

In this post we will explore a common statistical term – Relative Risk, otherwise called Risk Factor. Relative Risk is a term that is important to understand when you are doing comparative studies of two groups that are different in some specific way. The most common usage of this is in drug testing – with one group that has been exposed to medication and one group that has not. Or , in comparison of two different medications with two groups with each exposed to a different one.
To understand better am going to use the same example that I briefly referenced in my earlier post.
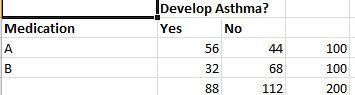
In this case the risk of a patient treated with Drug A developing asthma is 56/100 = 0.56. Risk of patient treated with drug B developing asthma is 32/100 = 0.32. So the relative risk is 0.56/0.32 which is 1.75. Absolute Risk, is another term which is the difference in probabilities of the two cases(0.56-0.32). There are some posts that argue that absolute risk should be used while comparing two medications and relative risk for one medication versus none at all but this is not a hard rule and there are many variations.
This wikipedia post has a great summary of relative risk – make sure to read the link they have on absolute risk also.
Now, applying relative risk to the problem we were trying to solve in the earlier post – we have two groups of data as below.
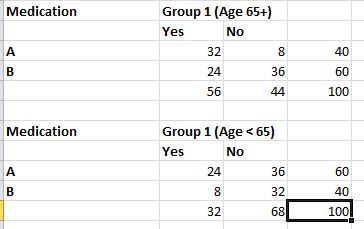
The relative risk in the first case is (32/40)/(24/60) = 2. In the second group it is (24/60)/(8/40) = 2. So logically when we combine(add) the two groups we should still get a relative risk of 2. But we get 1.75, as we saw with the first set of data above. The reason for that skew is because of the age factor, also called the confounding variable. We used the cochran-mantel test to mitigate the effect of the age factor to calculate x2 and pi value for the same data. We can use the same test to calculate relative risk by obscuring the age factor – the formula for doing this is as below (with due thanks to the text book on Introductory Applied Biostatistics.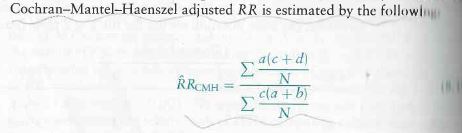
Using the formula on the data in T-SQL (you can find the dataset to use here) –
declare @Batch2DrugAYes numeric(18,2), @Batch2DrugANo numeric(18,2), @Batch2DrugBYes numeric(18, 2), @Batch2DrugBNo numeric(18, 2) declare @riskratio numeric(18, 2), @riskrationumerator numeric(18, 2), @riskratiodenom numeric(18,2 ) declare @totalcount numeric(18, 2) SELECT @totalcount = count(*) FROM [dbo].[DrugResponse] WHERE batch = 1 SELECT @Batch1DrugAYes = count(*) FROM [dbo].[DrugResponse] WHERE batch = 1 AND drug = 'A' AND response = 'Y' SELECT @Batch1DrugANo = count(*) FROM [dbo].[DrugResponse] WHERE batch = 1 AND drug = 'A' AND response = 'N' SELECT @Batch1DrugBYes = count(*) FROM [dbo].[DrugResponse] WHERE batch = 1 AND drug = 'B' AND response = 'Y' SELECT @Batch1DrugBNo = count(*) FROM [dbo].[DrugResponse] WHERE batch = 1 AND drug = 'B' AND response = 'N' SELECT @Batch2DrugAYes = count(*) FROM [dbo].[DrugResponse] WHERE batch = 2 AND drug = 'A' AND response = 'Y' SELECT @Batch2DrugANo = count(*) FROM [dbo].[DrugResponse] WHERE batch = 2 AND drug = 'A' AND response = 'N' SELECT @Batch2DrugBYes = count(*) FROM [dbo].[DrugResponse] WHERE batch = 2 AND drug = 'B' AND response = 'Y' SELECT @Batch2DrugBNo = count(*) FROM [dbo].[DrugResponse] WHERE batch = 2 AND drug = 'B' AND response = 'N' SELECT @riskrationumerator = (@Batch1DrugAYes*(@Batch1DrugBYes+@Batch1DrugBNo))/@totalcount SELECT @riskrationumerator = @riskrationumerator + (@Batch2DrugAYes*(@Batch2DrugBYes+@Batch2DrugBNo))/@totalcount SELECT @riskratiodenom = (@Batch1DrugBYes*(@Batch1DrugAYes+@Batch1DrugANo))/@totalcount SELECT @riskratiodenom = @riskratiodenom + (@Batch2DrugBYes*(@Batch2DrugAYes+@Batch2DrugANo))/@totalcount --SELECT @riskratiodenom --SELECT @riskrationumerator,@riskratiodenom SELECT 'Adjust Risk Ratio: ', @riskrationumerator/@riskratiodenom

We can write code in R to achieve above result – there is no in built function to do this as far as I can see. But when we can write simpler code in T-SQL I was not sure if it worth the trouble to do it for this particular case. We have at least one scenario we can do something easily in T-SQL that R does not seem to have built-in. I certainly enjoyed that feeling!! Thanks for reading.

![]()
