[read this post on Mr. Fox SQL blog]
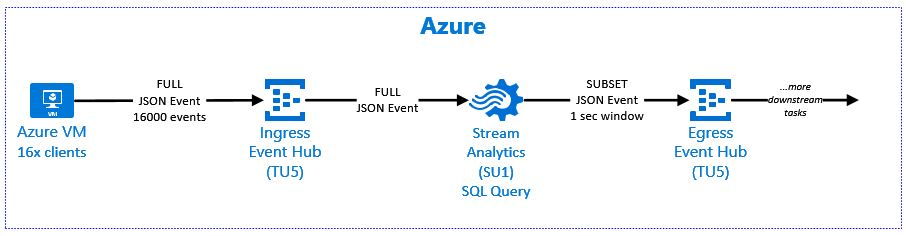
Recently I had a requirement to load streaming JSON data to provide a data feed for near real-time reporting. The solution streamed data into an “Ingress” Azure Event Hub, shred the JSON via Azure Stream Analytics and then push subsections of data as micro-batches (1 sec) into a “Egress” Azure Event Hub (for loading into a stage table in Azure SQL DW).
In Event Hubs and Stream Analytics there are only a few performance levers to help tune a solution like this, or said another way, doing nothing with these levers can affect your ongoing performance!
So this blog is to show the performance differences when using different Azure Event Hub partition configurations and the Azure Stream Analytics PARTITION BY clause.
Understanding the Environment Levers
When you configure Azure Event Hub you only have 2 levers;
- Throughput Units (TU) – TU’s apply to all event hubs in a namespace and are pre-purchased units of capacity between 1 and 20 (or more by contacting support). Each partition has a maximum scale of 1 TU. Each TU is 1MB/sec ingress + 2MB/sec egress + 84GB event storage. For our test we wont change TU
- Partitions – The number of partitions is specified at creation and must be between 2 and 32. The partition count is not changeable. Partitions are a data organization mechanism that relates to the downstream parallelism required when consuming data.
- You can learn more about Event Hubs here – https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-what-is-event-hubs
When you configure Azure Stream Analytics you only have 2 levers;
- Streaming Units (SU) – Each SU is a blend of compute, memory and throughput between 1 and 48 (or more by contacting support). The factors that impact SU are query complexity, latency, and volume of data. SU can be used to scale out a job to achieve higher throughput. Depending on query complexity and throughput required, more SU units may be necessary to achieve your performance requirements. A level of SU6 assigns an entire Stream Analytics node. For our test we wont change SU
- SQL Query Design – Queries are expressed in a SQL-like query language. These queries are documented in the query language reference guide and includes several common query patterns. The design of the query can greatly affect the job throughput, in particular if and/or how the PARTITION BY clause is used.
- You can learn more about Stream Analytics here – https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-introduction
Test Patterns and Scenarios
When running streaming solutions its important to aim to get maximum parallelism whch allows the greatest throughput.
I’m going to keep it simple and verify the difference between running ingress and egress Event Hub with different partition settings, and combine a Stream Analytics SQL query design using the PARTITION BY clause.
| TEST | INPUT [Ingress AEH] | QUERY [ASA] | OUTPUT [Egress AEH] | |||
| TU | Partitions | SU | SQL Query | TU | Partitions | |
| 1 | 5 | 2 | 1 | NONE | 5 | 16 |
| 2 | 5 | 2 | 1 | PARTITION BY | 5 | 16 |
| 3 | 5 | 16 | 1 | NONE | 5 | 2 |
| 4 | 5 | 16 | 1 | PARTITION BY | 5 | 2 |
| 5 | 5 | 2 | 1 | NONE | 5 | 2 |
| 6 | 5 | 2 | 1 | PARTITION BY | 5 | 2 |
| 7 | 5 | 16 | 1 | NONE | 5 | 16 |
| 8 | 5 | 16 | 1 | PARTITION BY | 5 | 16 |
Test Workload Configuration
The particulars of the test workload are as follows;
- Each test will send 16000 events using 16 clients/threads with no wait time between each send event.
- The JSON event is 88 bytes, and is shown below. Each event will have an incremental event id, a random deviceId (1-10) and random value (1-1000000).
- The events are not compressed
- Each client will send data without using a partition key (ie round robin will allocate the incoming events into the Ingress Event Hub partitions).
- The send clients will run from a DS13-4_v2 (4 v-cpus, 56 GB memory) Azure VM to minimise latency.
- The VM is running in Australia South East.
- The Event Hubs and Stream Analytics services are running in Australia South East.
- Stream Analytics will run at SU1 (just so its easy to observe SU% differences)
- Event Hub will run at TU5 (Igress Hub & Egress hub share the same namespace)
- The ASA SQL query will perform a relatively complex aggregate tumbling window
- I will use the awesomely cool Service Bus Explorer to send the events. In case you haven’t seen it before, then strongly recommend to check it out – https://code.msdn.microsoft.com/windowsapps/Service-Bus-Explorer-f2abca5a
- The tests will measure the SU% and the elapsed sec (first event sent [from the client] to last event received [in the event hub]).

Test JSON Event Message
{
"eventId":#####,
"deviceId":##,
"value":#######,
"timestamp":"####-##-##T##:##:##.#######Z"
}
Test Stream Analytics Query
My ASA SQL query below can use a “parallel” input step from the ingress event hub, but I needed an aggregated output step to load into the egress event hub. I know I cannot achieve “maximum” parallelism for the query, however I wanted to identify if there are still observable performance benefits in this configuration.
For each test I will change the ASA SQL Query as follows…
- Add / remove the “PARTITION BY” clause
- Swap the pointers for “aAEHIngress##” and “aAEHEgress##” Event Hubs. I have pre-configured several event hubs with either 2 or 16 partitions, so I can just swap the pointers around and rerun the query again!
WITH Step1 AS
(
SELECT
PartitionId,
deviceId,
COUNT(deviceId) as TOTRows,
SUM(value) as SUMValue,
AVG(value) as AVGValue,
MIN(value) as MINValue,
MAX(value) as MAXValue
FROM
[aAEHIngress##] --PARTITION BY PartitionId
GROUP BY
PartitionId,
deviceId,
TumblingWindow(second, 1)
)
SELECT deviceId,
SUM(TOTRows) as TOTRows,
SUM(SUMValue) as SUMValue,
AVG(AVGValue) as AVGValue,
MIN(MINValue) as MINValue,
MAX(MAXValue) as MAXValue
INTO
[aAEHEgress##]
FROM
Step1
GROUP BY
deviceId,
TumblingWindow(second, 1)
If you are interested in other common ASA queries then check out the patterns here – https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-stream-analytics-query-patterns
Test Results/Outcomes
And so the results are in!
| # | Test Type | Total Events Sent | Avg Event Send Rate / Sec | Elapsed (sec) | ASA |
| SU % | |||||
| 1 | 2:16:N | 16000 | 201 | 84 | 9 |
| 2 | 2:16:P | 16000 | 202 | 83 | 9 |
| 3 | 16:2:N | 16000 | 174 | 102 | 11 |
| 4 | 16:2:P | 16000 | 167 | 108 | 14 |
| 5 | 2:2:N | 16000 | 198 | 85 | 10 |
| 6 | 2:2:P | 16000 | 200 | 83 | 9 |
| 7 | 16:16:N | 16000 | 183 | 90 | 11 |
| 8 | 16:16:P | 16000 | 183 | 98 | 14 |
Key Observations of this Test Workload
Given the above tests and observed results, you could conclude that…
- Mismatching ingress and egress partitions can negatively affect performance specifically when the ingress partitions is higher than the egress partitions (ie the IN pipe is bigger than the OUT pipe). My test showed as much as a 20% difference in elapsed time. This also results in a 30% higher SU% utilisation.
- Mismatching egress and ingress partitions does not seem to negatively affect performance when the egress partitions are higher than the ingress partitions (ie the IN pipe is smaller than the OUT pipe). My test shows the elapsed times and SU% are about the same, which kind of makes sense.
- Matching ingress and egress partitions can positively affect performance, however when higher partitions are used (16 partitions) there seems to be a degree of overhead to process data through the solution, as is shown by lower send rate, and higher SU%. This could be related to send overhead at the client – I note that MS DOCS states 4 partitions is “generally enough” for most solutions. Probably needs further investigation and retesting at 4 or 8 partitions…
- There was only a very small benefit from using the PARTITION BY in my specific ASA Query. Some performed better by a few seconds, and others worse. Its probably not enough to call it as beneficial or not. As above I suspected this may occur as my ASA SQL query needed 2 steps; the 1st could be partitioned, however the 2nd couldn’t be partitioned (GROUP BY without partition id).
Summary
So there you have it, a pretty simple breakdown of how the different partition sizes in Azure Event Hubs and partition by clasue in Azure Stream Anaytics can change the performance!
My test was focused on my specific needs in my specific scenario; the outcomes will differ depending on the (a) SQL query, (b) the type/size of the event payload, (c) the number of clients sending data into the ingress event hub, and (d) if those clients send to a specific partition or use round robin. Ideally if I had time it would be great to rerun this using a workload of a few million events over a few hundred clients!
So as usual, and as I always say, please test this out yourself with your own solution, data and event stream as your milage may vary!
References
There’s some exceptional MS DOCS articles I recommend that you review and validate the fit within your own streaming data solutions.
- Understanding ASA SU – https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-streaming-unit-consumption
- Leverage Query Parallelism – https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-parallelization
- Scale Stream Analytics Jobs – https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-scale-jobs
Disclaimer: all content on Mr. Fox SQL blog is subject to the disclaimer found here