

You are working on a database development project, and you need to obtain the records before/after an INSERT, DELETE, UPGRADE or MERGE Statement to present it to the user or do any work with that data.
A common approach that I see a lot and involves a lot of code to obtain the before/after information can be the following (maybe some IF and TRY...CATCH also) :
DECLARE @id INT = 1;
SELECT PostalCode
, ModifiedDate
FROM Person.Address a
WHERE a.AddressID = @id;
UPDATE Person.Address
SET PostalCode = 95012,
ModifiedDate = 'Jan 02 2020'
WHERE AddressID = @id;
SELECT PostalCode
, ModifiedDate
FROM Person.Address a
WHERE a.AddressID = @id;
The results will be something like this (before and after):

And the execution plan will look like this, each extra SELECT statement adds more workload to our server (independently of the resources used) :

Even when the code is easy to read, but if you use this pattern over all your codebase, maintain it can become difficult if you have to change object names or implement it on another system.
T-SQL language provides the OUTPUT clause, that allows you to retrieve information from a DML statement in the same batch.
NOTE: OUTPUT clause will return rows even when the statement presents an error and is rolled back, so you should not use the results if any error is encountered.
Sample usage is as follows:
-- Values After INSERT INTO --
INSERT INTO <MyTable>
OUTPUT INSERTED.*
VALUES (@a, @b);
-- Values After INSERT FROM --
INSERT INTO <MyTable>
OUTPUT INSERTED.*
SELECT * FROM <MyOtherTable>;
-- Values Before/After UPDATE --
UPDATE <MyTable>
SET <myField> = @value
OUTPUT
DELETED.<myField> as [ValueBefore],
INSERTED.<myField> as [ValueAfter]
WHERE id = @key;
-- Deleted records After a DELETE --
DELETE <MyTable>
OUTPUT DELETED.*
WHERE id = @key;
If we refactor the first example to use OUTPUT we obtain this code:
DECLARE @id INT = 1
UPDATE Person.Address
SET PostalCode = 95012,
ModifiedDate = 'Jan 02 2020'
OUTPUT
DELETED.PostalCode,
DELETED.ModifiedDate,
INSERTED.PostalCode,
INSERTED.ModifiedDate
WHERE AddressID = @id
Less code and also easy to follow and maintain, and the results will be something like this:

What if we take a look at the execution plan? we can see that this time just one sentence is executed (as expected):
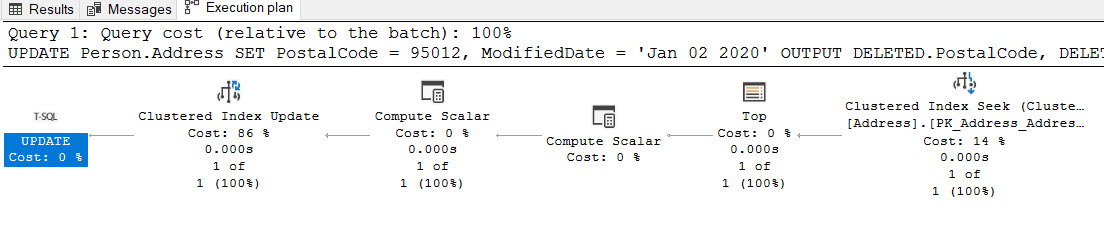
Of course, performance can vary depending on how many rows are you retrieving back to the user, current workload, index and table design that is very own to your environment, but the more you know, the better you can adapt each situation to achieve the optimal performance.
Speaking of which, what if we have a lot of fields or records to work with, it is possible to store the output results on another table? of course, you can, as we can see in this other example:
-- To review the correct data has been deleted
-- we can output to a temp table
DELETE
FROM Person1
OUTPUT DELETED.*
INTO PersonBackupInfo
WHERE EmailPromotion = 0;
-- we can review/recover data if needed
SELECT *
FROM PersonBackupInfo;
We can implement a deleted data review/rollback logic to our application to protect it from user errors (the typical Ooops queries) and protect our databases from an unnecessary point in time restores.
Like everything in life, nothing is perfect, and there are some remarks you should consider to implement it on your applications, so be sure to read it before using it.