

This post is about the importance of a right index to a query. The following simple query was considered.
SELECT
[GroupBy1].[A1] AS [C1]
FROM ( SELECT
MAX([Extent1].[CreatedDate]) AS [A1]
FROM [dbo].[GeoIP2Location] AS [Extent1] WITH (NOLOCK)
) AS [GroupBy1]Even simple, this query was causing troubles on our production systems. The query is generated from .NET Entity Framework. A simple nonclustered index was created on the CreatedDate column for the GeoIP2Location table.
Next figure shows two query plans: before and after the creation of the index.

Figure 1. Query plans comparison before and after the creation of the right index for the query
In the first case the query plan uses the clustered index. Query is covered by index.
In the second case the query plan uses the newly created index. Query is covered by index.
The right index was not existing for the query.
The difference is obvious:
Estimated Subtree Cost: 219.721 vs 0.0032843 (Figure 1)
DesiredMemoery: 200 vs 0 (Figure 1)
The query executes perfectly fast in the both cases. The difference is about the CPU usage. CPU before (Figure 2):
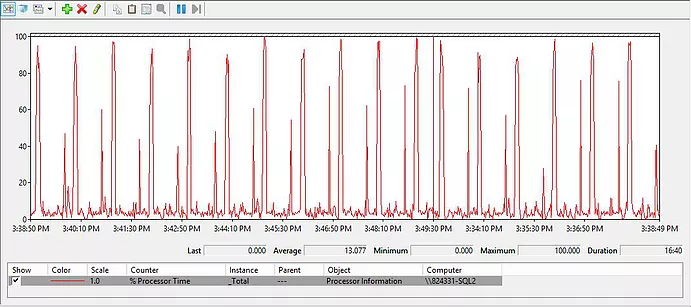
Figure 2. CPU before the creation of the index for the query
CPU after (Figure 3):
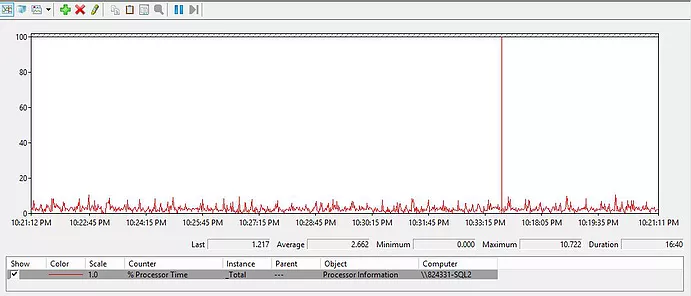
Figure 3. CPU before the creation of the index for the query
Note: This was a case when the optimisation was done by maintaining the database with an addition of an index.
Addition of indexes must be done carefully because it can sometimes impose negative effect.
However, do know that the solution to a poor query performance is not always resolved by addition of indexes.
