

Most people
connect to a database, create tables, run update statements, tune queries, add
indexes, and never once think about the underlying data and log files that
support all these operations. Database administrators know the importance of
managing those files. There are a lot of questions and things to consider.
How many data files do I need?
How many log files do I need?
How should I configure autogrowth?
What size should the files be?
How do I reclaim space because my disk is full?
Why did I let my disk get full?
Why does everyone keep telling me I shouldn’t shrink my files?!
The list goes on
and on, but you get the idea. Today’s post isn’t going to focus on answering
all those questions. It is going to focus on some of the basics of interacting
with database files. I’m going to provide you with some of the common commands
and scenarios that I run into.
Disclaimer: This is not an endorsement for necessarily doing any of these things in a production environment. I spend a lot of time building and tearing down test environments for myself and my customers. I often have to move data files to a different disk to test configurations, grow and shrink the files for various load tests we are doing, compare and contrast virtual machine performance to PaaS performance, etc. Understand what you are doing, why you are doing it, if there are alternatives, weight the pros and cons of each approach, and test your code someplace that is NOT your production environment.
Gathering Data File Information
Before making any changes, it’s best to gather some information about our data files. This query will help you do that. It will provide files names, file locations, sizes, space used, etc.
USE [StackOverflow] GO SELECT DB_ID() AS DatabaseID, DB_NAME() AS DatabaseName, Name AS LogicalName, file_id AS FileID, type_desc AS FileType, physical_Name AS PhysicalName, size/128.0 AS FileSizeInMB, CAST(FILEPROPERTY(name, 'SpaceUsed') AS DECIMAL(38,2))/128.0 AS UsedSpaceInMB, ((CAST(FILEPROPERTY(name, 'SpaceUsed') AS DECIMAL(38,2)))/(size)) * 100 AS PercentUsed, size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS DECIMAL(38,2))/128.0 AS AvailableSpaceInMB, ((size - CAST(FILEPROPERTY(name, 'SpaceUsed') AS DECIMAL(38,2)))/(size)) * 100 AS PercentAvailable, CASE WHEN max_size = -1 THEN 'Unrestricted' ELSE CONVERT(VARCHAR, max_size/128) END AS MaxSizeInMB, CASE WHEN is_percent_growth = 1 THEN CONVERT(VARCHAR, growth) + ' %' ELSE CONVERT(VARCHAR, growth/128) + ' MB' END AS GrowthRate, is_read_only AS FileIsReadOnly FROM sys.database_files
Add a Additional Data File
There are legitimate reasons for creating more than one data file for a database. Sometimes in my personal test environment it’s just easier for me to add a new drive to my VM rather than going through the process to expand the disk. That happened the other day when I was testing some scripts for loading the StackOverflow database.
USE [master] GO ALTER DATABASE [StackOverflow] ADD FILE ( NAME = N'StackOverflow_Data02', FILENAME = N'U:SQLStackOverflow_Data02.ndf', SIZE = 90 GB, FILEGROWTH = 5 GB ) TO FILEGROUP [PRIMARY] GO
Here we specify the database that the file will be added to, the logical and physical name of the file, and some sizing information.
Move a Data File
We figure out that we are out of space on the S: drive, so we create a new data file on the T: drive. That’s all well and good, but what about when we need to move the existing files over to a new drive? How do we accomplish that? This part is a multi-step process that is going to require a little bit of downtime. If you go back to the data file information query, you’ll be able to see the current physical location of the files. Let’s assume for this example that we are moving the file over to the U: drive.
ALTER DATABASE [StackOverflow] MODIFY FILE ( NAME = 'StackOverflow_Data01', FILENAME = 'U:SQLStackOverflow_Data01.mdf' ) GO
A message will be displayed noting that “The file “StackOverflow_Data01” has been modified in the system catalog. The new path will be used the next time the database is started.“
If you run the database file information query, you will now notice the file reference is on the U: drive. However, the file has not actually been moved. As the message points out, the new path won’t be used until the database is restarted. To do this we will want to follow a simple procedure:
- Take the database offline.
- Manually move the physical file to the new location (rename if that was also part of the change).
- Bring the database back online.
You will need to make sure the SQL Server service account has access to this new location or the database will thrown an error when coming online that the file cannot be accessed or that the file is read only.
Removing a Data File
At some point you will need to remove a data file. It’s a very simple operation, just make sure that this isn’t going to cause any data loss. Be sure to empty the file first (more on that later in this post) to ensure it is void of user data. An error will be thrown if the file does contain user data (aka, it must be empty), but it’s always better to check this and verify before running the command otherwise you may end up doing an unscheduled test of your disaster recovery procedures.
USE [master] GO ALTER DATABASE [StackOverflow] REMOVE FILE [StackOverflow_DataTemp] GO
Double check the file system, but the physical file should be removed automatically. Cleanup manually if necessary.
Expand an Existing Data File
A quick search online will yield results from you should never rely on autogrow and you should only autogrow. No matter which crowd you fall into (there are actually shades of gray on this particular topic) you will one day run into a situation where you want to grow an existing file. If you know you’re about to load a big test data set, why not just go ahead and grow the file so you don’t have to wait.
USE [master] GO ALTER DATABASE [StackOverflow] MODIFY FILE ( NAME = 'StackOverflow_Data01', SIZE = 90 GB, FILEGROWTH = 5 GB ) GO
The FILEGROWTH
setting is optional. If you don’t need to make a change, it’s perfectly ok to
leave that out.
Reduce the Size of a File
I’m not going to rehash this here. Do a search for shrinking SQL Server data and log files, read up, then come back to determine if you should read this section or pretend it doesn’t exist.
USE [StackOverflow]
GO
DBCC SHRINKFILE ('StackOverflow')
GO
DBCC SHRINKFILE ('StackOverflow', 2048)
GOThe name
specified in this command is actually the logical name of the file. That can be
found in the query at the top of this post or by looking at the name field in
sys.database_files or sys.master_files. It is also possible to specify the File
ID rather than the file name.
The first version
of the command will shrink the file as much as SQL Server is able to. The
second one adds an extra parameter, the file’s target size in MB. You will
never get a file to go all the way to zero, but specifying a number here will
allow you to shrink the file, but not necessarily take it down to its smallest
possible size. If the file is currently 10GB, but you know there is only 1GB of
data and you want to keeps some buffer space in there you can shrink the file
down to something more reasonable like 3GB
Remove User Data From a File
This was a bit of a newer scenario for me recently. I was done creating a sample database, StackOverflow, and because of my lazy “I’ll just add a new file on a new disk” thing from the add an additional data disk section above, I had one file that was 128GB and another one that was about 350GB. Well, I wanted to package everything up nicely and get a couple of data files that were all the same size. Part of that was redistributing the data from the two data files, across 4 equally sized data files. The only way to get the data out of the file is to empty the file.
DBCC SHRINKFILE('StackOverflow', EMPTYFILE)Much like the
previous example, we are using the SHRINKFILE command. This is going to remove
all the user data from the file and distribute it to the other files in the
same filegroup. When you run this command, no data can be added to the file
until it has been modified.
If the desire is
to even out the data files, as was my goal, I have some code included at the
very bottom of this post.
Changing Autogrow Settings
Here’s the
situation. The database has a single 100 MB data file and it is half full (50
MB, I’ll pause while you double check my math). You load a file that is going
to take up 75 MB of space in the data file. What happens when the 26th MB of data starts to load into the
database? Enter Autogrow.
There are two
autogrow options: fixed amount in MB and percentage.
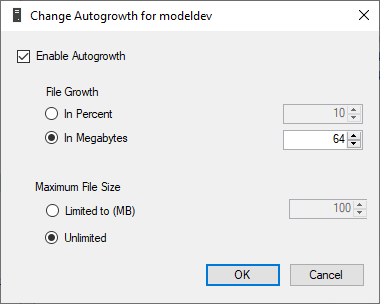
The default settings on SQL Server for autogrowth is 1MB for data files and 10% for log files. Those are generally terrible settings. Each time a file grows the system has to wait for the file to grow before it can continue the operation. That means for this hypothetical data set, the data file will need to grow (read: stop and wait) 25 times. Those little growing periods all add up. So it’s a good idea to change the autogrowth settings on your databases to something more reasonable for your workload. At the very least you should make sure none of your databases are set to grow by a percentage.
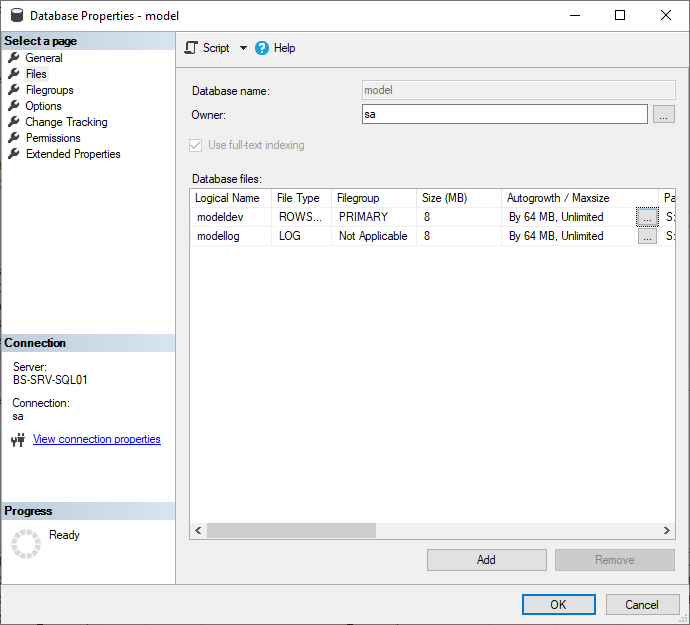
How do we check
the autogrowth setting on our databases?
First thing to note is this setting is on the individual file level, so our query will need to look at all the files, not just the database level.
SELECT DB_NAME(database_id) AS DatabaseName, name AS LogicalName, physical_name AS PhysicalName, is_percent_growth AS IsPercentGrowth, growth AS GrowthIncrement, CASE WHEN is_percent_growth = 1 THEN CONVERT(VARCHAR, growth) + ' %' ELSE CONVERT(VARCHAR, growth/128) + ' MB' END AS GrowthRate FROM sys.master_files
Now that we know which files are set to grow by a percentage we can make the change over to a fixed amount in MB. We can also modify the growth of fixed amounts if they are at the default of 1MB and we want a more reasonable 512MB, for instance. The system DMVs show the value in MB but the modify database command will accept GB values and convert them. I’m not sure what version of SQL that behavior started, but the older versions of SQL (i.e. SQL 2008) I believe require the parameter value to be in MB if my memory of that is correct.
USE [master] GO ALTER DATABASE [StackOverflow] MODIFY FILE ( NAME = 'StackOverflow_Data01', FILEGROWTH = 1 GB ) GO
Redistribute Data Across All Data Files
I wanted to take my demo database, StackOverflow, and distribute the data across 4 evenly sized files. The basic way to do this was:
- Create a temporary data file.
- Move all the data to the temporary data file.
- Create the 4 evenly sized data files (an .mdf exists, so I only really created 3 .ndf files).
- Resize the original .mdf if necessary.
- Distribute the data from the temporary data file to the 4 data files.
- Drop the temporary data file.
Here is the code that I used to do all this. At the end rather than a single, large file, I now have 4 files each at 90GB in size.
--Add the the single, large temporary data file.
USE [master]
GO
ALTER DATABASE [StackOverflow] ADD FILE ( NAME = N'StackOverflow_DataTemp', FILENAME = N'U:SQLStackOverflow_DataTemp.ndf' , SIZE = 400 GB , FILEGROWTH = 5 GB ) TO FILEGROUP [PRIMARY]
GO
--Empty the existing, primary data file into the temporary data file.
USE StackOverflow
GO
DBCC SHRINKFILE ('StackOverflow_Data01', EMPTYFILE)
GO
--Shrink the primary data file down now that it is empty.
DBCC SHRINKFILE ('StackOverflow_Data01', 0)
GO
--Grow the primary data file back out.
ALTER DATABASE StackOverflow
MODIFY FILE
(
NAME = 'StackOverflow_Data01',
SIZE = 90 GB,
FILEGROWTH = 5 GB
)
GO
--Add the three additional data files.
USE [master]
GO
ALTER DATABASE [StackOverflow] ADD FILE ( NAME = N'StackOverflow_Data02', FILENAME = N'U:SQLStackOverflow_Data02.ndf' , SIZE = 90 GB , FILEGROWTH = 5 GB ) TO FILEGROUP [PRIMARY]
GO
ALTER DATABASE [StackOverflow] ADD FILE ( NAME = N'StackOverflow_Data03', FILENAME = N'U:SQLStackOverflow_Data03.ndf' , SIZE = 90 GB , FILEGROWTH = 5 GB ) TO FILEGROUP [PRIMARY]
GO
ALTER DATABASE [StackOverflow] ADD FILE ( NAME = N'StackOverflow_Data04', FILENAME = N'U:SQLStackOverflow_Data04.ndf' , SIZE = 90 GB , FILEGROWTH = 5 GB ) TO FILEGROUP [PRIMARY]
GO
--Empty the temporary data file into the four final data files.
USE StackOverflow
GO
DBCC SHRINKFILE ('StackOverflow_DataTemp', EMPTYFILE)
GO
--Drop the temporary data file from the database.
ALTER DATABASE [StackOverflow] REMOVE FILE [StackOverflow_DataTemp]
GOAll of these commands have a variety of parameters and options to go along with them that are not covered here. As always, be sure to test before running any code in production. Check the official documentation for additional options.
