

 Hello Dear Reader! This post finds me back in Boston getting ready for the Pragmatic Works Performance Tuning Workshop. But that is not the reason for the blog. You see today is T-SQL Tuesday! T-SQL Tuesday is the brain child of Adam Machanic (@AdamMachanic | Blog). The idea is once a month we the SQL Community have a blog party where someone hosts a topic and we all write. This month the host is none other than the Rob Farley (@Rob_Farley | Blog). So without further ado, Rob what is our topic?
Hello Dear Reader! This post finds me back in Boston getting ready for the Pragmatic Works Performance Tuning Workshop. But that is not the reason for the blog. You see today is T-SQL Tuesday! T-SQL Tuesday is the brain child of Adam Machanic (@AdamMachanic | Blog). The idea is once a month we the SQL Community have a blog party where someone hosts a topic and we all write. This month the host is none other than the Rob Farley (@Rob_Farley | Blog). So without further ado, Rob what is our topic?“The topic is Plan Operators. If you ever write T-SQL, you will almost certainly have looked at execution plans (if you haven’t, go look at some now. I mean really – you should be looking at this stuff). As you look at these things, you will almost certainly have had your interest piqued by some, and tried to figure out a bit more about what’s going on.”
So Plan Operators it is!
“So Balls”, you say, “What will you write about today?”
Excellent question Dear Reader! Adam did a fantastic 3 hours presentation on parallelism this past year at the PASS Summit. One of the biggest things I learned to watch was the Repartition Streams operator to see how rows were distributed across multiple cores. It was a nice AHA moment for me, and I wanted to pass it along to you!
CROSSING THE STREAMS

The operator itself is purely logical and is only ever used in parallel plans. When it happens you know that an operation is occurring that requires a Consumer and a Producer Thread. The producer thread reads input rows from its subtree, assembles the rows into packets, which are then placed in the consumer subtree. The Repartition Streams operator is a push operator that consumes multiple streams of records. The format of the records is unchanged as well as the contents. By using this model it allows the producer and consumer threads to execute independently, but worry not there is flow control to prevent a fast producer from flooding a consumer with excessive packets.

In parallelism you use multiple cores to achieve more. If you notice a bitmap filter after a Repatriation Streams operator, that means the number of rows in the output is going to be reduced. You will notice changes in the Argument column if your table is partitioned or if the output is ordered.
SQL Server supports 5 different ways that producers stream results to consumers. Broadcast, Demand, Hash, Range, and Round Robin. These different streams partitions the data across the threads.
Broadcast sends all rows to all consumer threads. Demandis normally used with partitioned tables and is the only type of exchange that uses a pull rather than a push. Hash evaluates a hash function to determine where to send rows using one or more columns from a row. Rangeuses a range function on one column in the row to determine where to send each packet, this type is rare. Round Robin this alternates sending packets of rows to the next consumer thread waiting in a sequence.
We’ve discussed it now we’ll actually take a look at a parallel query and how the repartition is being used. Let’s start out with a query. I’ve got a large table in my Adventure works that I’ll be blogging about very soon, more on that later. Today I’m using it as the basis for my query. We’re going to do a simple aggregate.
set statistics profile on
select
p.EnglishProductName
,sum(salesAmount) as ProductSales
,avg(unitprice) as avgUnitPrice
,count(OrderQuantity) totalProductsSold
from
dbo.factinternetsales_big fb
inner join dbo.dimproduct p
on fb.ProductKey=p.ProductKey
group by p.EnglishProductName
Option (MAXDOP 4)
The goal here is to select enough data that SQL Server will produce a plan that will push the cost to a parallel plan, and in doing so will read in data using multiple threads. In this case we will get two repartition streams operators in our statements. Let’s start off looking at the query plan. We’ll also get the output of the set statistics profile on, but we’ll cover that in a minute.

Great so we’ve got our query plan. The icon doesn’t tell us much in and of itself. When you click on it and hover over it we get a little more information.
We see that we pulled back over 10.5 Million rows, We see the Partitioning Type is Hash, and that our estimated subtree cost was high enough for us to get a parallel plan. The trick is to hit F4 while you have selected to get even more information.
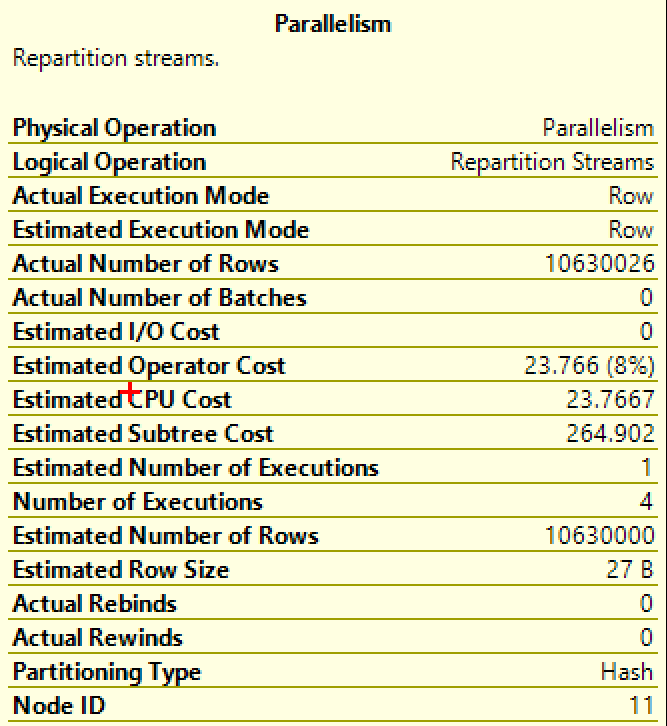
F4 opens the Properties tab. In my laptop I’ve got one CPU, two cores, and Hyperthreading is turned on. So I should see a total of 5 active Threads. Threads 0 – 4. Thread 0 will always have 0 rows associated with it. The reason for this is because Thread 0 is a control node. It is overseeing all the work on the individual threads.
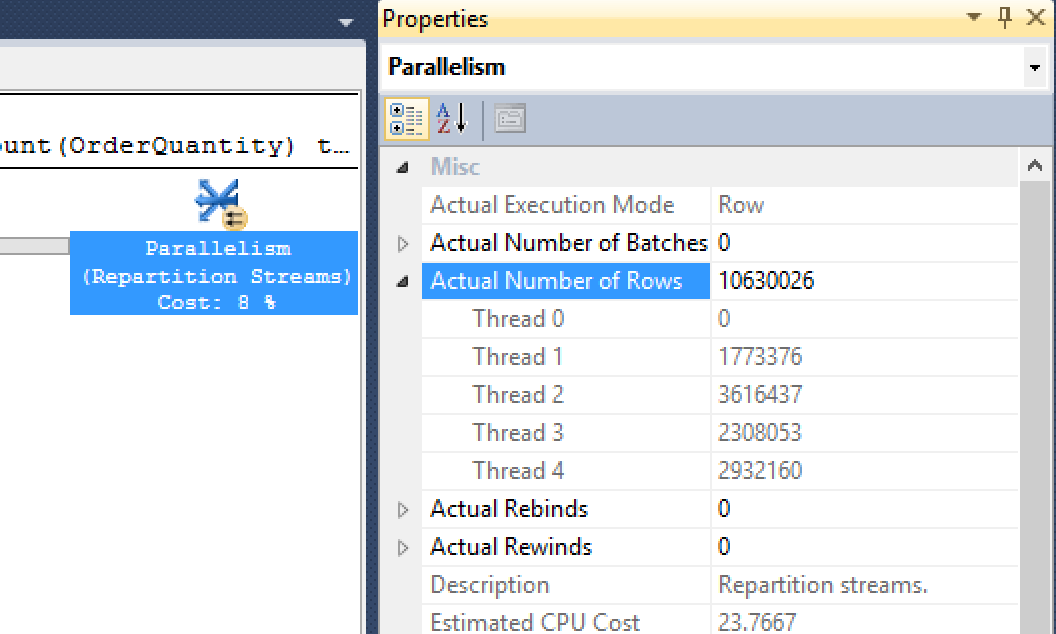
By expanding the Actual Number of Rows we can see that this was somewhat evenly distributed. Thread 0 is our control Thread so it should be sitting at 0 rows. Thread 1 had only 1.7 million rows, Thread 2 had 3.6 Million, Thread 3 had 2.3 million, and Thread 4 had 2.9 million.
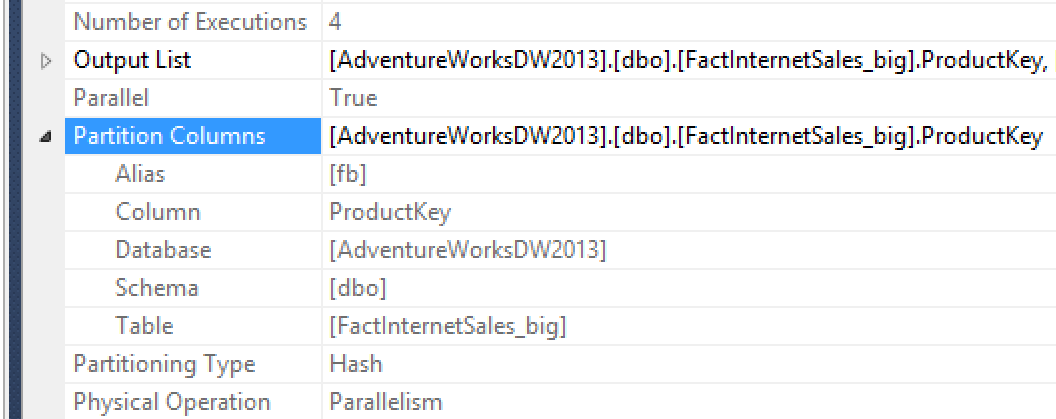
We can see there was a skew, based on the hash. Looking further down at our properties we can see that this was a hash partition, confirmed from our graphical portion of the plan, but we can see the hash key was on the ProductKey column. This was done as we were gathering data to prepare for our join.
Looking at the output from the set statistics profile on we can see the same information to validate the type of repartition that we had.

Examining the output even further you will see a second Repartition of the Streams, also using a Hash Partition based on the EnglishProductName (because that’s what we grouped on in our T-SQL Query). If you use F4 to look at the properties you’ll see we’ve greatly reduced the number of columns in by the time we get to this part of the plan.
So what does this all mean? Sometimes Parallelism messes up. Sometimes we do not get an even breakdown of rows across threads. When this occurs we can take steps to address it. Adam cover’s this in depth in his presentation, and I’ll have to cover this another day Dear Reader, because the plane is about to board, and I’m Boston bound! But now you know where to look to find out how your rows are being partitioned when they are parallelized!
As always Thanks for stopping by!
Thanks,
Brad
