distinct ClaimID, LocationID, ReserveDate
from dbo.tTest)
select uc.*, isnull(raa.ReserveAccuracyAmt, 0) ReserveAccuracyAmt
from unq_cte uc
outer apply dbo.func_reserve_accuracy_amount(uc.ReserveDate, uc.ClaimID, uc.LocationID) raa;Output
ClaimIDLocationIDReserveDateReserveAccuracyAmt
1999 2014-06-0936000.00
1999 2014-06-1946000.00
1999 2014-08-1955000.00Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
Thanks, this seems to work for me. I will see if DBA can create function on the database.
Scott
-
What you posted is by definition not a table at all! The table must have a key. You cannot embed spaces in the data element name in any of the ISO standards; you're already trying to format the display of your data which is never done in the database. Since identifiers are on a nominal scale, they can't be integers. What math are you going to do with them? There's no such thing as a generic sequence number in RDBMS; it would have to be some particular kind of sequence, like check or invoice numbers. It would also help if you knew that the ANSI ISO standards for SQL allow only the ISO date format and not your local dialect. We also have a DATE data type in Microsoft SQL Server today, so there's no reason to use the old proprietary Sybase datetime. It's also interesting that you're using the old Sybase syntax to build a table, and not the ANSI/ISO standard syntax
CREATE TABLE Claims
(claim_id CHAR(6) NOT NULL,
damage_id CHAR(6) NOT NULL,
location_id CHAR(8) NOT NULL,
foobar_seq INTEGER NOT NULL,
reserve_date DATE NOT NULL,
reserve_amt DECIMAL (18,2) NOT NULL
PRIMARY KEY (claim_id, damage_id, location_id, foobar_seq)
);
INSERT INTO Claims
VALUES
('668835', '631560', 36225627, 1, '2014-06-09', 20000.00),
('668835', '631560', 36225627, 2, '2014-06-19', 20000.00),
('668835', 631558, 36225627, 1, '2014-08-28', 16000.00);
>> What I need to do is create a new column called reserve_accuracy_amt for each row that will sum the reserve_amt for the max reserve date for each Claim ID, Damage ID, and Location ID that is <= the date for that row ( I think i'm saying that right). <<
Remember that people are working for you for free, so we really don't like to have to transcribe your pretty pictures and screen captures into real SQL. This is just plain rude.
But a better question is why do you want to create a new column? You can make a computed column interview and not materialize it if you have a good definition of a computation.
>> so in the example above, the first row has a reserve date of 2014-06-09 and there were no other rows for that group before that date so the new field [sic] should just contain 20000.00. <<
By definition, tables have no ordering to their rows. Can I assume this ordering within each grouping of (claim, damage, location) is imposed by what I'm calling your "foobar_seq" for lack of a better name?
Another question is, why is reserve_accuracy_amt an aggregate at the same level as the rest of the row? I don't think it is. Therefore, it ought to be in a separate table review and not put in the same table as its components.
Please post DDL and follow ANSI/ISO standards when asking for help.
- jcelko212 32090 wrote:
What you posted is by definition not a table at all! The table must have a key. You cannot embed spaces in the data element name in any of the ISO standards; you're already trying to format the display of your data which is never done in the database. Since identifiers are on a nominal scale, they can't be integers. What math are you going to do with them? There's no such thing as a generic sequence number in RDBMS; it would have to be some particular kind of sequence, like check or invoice numbers. It would also help if you knew that the ANSI ISO standards for SQL allow only the ISO date format and not your local dialect. We also have a DATE data type in Microsoft SQL Server today, so there's no reason to use the old proprietary Sybase datetime. It's also interesting that you're using the old Sybase syntax to build a table, and not the ANSI/ISO standard syntax
But a better question is why do you want to create a new column? You can make a computed column interview and not materialize it if you have a good definition of a computation.
Another question is, why is reserve_accuracy_amt an aggregate at the same level as the rest of the row? I don't think it is. Therefore, it ought to be in a separate table review and not put in the same table as its components.
First, jcelko212 32090 is correct about the dates and I should've commented on that. The format of the sample data ('06-09-2014') was successfully parsed but it's a nonstandard format it shouldn't have been repeated in my code but it was. For the record the only truly safe way to enter dates is CONVERT or CAST('20200101' as date). If it's safe to assume the default COLLATION (or many others) is being used then CAST('2020-01-01' as date) is equally legitimate imo. I'm going to update my answer and fix that.
"Since identifiers are on a nominal scale, they can't be integers. What math are you going to do with them? There's no such thing as a generic sequence number in RDBMS; it would have to be some particular kind of sequence, like check or invoice numbers. "
Why can't integers be used as the basis for a nominal scale? They can and they are all day everyday and it's an efficient storage model. I hope the physical properties of primary keys are not in question. Logically, the key should uniquely identify a row but it also should be "non decomposable" or atomic. Any sequence (which has the property of being ordered) or invoice number (which has some prescribed format) or anything with any additional property whatsoever other than uniquely identifying the row is a violation of the relational model. I believe Ted Codd used integer primary keys in all of his publications.
At this point I could launch into a long explanation of the IDENTITY() property and of SCOPE_IDENTITY() and STORED PROCEDURES and TRY/CATCH and how it's really a cohesive system where each part solves very real issues which would otherwise be tricky to deal with. From a SQL governing standards point of view there aren't rules governing Primary Keys and really there can't be because it's the intersection of the logical and physical model. It would be nice to side-step the issue by claiming vendor implementations should be ignored. I really don't have a choice because otherwise we would to invent something that works. If it makes sense to optimize a table for performance reasons by substituting a natural key for it's surrogate then I do it. SQL Server temporal tables have all but eliminated the necessity for this in my projects though.
So what is the alternate being proposed to the fully functional and really quite nice built-in key generator system? Unavoidably, it's a random number. This is the source of my scorn and the thing that makes be believe the onus is really upon the proponents of using random numbers as keys to explain why the heck that makes sense. Why does it makes sense? Maybe you could explain it. A primary key is OF COURSE a clustered index which means physically storing rows in an intentionally randomized ordering. Why?
In general regarding the purity of design of the various questions on internet Q&A forums I try not to be wound too tight. The name of the table in this thread is "test" which signals to me the real one is probably more complicated than I need to know about. For which I'm gratefully because boiling a question down to it's essential elements is a sublime skill. Otherwise this question had very good sample data provided and was followed up on with more detail several times and each time it helped get me closer to a working example. That's my goal is to provide working examples which people can extend.
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
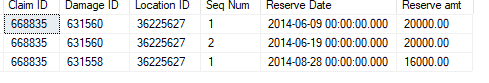

Viewing 10 posts - 1 through 10 (of 10 total)
You must be logged in to reply to this topic. Login to reply