

In case you don’t know, this query:
UPDATE dbo.Test1 SET C2 = 2 WHERE C1 LIKE '%33%';
Will run quite a bit slower than this query:
UPDATE dbo.Test1 SET C2 = 1 WHERE C1 LIKE '333%';
Or this one:
UPDATE dbo.Test1 SET C2 = 1 WHERE C1 = '333';
That’s because the second two queries have arguments in the filter criteria that allow SQL Server to use the statistics in an index to look for specific matching values and then use the balanced tree, B-Tree, of the index to retrieve specific rows. The argument in the first query requires a full scan against the index because there is no way to know what values might match or any path through the index to simply retrieve them.
But, what if we do this:
UPDATE dbo.test1 SET C2 = CASE WHEN C1 LIKE '19%' THEN 3 WHEN C1 LIKE '25%' THEN 2 WHEN C1 LIKE '37%' THEN 1 END;
We’re avoiding that nasty wild card search, right? So the optimizer should just be able to immediately find those values and retrieve them… Whoa! Hold up there pardner. Let’s set up a full test:
IF (SELECT OBJECT_ID('Test1')
) IS NOT NULL
DROP TABLE dbo.Test1;
GO
CREATE TABLE dbo.Test1 (C1 VARCHAR(50),C2 INT, C3 INT IDENTITY);
SELECT TOP 1500
IDENTITY( INT,1,1 ) AS n
INTO #Nums
FROM Master.dbo.SysColumns sC1,
Master.dbo.SysColumns sC2;
INSERT INTO dbo.Test1
(C1,C2)
SELECT n, n
FROM #Nums;
DROP TABLE #Nums;
CREATE CLUSTERED INDEX i1 ON dbo.Test1 (C1) ;
UPDATE dbo.test1
SET C2 =
CASE
WHEN C1 LIKE '%42%' THEN 3
WHEN C1 LIKE '%24%' THEN 2
WHEN C1 LIKE '%36%' THEN 1
END
DBCC FREEPROCCACHE()
UPDATE dbo.test1
SET C2 =
CASE
WHEN C1 LIKE '19%' THEN 33
WHEN C1 LIKE '25%' THEN 222
WHEN C1 LIKE '37%' THEN 11
WHEN C1 LIKE '22%' THEN 5
ENDI added the extra CASE evaluation in the second query in order to get a different query hash value.
Here are the execution plans from the two queries:
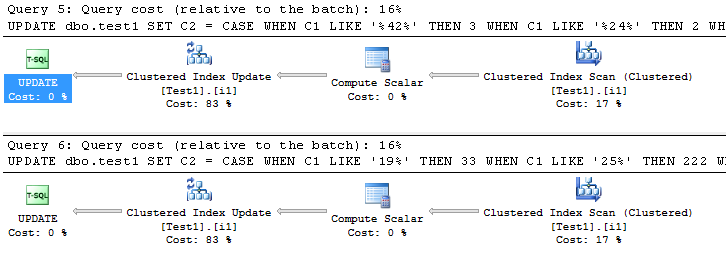
They’re pretty identical. Well, except for me forcing a difference in the hash values, they’re identical except for the details in the Compute Scalar operator. So what’s going on? Shouldn’t that second query use the index to retrieve the values? After all, it avoided that nasty comparison operator, right? Well, yes, but… we introduced a function on the columns. What function you ask? The CASE statement itself.
This means you can’t use a CASE statement in this manner because it does result in bypassing the index and statistics in the same way as using functions against the columns do.
The post The CASE Statement and Performance appeared first on Home Of The Scary DBA.
![]()
