

Lambda architecture is a data-processing architecture designed to handle massive quantities of data (i.e. “Big Data”) by using both batch-processing and stream-processing methods. This idea is to balance latency, throughput, scaling, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data. The two view outputs may be joined before presentation.
This allows for a way to bridge the gap between the historical single version of the truth and the highly sought after “I want it now” real-time solution. By combining traditional batch processing systems with stream consumption tools the needs of both can be achieved with one solution.
The high-level overview of the Lambda architecture is expressed here:
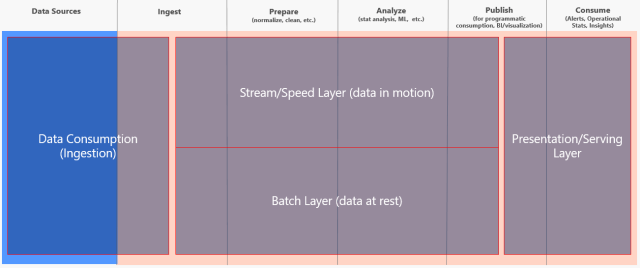
A brief explanation of each layer:
Data Consumption: This is where you will import the data from all the various source systems, some of which may be streaming the data. Others may only provide data once a day.
Stream Layer: It provides for incremental updating, making it the more complex layer. It trades accuracy for low latency, looking at only recent data. Data in here may be only seconds behind, but the trade-off is the data may not be clean.
Batch Layer: It looks at all the data at once and eventually corrects the data in the stream layer. It is the single version of the truth, the trusted layer, where there is usually lots of ETL and a traditional data warehouse. This layer is built using a predefined schedule, usually once or twice a day, including importing the data currently stored in the stream layer.
Presentation Layer: Think of it as the mediator, as it accepts queries and decides when to use the batch layer and when to use the speed layer. Its preference would be the batch layer as that has the trusted data, but if you ask it for up-to-the-second data, it will pull from the stream layer. So it’s a balance of retrieving what we trust versus what we want right now.
A lambda architecture solution using Azure tools might look like this, using a vehicle with IoT sensors as an example:
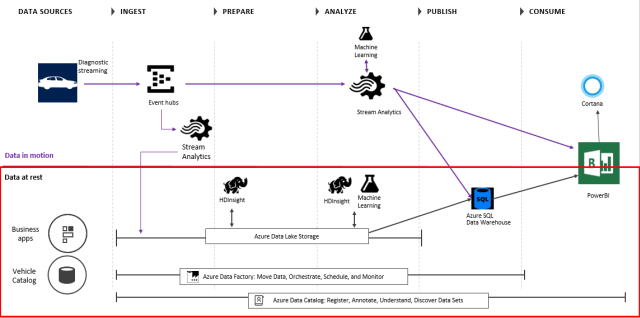
In the above diagram, Event Hubs is used to ingest millions of events in real-time. Stream Analytics is used for 1) real-time aggregations on data and 2) spool data into long-term storage (SQL Data Warehouse) for batch. Machine Learning is used in real-time for anomaly detection on tire pressure, oil level, engine temp, etc, to predict vehicles requiring maintenance. The data in the Azure Data Lake Storage is used for rich analytics using HDInsight and Machine Learning, orchestrated by the Azure Data Factory (for e.g. aggressive driving analysis over past year). Power BI and Cortana are used for the presentation layer, and the Azure Data Catalog is the metadata repository for all the data sets.
Using Hadoop technologies might provide a solution that looks like this:
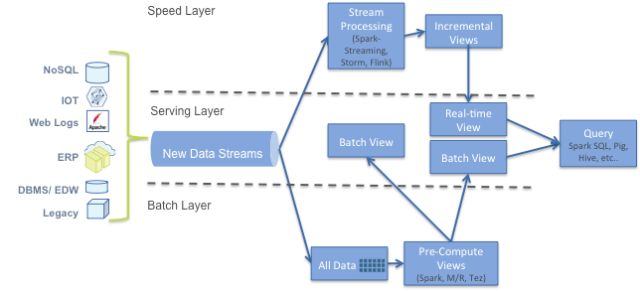
Be aware this is a complicated architecture. It will need a number of hardware resources and difference code bases for each layer, with each possibly using different technologies/tools. The complexity of the code can be 3-4 times a traditional data warehouse architecture. So you will have to weigh the costs versus the benefit of being able to use data slightly newer than a standard data warehouse solution.
More info:
The Lambda architecture: principles for architecting realtime Big Data systems
Questioning the Lambda Architecture
Lambda Architecture: Low Latency Data in a Batch Processing World
Lambda Architecture for the DWH
Lambda Architecture: Design Simpler, Resilient, Maintainable and Scalable Big Data Solutions
The Lambda Architecture and Big Data Quality

![]()
