

I answered an interesting question on SE today (ever notice how many posts come from stuff I read on forums?) and I was pleased with how the answer turned out. In particular one piece (expanded a bit) seemed like it would make a good blog post.
To start with here is the question.
The questioners problem appeared to be a misunderstanding of how you pick which columns are returned by a query.
A basic SELECT statement looks something like this:
SELECT FieldList
FROM TableOne
INNER JOIN TableTwo
ON [JoinCondition between TableOne and TableTwo]
WHERE [Conditions that restrict returned rows]The FieldList is where you tell SQL what columns you want back from the query. From least selective to most selective you can have the following things in the FieldList.
- * – return every column from every table in the FROM clause (that includes INNER/OUTER/CROSS/etc JOINs)
- TableName.* – Return every column from TableName.
- One or more of the following: TableName.ColumnName or ColumnName It’s generally considered a good idea to include the TableName but it isn’t necessary.
Typing a * sounds a lot easier than actually listing all of the columns you need. However is that really a good idea? You’ll hear lots of people saying it isn’t, but why?
Well there are several reasons. Primarily:
- Performance : By requesting only the columns you need:
- You reduce the amount of data that has to go across the wire.
- You allow the optimizer to pick more appropriate indexes (a covering index for example)
- Code stability : When the schema of the tables involved changes
- Your data may move around unexpectedly.
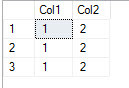
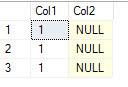
-- Create test table & load data CREATE TABLE ChangingTable (Col1 int, Col2 int); GO INSERT INTO ChangingTable VALUES (1,2), (1,2), (1,2); GO -- Create a view using the dread * CREATE VIEW vw_ChangingTable AS SELECT * FROM ChangingTable; GO -- Before query SELECT * FROM vw_ChangingTable; GO

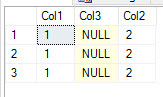
-- Script to add a column in the middle of the other columns EXEC sp_rename 'ChangingTable','tmpChangingTable'; CREATE TABLE ChangingTable (Col1 int, Col3 int, Col2 int); INSERT INTO ChangingTable (Col1, Col2) SELECT Col1, Col2 FROM tmpChangingTable; DROP TABLE tmpChangingTable; GO -- After query SELECT * FROM vw_ChangingTable; GO
Oops .. that doesn’t look right. Let’s make sure the table looks right.
SELECT * FROM ChangingTable; GO
Well at least the table is correct. Although your application is libel to be a bit unhappy.
- Your code may break.
-- Create test tables CREATE TABLE ChangingTable (Col1 int, Col2 int); CREATE TABLE ChangingTable2 (Col1 int, Col2 int); GO -- Before code run INSERT INTO ChangingTable2 SELECT * FROM ChangingTable; GO
The insert succeeds (of course).
-- Change the table ALTER TABLE ChangingTable ADD Col3 int; GO -- After code run INSERT INTO ChangingTable2 SELECT * FROM ChangingTable;
Msg 213, Level 16, State 1, Line 54
Column name or number of supplied values does not match table definition.
And with no changes to the code, it now fails.
- Your data may move around unexpectedly.
All that said there are some good times to use *s. Specifically quickie ad-hoc queries in a query window where you aren’t returning a large number of rows. Otherwise it’s generally safer to list out the columns you need rather than use a *.
Filed under: Microsoft SQL Server, SQLServerPedia Syndication, T-SQL Tagged: microsoft sql server, T-SQL 






![]()
