

I actually saw the above statement posted online. The person making the claim further stated that choosing between these three constructs was “personal preference” and didn’t change at all the way SQL Server would choose to deal with them in a query.

Let’s immediately say, right up front, the title is wrong. Yes, there are very distinct differences between these three constructs. Yes, SQL Server will absolutely deal with these three constructs in different ways. No, picking which one is correct in a given situation is not about personal preference, but rather about the differences in behavior between the three.
To illustrate just a few of the differences between these three constructs, I’ll use variations of this query:
SELECT * FROM Sales.Orders AS o JOIN Sales.OrderLines AS ol ON ol.OrderID = o.OrderID WHERE ol.StockItemID = 227;
The execution plan for this query looks like this:
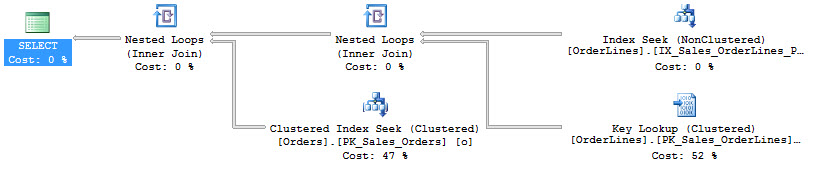
The number of reads is 1,269 and the duration is around 234ms on average.
Let’s modify the query to use a table variable. Note, I do include a primary key with the table variable which can be used by the optimizer to make decisions based on unique values.
DECLARE @OrderLines TABLE
(OrderLineID INT NOT NULL PRIMARY KEY,
OrderID INT NOT NULL,
StockItemID INT NOT NULL,
Description NVARCHAR(100) NOT NULL,
PackageTypeID INT NOT NULL,
Quantity INT NOT NULL,
UnitPrice DECIMAL(18,2) NULL,
TaxRate DECIMAL(18,3) NOT NULL,
PickedQuantity INT NOT NULL,
PickingCompletedWhen DATETIME2 NULL,
LastEditedBy INT NOT NULL,
LastEditedWhen DATETIME2 NOT NULL);
INSERT @OrderLines
(OrderLineID,
OrderID,
StockItemID,
Description,
PackageTypeID,
Quantity,
UnitPrice,
TaxRate,
PickedQuantity,
PickingCompletedWhen,
LastEditedBy,
LastEditedWhen
)
SELECT *
FROM Sales.OrderLines AS ol
WHERE ol.StockItemID = 227;
SELECT * FROM Sales.Orders AS o
JOIN @OrderLines AS ol
ON ol.OrderID = o.OrderID
WHERE ol.StockItemID = 227;I’m not concerned with how long it takes the data to load, only the behavior of the query after I load the data. Here’s the execution plan:
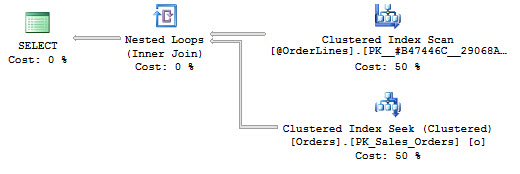
Not much to say. Clearly it’s different from the regular query, but that shouldn’t be a shock since we’re dealing with different tables. Overall the number of reads goes to 1508 because we’re messing with data twice and performance for the whole process is about 260ms. Breaking it down by statement within the batch, so that we can get a very fair comparison, the active part of the query we’re concerned with, the JOIN between the table and the table variable, runs in about 250ms and has only 356 reads.
Modifying the query again for temporary tables, it looks like this:
CREATE TABLE #OrderLines
(OrderLineID INT NOT NULL PRIMARY KEY,
OrderID INT NOT NULL,
StockItemID INT NOT NULL,
Description NVARCHAR(100) NOT NULL,
PackageTypeID INT NOT NULL,
Quantity INT NOT NULL,
UnitPrice DECIMAL(18,2) NULL,
TaxRate DECIMAL(18,3) NOT NULL,
PickedQuantity INT NOT NULL,
PickingCompletedWhen DATETIME2 NULL,
LastEditedBy INT NOT NULL,
LastEditedWhen DATETIME2 NOT NULL);
INSERT #OrderLines
(OrderLineID,
OrderID,
StockItemID,
Description,
PackageTypeID,
Quantity,
UnitPrice,
TaxRate,
PickedQuantity,
PickingCompletedWhen,
LastEditedBy,
LastEditedWhen
)
SELECT * FROM Sales.OrderLines AS ol
WHERE ol.StockItemID = 227;
SELECT * FROM Sales.Orders AS o
JOIN #OrderLines AS ol
ON ol.OrderID = o.OrderID
WHERE ol.StockItemID = 227;
DROP TABLE #OrderLines;The new execution plan looks like this:
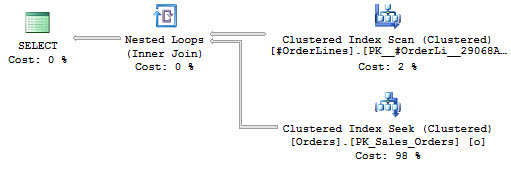
Don’t go getting all excited. I recognize that these two plans look similar, but they are different. First, let me point out that we have more reads with 1546 and an increase in duration to 273ms. This comes from two places. First, we’re creating statistics on the data in the temporary table where none exist on the table variable. Second, because I want to run this script over and over, I’m including the DROP TABLE statement, which is adding overhead that I wouldn’t see if I treated it like the table variable (which I could, but not here). However, breaking down the to the statement level, I get 250ms duration, just like with the table variable, but, I see 924 reads.
What’s going on?
Note first the estimated costs between the two exec plans, 50/50 for the query with the table variable and 2/98 for the temporary table. Why? Well, let’s compare the two plans (and yeah, I LOVE the new SSMS plan compare functionality). Specifically, let’s look at each Clustered Index Scan operation. There are a number of differences, but the most telling is right here:

On the left is the temporary table. On the right is the table variable. Note the TableCardinality values. The table variable shows zero because there are no statistics, despite the table created having a primary key. In this case, it doesn’t make an appreciable difference in behavior from a pure performance standpoint (250ms to 250ms), but you can clearly see differences in behavior.
Oh, and the CTE? It had the same execution plan as the original query because a CTE is not a table, it’s an expression.
In short, yes, there are very distinct differences in behavior between a table variable, a temporary table, and a common table expression. These are not constructs that are interchangeable on a whim. You need to understand what each does in order to use each appropriately.
Next week I’ll be doing talking about execution plans and query tuning at an all day pre-con at SQLServer Geeks Annual Summit in Bangalore India.
Don’t miss your chance to an all day training course on execution plans before SQL Saturday Oslo in September.
The post There Is No Difference Between Table Variables, Temporary Tables and Common Table Expressions appeared first on Home Of The Scary DBA.
![]()
