

A while ago now I was running some Performance Tuning workshops and was asked how you can find out which Statistics objects SQL Server has used in the generation of an execution plan (for cardinality estimation). My answer was: “As far as I know – you can’t.”
Some time later I came across the undocumented traceflag 8666 which is used to save internal debugging info into the plan XML – including details of the Statistics objects used. Winner!
There are actually a few other trace flags that do similar things but this seems the simplest and the one that works across the most versions of SQL Server. It looks like it was introduced in SQL 2008 and works on all versions up to and including SQL 2016 – but it doesn’t work on SQL 2005.
Note that this technique only works for plans generated once the trace flag is on, so you can’t view the additional information for existing plans in your cache:
Here’s a quick example using it against the AdventureWorks2012 database. You need to make sure you’ve selected the option to show the actual plan, then run the query as below:
--Turn the trace flag on DBCC traceon (8666); --Run the query SELECT * FROM Person.Person WHERE LastName LIKE 'Smith%'; --Turn the trace flag off again DBCC traceoff (8666);
This query produces the following plan:
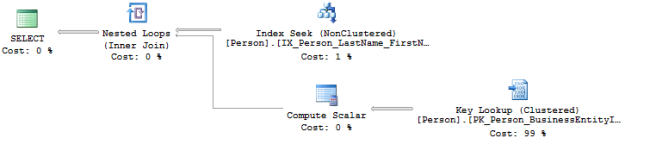
If you right-click over the SELECT operator and select properties you see the following:
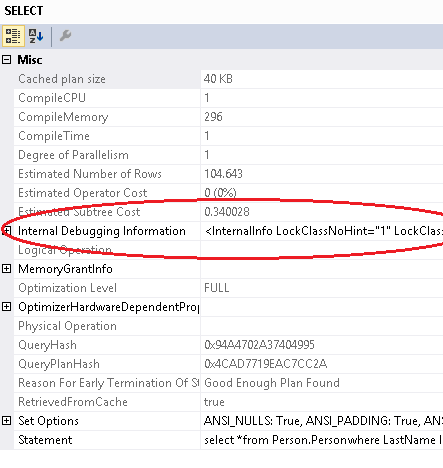
You’ll notice an extra field “Internal Debugging Information” which contains a bunch of unformatted XML. Rather than grabbing that string and formatting it to make it readable, you can right-click back on the plan itself and select “Show Execution Plan XML…” to view the same information in a more friendly format.
If you scroll down through the XML generated you will get to the following section:
<ModTrackingInfo>
<Field FieldName=“wszStatName” FieldValue=“_WA_Sys_00000007_693CA210” />
<Field FieldName=“wszColName” FieldValue=“LastName” />
<Field FieldName=“m_cCols” FieldValue=“1” />
<Field FieldName=“m_idIS” FieldValue=“2” />
<Field FieldName=“m_ullSnapShotModCtr” FieldValue=“19972” />
<Field FieldName=“m_ullRowCount” FieldValue=“19972” />
<Field FieldName=“ullThreshold” FieldValue=“4494” />
<Field FieldName=“wszReason” FieldValue=“heuristic” />
</ModTrackingInfo>
<ModTrackingInfo>
<Field FieldName=“wszStatName” FieldValue=“IX_Person_LastName_FirstName_MiddleName” />
<Field FieldName=“wszColName” FieldValue=“LastName” />
<Field FieldName=“m_cCols” FieldValue=“1” />
<Field FieldName=“m_idIS” FieldValue=“7” />
<Field FieldName=“m_ullSnapShotModCtr” FieldValue=“19972” />
<Field FieldName=“m_ullRowCount” FieldValue=“19972” />
<Field FieldName=“ullThreshold” FieldValue=“4494” />
<Field FieldName=“wszReason” FieldValue=“heuristic” />
</ModTrackingInfo>
Each ModTrackingInfo node displays the information about one statistics object that has been referenced. The wszStatName shows us the name of the Statistics object. We have two in this case, _WA_Sys_00000007_693CA210 and IX_Person_LastName_FirstName_MiddleName. The first is an auto-generated one on the LastName column (I happen to know this was generated before I created the index referenced). Interestingly SQL has looked at both – even though they contain pretty much the same info and one isn’t really required.
Why is this useful?
Well, apart from simply the interesting aspect of seeing some of what is going on in the background when SQL decides what plan to use for your query, it is often the case with poor performing queries that there is bad cardinality estimation going on. Sometimes this might be because the statistics aren’t accurate and would benefit from being updated. You can use this technique to see what statistics objects are being used for the estimation (where it is not just obvious) and then you can look at the objects themselves and see whether they might want refreshing.
I see growing opinion in the SQL world that the refreshing of statistics is often more important than rebuilding indexes to reduce fragmentation – the latter operation will also refresh the statistics but is a lot more resource intensive. You also will commonly have statistics on columns that are not indexed, and the threshold for them to be refreshed can be pretty large when you have a lot of data. You can see more information about manually refreshing statistics in my previous posts on the subject:
When do Distribution Statistics Get Updated?
Automatic Sample Sizes for Statistics Updates

![]()
