

Earlier today, I had a great Twitter conversation with Tim Mitchell (@Tim_Mitchell), Jorge Segarra (@SQLChicken), and Jack Corbett (@unclebiguns) about the use of DISTINCT in a SQL Server query. By the way, this is yet another example of how Twitter can be used in a good and positive way within the work environment and within the SQL Server Community; Twitter is not just a time sink that squeezes productivity out of your day as some claim.
Many people (not those mentioned previously) resort to using the DISTINCT keyword in a SELECT statement to remove duplicates returned by a query. The fact that the resultset has duplicates is frequently (though not always) the result of a poor database design, an ineffective query, or both. In any case, issuing the query without the DISTINCT keyword yields more rows than expected or needed so the keyword is employed to limit what is returned to the user.
So what’s the problem? Is using DISTINCT that really bad? Why not just type the 9 additional keystrokes that will save us a lot of hard work? (8 letters and a space. You thought I miscounted, didn’t you?)
Running without the DISTINCT keyword
To answer that question, let’s have a look at a quick and simple example. Let’s consider the following query run against the AdventureWorks database.

As you can see from the query and its execution plan above, SQL Server resolves this query using a Clustered Index Scan, aka a table scan. Generally speaking, table scans are not something you want to see in your query plans but in this case it makes sense. I’m asking for 4 columns from all rows in the table.
Now let’s look at the cost of the subtree below. We see that the estimated subtree cost for the SELECT statement is 0.438585.

Looking at the execution time information from SET STATISTICS TIME ON we see the following information.
SQL Server Execution Times:
CPU time = 15 ms, elapsed time = 586 ms.
Running with the DISTINCT keyword
Now, let’s type those 9 additional keystrokes, adding the DISTINCT keyword into the query as shown below. Before we run this, we’ll clear out our buffers and procedure cache to make sure we’re comparing apples to apples.
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE
NOTE: Do not run the aforementioned DBCC commands on a production server. If you do, your phone will ring, your pager will go vibrate, your users will have a hard time forgiving you, and performance will slow to a crawl for a little while.

A quick examination of the query plan reveals that a table scan is still being used to retrieve the data from the table. That’s to be expected. However, a new node has been added to the plan. A Sort node. This node is responsible for 75% of the total cost of the new query!
Looking at the node cost for the SELECT statement, we see that the cost shot up to 1.75954 from 0.438585. That’s a significant difference.

And finally comparing the time it took to resolve this query with the prior version, we can see that the total CPU time increased too.
SQL Server Execution Times:
CPU time = 78 ms, elapsed time = 655 ms.
An exception to every rule
So, generally speaking the addition of DISTINCT to a SELECT statement will increase the workload for SQL Server. But this is not always the case. If a unique index exists that can guarantee that each row will indeed be distinct, the Sort operation can be skipped and the results immediately returned.
For example, consider the following trivial query as an example.
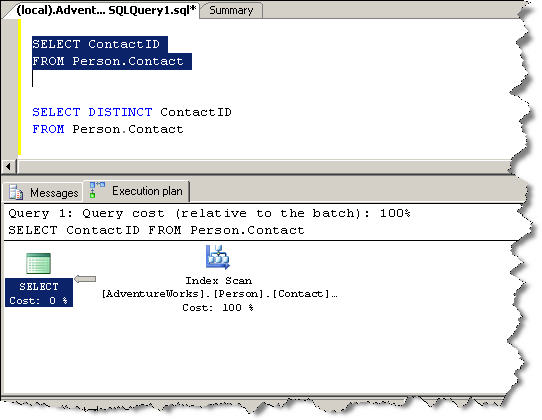
And compare it to the following query that includes the DISTINCT keyword.
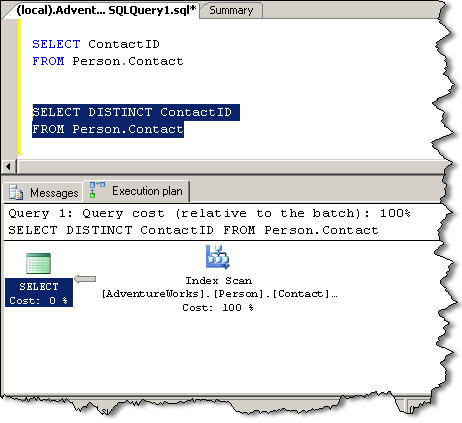
Notice that the query plans are identical for these two queries. Why? A unique index exists on the ContactID column which guarantees that the rows will be distinct.
But wait, there’s more
These are really trivial examples of how DISTINCT can make a difference in a query plan and thus the performance of a query. In real life, very few queries are this simple. But I hope that these examples will serve to illustrate that DISTINCT does add an addtional load on the SQL Server. So, if you can do a little work up front by rewriting your query, you can avoid having use DISTINCT in your query. SQL Server will thank you for it.
For more information how a unique index can help performance, have a look at Rob Farley’s blog post entitled “Unique Indexes with GROUP BY“. It’s a good read.
Have you resorted to using DISTINCT to limit the results of a query? I’d love to hear of your experiences. Or if you’ve found an better alternative, please share.
Joe







