(If you’re reading this on SQL Server Central, please click here to see the “Featured Image” which will help explain the “Duck” vs “Rabbit” titles of this and the previous posts)
Welcome back! Previously, on “Who’s Collation is it Anyway?”, due to statements made in the Microsoft documentation for “Search Conditions” related to Code Page conversions, we started looking at what happens when VARCHAR data (mainly string literals that are not prefixed with a capital-“N”) is used in a Database where the default Collation specifies a Code Page that does not contain one or more of the characters in the string. We saw that whether we were doing a simple SELECT of the literal, or comparing it to VARCHAR or NVARCHAR columns, or even concatenating it with VARCHAR or NVARCHAR columns that had a Collation that specified a Code Page that did support the character, the character was always transformed in the same way. The character was either translated into an approximate character in the new Code Page, if a “Best Fit” mapping existed, or it was translated into the default replacement character of “?”. Either way, the character was transformed when the query was parsed, using the Code Page specified by the Database’s default Collation. The Collation of the referenced column never had any effect as the transformed character was already available in the new Code Page.
But, what happens if we reverse the situation. If the character in a string literal that is not prefixed with a capital-“N” is available in the Code Page specified by the Database’s default Collation, then it won’t be transformed when the query is parsed. At that point the character will still be in the query when the query is compiled, and the Code Page of that string literal might need to be converted if the string is used in a predicate (i.e. filter condition) or expression that references a column having a different Collation that specifies a different Code Page.
This is what the documentation was referring to, right? Let’s find out…
Database Collation = Korean_100_BIN2
At the end of the previous post, the Database was using a “Hebrew” Collation. Starting from there, let’s change the Database’s Collation to Korean_100_BIN2 and see what is affected:
USE [master]; ALTER DATABASE [WhichCollation] COLLATE Korean_100_BIN2; USE [WhichCollation];
When we execute:
EXEC dbo.CheckConversions;
the following is returned:

This is slightly different than the previous two tests. In both of the other tests, the character that ‘₂’ matched was the same across all rows and columns: it was either only “2” or only “?”. This time, however, we see “Subscript 2” matching something different in each row:
- it matches everything in the first row (the row in which we inserted “Subscript 2”):
- it matches the Latin1 VARCHAR column only in the “2” row
- it matches the Hebrew VARCHAR column only in the “?” row
The reason for this behavior is that there are actually two separate operations going on here:
- First, a string literal that is not prefixed with a capital-“N” is made to fit into the Code Page specified by the Database’s default Collation. The same is true for VARCHAR input parameters and variables.
- Second, if the literal is used along with another Collation that has a different Code Page (either a column or when the COLLATE keyword is used), then the literal will be made to fit into the Code Page specified by the new Collation (unless, of course, the new Collation just happens to use the same Code Page).
Any string literal, input parameter, or variable can go through any combination of one or both of those operations. The first two tests (i.e. the previous post) showed only the first step, which only uses the Database’s Collation. The second step, which only uses the Collation of the column or COLLATE keyword, never happened in either of those tests because the character that “Subscript 2” translated into – “2” and “?”, respectively – are available in the other Code Pages that are being tested.
But here, in this test, we are seeing the effect of only the second step. The first step never happened because “Subscript 2” is a valid character in the Code Page used by the Korean Collations. Hence, the character isn’t being transformed before the query executes, as was the case previously, but instead it is being transformed as it is being used with each column that has a different Code Page: the Latin1 and Hebrew VARCHAR columns. The NVARCHAR columns are a non-issue because in those cases, it is the datatype that changes, VARCHAR to NVARCHAR, instead of the Code Page. And since all characters are represented in Unicode (at least in terms of the Code Pages used in SQL Server), there should be no character transformations going from VARCHAR to NVARCHAR.
In the “Bonus Round” we will take a quick look at a scenario in which both steps / operations occur. For now, if we test the string literal by itself:
SELECT '₂'; -- ₂ (only in Code Page 949) SELECT '₂' COLLATE Hebrew_100_BIN2; -- ?
we get the “Subscript 2” character in the first query since it is available in Code Page 949, but we get the default replacement character in the second query because the COLLATE keyword is applied after the literal has been parsed, and “Subscript 2” is not in Code Page 1255.
The queries, along with their results, shown above also indicate that the translation happens after the query is parsed. BUT, the documentation states “when an nvarchar datatype was referenced”, and yet there is no other datatype in the two queries above. Ok, fine. Let’s test what happens when the reference is in the context of string concatenation. We will concatenate with both Hebrew columns since Code Page 1255 does not have the “Subscript 2” character. The resulting Collation should be the column’s Collation since string literals are coercable.
-- DROP TABLE #ConversionTest2;
SELECT [Hebrew_8bit] + '₂' AS [ShouldBeVarcharHebrew],
[Hebrew_Unicode] + '₂' AS [ShouldBeNVarcharHebrew]
INTO #ConversionTest2
FROM dbo.WhichCollationIsIt;
SELECT * FROM #ConversionTest2;
That returns the following:
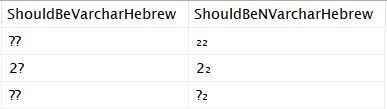
The referenced column being of a Code Page that does not contain the character did not cause a transformation when the datatype was NVARCHAR. But, when the datatype was VARCHAR, then there was a transformation. This behavior shows, again, that the string literal is translated:
- after the query is parsed,
- into the Code Page specified by the column’s Collation, and
- only when the column’s datatype is VARCHAR
Not convinced that the resulting Collation is the column’s Collation? That’s easy to check (and is why the query creates a table to store the results in):
EXEC tempdb..sp_help N'#ConversionTest2';
returns the following:
| Column_name | Type | Collation |
|---|---|---|
| ShouldBeVarcharHebrew | varchar | Hebrew_100_BIN2 |
| ShouldBeNVarcharHebrew | nvarchar | Hebrew_100_BIN2 |
What Are These Tests Showing?
Just in case you were wondering: No, the test directly above test does not prove the documentation (as quoted at the top of Part A) correct. Yes, the documentation did state that characters would be converted to the Code Page specified by the Collation of the Database or Column, which does appear to be what is going on here. But, the differences are:
- The documentation states that the transformation happens if you reference a Unicode datatype, but what we just saw in the most recent test is the exact opposite:
- only the NVARCHAR columns of the “Subscript 2” row match because they are still the “Subscript 2” character, while the NVARCHAR columns of the other two rows do not match due to being either “2” or “?”.
- transformation did occur in the Latin1 and Hebrew VARCHAR columns, which is how it matched both rows with “2” in the Latin1 column and both rows with “?” in the Hebrew column.
- In the scenario involving another column where it would help to prefix the string literal with a capital-“N” (i.e. a VARCHAR column using a Collation that specifies a different Code Page than the Database’s Code Page), the Collation of the Database is not used for the transformation; it is only the referenced column’s Collation. The assumption here is that the string literal without the capital-“N” is being used in a Database where the Collation specifies a Code Page that has all of the characters.
- In the scenarios where the Database’s Collation, via its specified Code Page, did transform a string literal that was not prefixed with a capital-“N” (the two tests in the previous post), there would have already been unintended behavior no matter how the string literal was used.
Bonus Round
While the main points have been proven, here are two more fun tests that help paint a more complete picture:
Which Database is Current / Active?
I mentioned towards the beginning of the previous post that the current Database was rather important most of the time. Since the “current” Database’s Collation is used when parsing string literals, it is important to understand which Database that would be.
The “current” Database for ad hoc queries is the Database that was specified upon connecting to SQL Server (or the Login’s default Database if no Database was specified when connecting), or the Database that was most recently switched to via the USE statement. The “current” Database for compiled code (Stored Procedures, Functions, Triggers, Dynamic SQL within those objects, and Views) is the Database in which the object exists.
We can test this by switching to another Database that has a different Collation. I am using SQL Server Express LocalDB, and that always has a Server- / Instance- level Collation of SQL_Latin1_General_CP1_CI_AS (unfortunately!). So we should be able to use any of the system Databases to get a Latin1_General Collation, and the test Database should still be set to the Korean Collation.
USE [tempdb]; SELECT DATABASEPROPERTYEX(DB_NAME(), 'collation'), '₂'; -- SQL_Latin1_General_CP1_CI_AS 2
We can see above that the “current” Database’s Collation, and its behavior, is what we expect (as we have seen it in the first set of tests).
Execute the following, which is the query from the test Stored Procedure (which has only been modified to fully qualify the Table name), and the test Stored Procedure itself:
SELECT -- "Uni" == Unicode
[Latin1_8bit] AS [Latin1],
[Hebrew_8bit] AS [Hebrew],
[Korean_8bit] AS [Korean],
N'█' AS [█], -- visual group separator ( Full Block U+2588 )
IIF([Latin1_8bit] = '₂', 'Match', '') AS [Latin1],
IIF([Latin1_Unicode] = '₂', 'Match', '') AS [Latin1_Uni],
IIF([Hebrew_8bit] = '₂', 'Match', '') AS [Hebrew],
IIF([Hebrew_Unicode] = '₂', 'Match', '') AS [Hebrew_Uni],
IIF([Korean_8bit] = '₂', 'Match', '') AS [Korean],
IIF([Korean_Unicode] = '₂', 'Match', '') AS [Korean_Uni]
FROM WhichCollation.dbo.WhichCollationIsIt;
and it returns:

Those results match the results of the “Database Collation = Latin1_General_100_BIN2” test (first test in previous post) because the Collation of the current / active Database, [tempdb], is a Latin1 Collation.
Now execute:
EXEC WhichCollation.dbo.CheckConversions;
That returns:
The result set here matches the one shown in the “Database Collation = Korean_100_BIN2” test (first test of this post) because a Stored Procedure runs in the context of the Database in which it exists, and that Database should still be using the Korean Collation.
Both Transformations
Ok, final test. Let’s go back to the test Database and look at how the Japanese Collations handle both “Subscript 2” and “Superscript 2”.
USE [WhichCollation]; SELECT DATABASEPROPERTYEX(DB_NAME(), 'collation') AS [DB_Collation], '₂' COLLATE Japanese_XJIS_100_CI_AS AS [Subscript_2], '²' COLLATE Japanese_XJIS_100_CI_AS AS [Superscript_2];
That returns a result set of:
| DB_Collation | Subscript_2 | Superscript_2 |
|---|---|---|
| Korean_100_BIN2 | ? | 2 |
Meaning, neither “Subscript 2” nor “Superscript 2” is available in the Code Page specified by the Japanese Collations, but at least “Superscript 2” has a “Best Fit” mapping to a regular “2”.
Now, let’s change the test Database’s Collation to one that specifies Code Page 850 (only available in the old, SQL Server Collations). Then we can run that same SELECT statement.
USE [master]; ALTER DATABASE [WhichCollation] COLLATE SQL_Latin1_General_CP850_CI_AS; USE [WhichCollation]; SELECT DATABASEPROPERTYEX(DB_NAME(), 'collation') AS [DB_Collation], '₂' COLLATE Japanese_XJIS_100_CI_AS AS [Subscript_2], '²' COLLATE Japanese_XJIS_100_CI_AS AS [Superscript_2];
That returns a result set of:
| DB_Collation | Subscript_2 | Superscript_2 |
|---|---|---|
| SQL_Latin1_General_CP850_CI_AS | 2 | 2 |
The “Superscript 2” translation is the same, but now “Subscript 2” also translated to a regular “2”. How? Well, this is an example of both transformation steps happening:
- Character is translated from “Subscript 2” into “Superscript 2” when the query is parsed since Code Page 850, the Database’s Collation’s Code Page, has a “Best Fit” mapping for “Subscript 2”
- Character is translated from “Superscript 2” into a regular “2” when the COLLATE keyword is applied since Code Page 932, used with the Japanese Collations, has a “Best Fit” mapping for “Superscript 2”.
Conclusion

What it all comes down to is this:
- String literals / constants (as well as variables) use the default Collation for the current / active Database because they have their type and value determined when the query is parsed. But, they are coercable, meaning that after they have been initially determined, they can automatically convert to a different Collation when used in a predicate or expression containing a column, or when the COLLATE keyword is used.
When strings (literals, variables, columns, expressions, etc) convert from NVARCHAR to VARCHAR, OR from VARCHAR to VARCHAR of differing Code Pages, no characters are ever fully removed. For each character, it will either:
- stay the same if the same character is available in the Code Page specified by the Collation being used, or
- translate into an approximation of the original character if the Code Page has a “Best Fit” mapping and the original character is listed in that mapping, or
- translate into the default replacement character — “?” — if neither of the above applies to that character
- Make life easy on yourself and just prefix, with a capital-“N”, ALL strings that come into ANY contact with NVARCHAR data, including:
- literals, variables, columns, expressions, etc.
- any “name” of any item that exists within SQL Server (Object, Database, Schema, Login, Index, etc..). Most [name] columns use the [sysname] datatype, which is an alias for NVARCHAR(128).
- any Dynamic SQL
- Do not prefix VARCHAR string literals with a capital-“N” if it is not necessary. Doing so will convert the entire expression to NVARCHAR which could adversely affect performance. Only do this if:
- any other part of the expression is already NVARCHAR
- it is being compared to NVARCHAR
- it is being used with VARCHAR that has potential to convert to an incompatible Code Page. Simply using COLLATE to specify a different sensitivity for Case / Accent / Kana / Width / Variation Selector (new in SQL Server 2017) but keeping the culture the same (i.e. “Latin1_General”, “French”, etc) won’t change Code Pages.
I will submit a correction for the documentation.
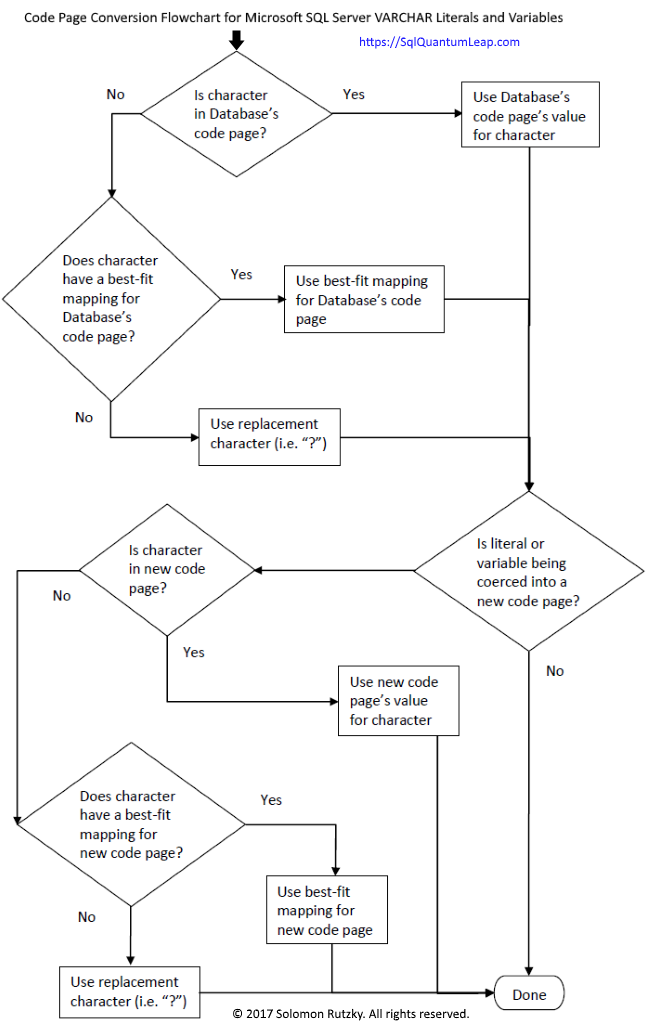
Flowchart
Just in case this process is not clear, I came up with the following chart to provide a visual representation of what is going on here: