2 new Column from string
-
I have string in table where column has the value 163 Bathroom {BATHROOM CLEANING}{2.5%}
I want to 2 new columns from this string
column1 BATHROOM CLEANING
column2 2.5%
The first curly bracket { is starting point for first new column and will end data closing curly } bracket and second curly bracket { for second new column and will end data closing curly } bracket
-
ah, the joys of would be JSON
SUBSTRING to the rescue
declare @wouldbejson NVARCHAR(200) = N'{BATHROOM CLEANING}{2.5%}'
Select charindex(N'{',@wouldbejson, 1) as firstoffset
, charindex(N'}',@wouldbejson,1) as firstEndOffset
, charindex(N'}{',@wouldbejson, 1) as Secondoffset
, charindex(N'}',@wouldbejson,charindex(N'}{',@wouldbejson, 1)+1) LastEndOffset
, SUBSTRING(@wouldbejson, charindex(N'{',@wouldbejson, 1)+1, charindex(N'}',@wouldbejson,1) -2) Firststring
, SUBSTRING(@wouldbejson
, charindex(N'}{',@wouldbejson, 1)+2
, charindex(N'}',@wouldbejson,charindex(N'}{',@wouldbejson, 1)+1) - (charindex(N'}{',@wouldbejson, 1)+2 )
) SecondStringThis is of course no solution for larger sets of columns, in that case I suggest you have a look into
Tally OH! An Improved SQL 8K “CSV Splitter” Function by Jeff Moden
Select *
from master.dbo.fn_DBA_Split8k(@wouldbejson,'{') -- ref: Tally OH! An Improved SQL 8K “CSV Splitter” FunctionJohan
Learn to play, play to learn !Dont drive faster than your guardian angel can fly ...
but keeping both feet on the ground wont get you anywhere :w00t:- How to post Performance Problems
- How to post data and code to get the best help- How to prevent a sore throat after hours of presenting ppt
press F1 for solution, press shift+F1 for urgent solution 😀
Who am I ? Sometimes this is me but most of the time this is me
-
Here is a quick sample that should get you over this hurdle
😎
USE TEEST;
GO
SET NOCOUNT ON;
GO
---------------------------------------------------------------------
-- EXAMPLE 1: SPLITTING A SINGLE STRING
---------------------------------------------------------------------
DECLARE @TSTR VARCHAR(100) = '163 Bathroom {BATHROOM CLEANING}{2.5%}';
DECLARE @STRNO INT = 1;
;WITH BASE_SPLIT(ItemNumber,Item,STRNO) AS
(
SELECT
X.ItemNumber
,X.Item
,@STRNO AS STRNO
FROM dbo.DelimitedSplit8K_LEAD(REPLACE(@TSTR,CHAR(125),''),CHAR(123)) AS X
)
,COLUMN_DATA AS
(
SELECT
BS.STRNO
,CASE WHEN BS.ItemNumber = 1 THEN BS.Item END AS COL_1
,CASE WHEN BS.ItemNumber = 2 THEN BS.Item END AS COL_2
,CASE WHEN BS.ItemNumber = 3 THEN BS.Item END AS COL_3
FROM BASE_SPLIT BS
)
SELECT
CD.STRNO
,MAX(CD.COL_1) AS COL1
,MAX(CD.COL_2) AS COL2
,MAX(CD.COL_3) AS COL3
FROM COLUMN_DATA CD
GROUP BY CD.STRNO;
GO
---------------------------------------------------------------------
-- EXAMPLE 2: SPLITTING A SET OF STRINGS
---------------------------------------------------------------------
;WITH SAMPLE_DATA(STRNO,TSTR)
AS
(
SELECT 1,'163 Bathroom {BATHROOM CLEANING}{2.5%}' UNION ALL
SELECT 2,'164 Bathroom {BATHROOM USAGE}{3.5%}' UNION ALL
SELECT 3,'165 Bathroom {BATHROOM ENTRY}{4.5%}'
)
,BASE_SPLIT(ItemNumber,Item,STRNO) AS
(
SELECT
X.ItemNumber
,X.Item
,SD.STRNO AS STRNO
FROM SAMPLE_DATA SD
CROSS APPLY dbo.DelimitedSplit8K_LEAD(REPLACE(SD.TSTR,CHAR(125),''),CHAR(123)) AS X
)
,COLUMN_DATA AS
(
SELECT
BS.STRNO
,CASE WHEN BS.ItemNumber = 1 THEN BS.Item END AS COL_1
,CASE WHEN BS.ItemNumber = 2 THEN BS.Item END AS COL_2
,CASE WHEN BS.ItemNumber = 3 THEN BS.Item END AS COL_3
FROM BASE_SPLIT BS
)
SELECT
CD.STRNO
,MAX(CD.COL_1) AS COL1
,MAX(CD.COL_2) AS COL2
,MAX(CD.COL_3) AS COL3
FROM COLUMN_DATA CD
GROUP BY CD.STRNO;
GO
---------------------------------------------------------------------
-- SOURCE 1: [dbo].[DelimitedSplit8K_LEAD]
-- REF: https://www.sqlservercentral.com/articles/reaping-the-benefits-of-the-window-functions-in-t-sql-2
-- IMPROVED VERSION OF Jeff Moden's outstanding DelimitedSplit8K
--
---------------------------------------------------------------------
CREATE OR ALTER FUNCTION [dbo].[DelimitedSplit8K_LEAD]
--===== Define I/O parameters
(@pString VARCHAR(8000), @pDelimiter CHAR(1))
RETURNS TABLE WITH SCHEMABINDING AS
RETURN
--===== "Inline" CTE Driven "Tally Table” produces values from 0 up to 10,000...
-- enough to cover VARCHAR(8000)
WITH E1(N) AS (
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), --10E+1 or 10 rows
E2(N) AS (SELECT 1 FROM E1 a, E1 b), --10E+2 or 100 rows
E4(N) AS (SELECT 1 FROM E2 a, E2 b), --10E+4 or 10,000 rows max
cteTally(N) AS (--==== This provides the "zero base" and limits the number of rows right up front
-- for both a performance gain and prevention of accidental "overruns"
SELECT 0 UNION ALL
SELECT TOP (DATALENGTH(ISNULL(@pString,1))) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4
),
cteStart(N1) AS (--==== This returns N+1 (starting position of each "element" just once for each delimiter)
SELECT t.N+1
FROM cteTally t
WHERE (SUBSTRING(@pString,t.N,1) = @pDelimiter OR t.N = 0)
)
--===== Do the actual split. The ISNULL/NULLIF combo handles the length for the final element when no delimiter is found.
SELECT ItemNumber = ROW_NUMBER() OVER(ORDER BY s.N1),
Item = SUBSTRING(@pString,s.N1,ISNULL(NULLIF((LEAD(s.N1,1,1) OVER (ORDER BY s.N1) - 1),0)-s.N1,8000))
FROM cteStart s
;
GOResult sets
STRNO COL1 COL2 COL3
----------- --------------- ------------------- ------
1 163 Bathroom BATHROOM CLEANING 2.5%
STRNO COL1 COL2 COL3
----------- --------------- ------------------- ------
1 163 Bathroom BATHROOM CLEANING 2.5%
2 164 Bathroom BATHROOM USAGE 3.5%
3 165 Bathroom BATHROOM ENTRY 4.5% -
;WITH cte_test_data AS (
SELECT CAST('163 Bathroom {BATHROOM CLEANING}{2.5%}' AS varchar(100)) AS string
)
SELECT
string AS original_string,
CASE WHEN middle_delimiter = 0 THEN ''
ELSE SUBSTRING(string, first_delimiter + 1, middle_delimiter - first_delimiter - 1) END AS string1,
CASE WHEN middle_delimiter = 0 THEN ''
ELSE SUBSTRING(string, middle_delimiter + 2, CHARINDEX('}', SUBSTRING(string, middle_delimiter + 2, 500)) - 1) END AS string2
FROM cte_test_data
CROSS APPLY (
SELECT CHARINDEX('{', string) AS first_delimiter, CHARINDEX('}{', string) AS middle_delimiter
) AS calc1SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Thank you every one it work the way you guys told me. Appreciate all your help.
-
I use a combo of CTE and XML to split the strings makes it super fast and easy.
DECLARE @DELIMITER VARCHAR(50)='|||'
;WITH CTE AS
(SELECT
S.NAME
,SOUCE=S.RAW_DATA
,XML=CAST('<M>' + REPLACE(S.RAW_DATA, @DELIMITER, '</M><M>') + '</M>' AS XML)
FROM ##SYS_INVENTORY AS S
WHERE
S.SERVER_NAME=@SERVER
AND S.CAT='LIST OS INFO'
AND S.NAME='MAC_INFO')
INSERT INTO #MACS
(INTERFACE_NAME
,MAC_ADDRESS
,INTERFACE_INDEX
,SPEED)
SELECT
INTERFACE_NAME= XML.value('/M[1]', 'VARCHAR(128)')
,MAC_ADDRESS= XML.value('/M[2]', 'VARCHAR(17)')
,INTERFACE_INDEX= XML.value('/M[3]', 'SMALLINT')
,SPEED= XML.value('/M[4]', 'BIGINT')
FROM CTE
WHERE
XML.value('/M[1]', 'VARCHAR(50)')<>''--BLANK NAMES ARE VMWARE INTERFACES AND ARE DUPLICATED ACCROSS ALL SYSTEMS ON THE HOST
AND XML.value('/M[2]', 'VARCHAR(50)') NOT IN ('00:05:9A:3C:7A:00','0A:00:27:00:00:09') - biggeek2003 wrote:
I use a combo of CTE and XML to split the strings makes it super fast and easy.
DECLARE @DELIMITER VARCHAR(50)='|||'
;WITH CTE AS
(SELECT
S.NAME
,SOUCE=S.RAW_DATA
,XML=CAST('<M>' + REPLACE(S.RAW_DATA, @DELIMITER, '</M><M>') + '</M>' AS XML)
FROM ##SYS_INVENTORY AS S
WHERE
S.SERVER_NAME=@SERVER
AND S.CAT='LIST OS INFO'
AND S.NAME='MAC_INFO')
INSERT INTO #MACS
(INTERFACE_NAME
,MAC_ADDRESS
,INTERFACE_INDEX
,SPEED)
SELECT
INTERFACE_NAME= XML.value('/M[1]', 'VARCHAR(128)')
,MAC_ADDRESS= XML.value('/M[2]', 'VARCHAR(17)')
,INTERFACE_INDEX= XML.value('/M[3]', 'SMALLINT')
,SPEED= XML.value('/M[4]', 'BIGINT')
FROM CTE
WHERE
XML.value('/M[1]', 'VARCHAR(50)')<>''--BLANK NAMES ARE VMWARE INTERFACES AND ARE DUPLICATED ACCROSS ALL SYSTEMS ON THE HOST
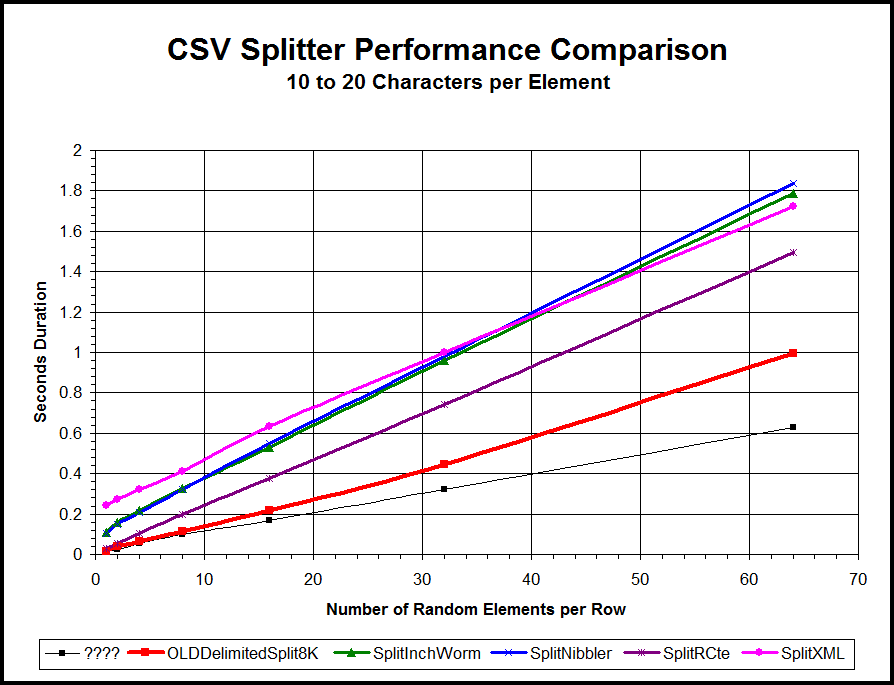
AND XML.value('/M[2]', 'VARCHAR(50)') NOT IN ('00:05:9A:3C:7A:00','0A:00:27:00:00:09')Easy... maybe. Super fast... probably not. It only looks that way if you're working with small numbers of rows. Have a look at the following chart and understand that the bright magenta line is the XML performance curve for such methods... especially those that need to have the XML delimiters added, like you did.

Please see the now ages old article for an explanation of what the ??? mark line is.
There's also a mod available to that code that makes it twice as fast. That mod can be found in "Part 1" of the article at the following link.
https://www.sqlservercentral.com/articles/reaping-the-benefits-of-the-window-functions-in-t-sql-2
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 7 posts - 1 through 7 (of 7 total)
You must be logged in to reply to this topic. Login to reply